Best Practices for Deploying and Scaling Industrial AI
Artificial Intelligence (AI) is transforming industrial operations, helping organizations optimize workflows, reduce downtime, and enhance productivity. Different industry verticals leverage AI in unique ways.
Accelerating Manufacturing Digital Transformation with Industrial Connectivity and IoT
Digital transformation is empowering industrial organizations to deliver sustainable innovation, disruption-proof products and services, and continuous operational improvement.
Leading a transportation revolution in autonomous, electric, shared mobility and connectivity with the next generation of design and development tools.
As businesses become data-driven and rely more heavily on analytics to operate, getting high-quality, trusted data to the right data user at the right time is essential.
The goal of automated integration is to enable applications and systems that were built separately to easily share data and work together, resulting in new capabilities and efficiencies that cut costs, uncover insights, and much more.
Digital transformation requires continuous intelligence (CI). Today’s digital businesses are leveraging this new category of software which includes real-time analytics and insights from a single, cloud-native platform across multiple use cases to speed decision-making, and drive world-class customer experiences.
Best Practices for Deploying and Scaling Industrial AI
Artificial Intelligence (AI) is transforming industrial operations, helping organizations optimize workflows, reduce downtime, and enhance productivity. Different industry verticals leverage AI in unique ways.
Accelerating Manufacturing Digital Transformation with Industrial Connectivity and IoT
Digital transformation is empowering industrial organizations to deliver sustainable innovation, disruption-proof products and services, and continuous operational improvement.
Leading a transportation revolution in autonomous, electric, shared mobility and connectivity with the next generation of design and development tools.
As businesses become data-driven and rely more heavily on analytics to operate, getting high-quality, trusted data to the right data user at the right time is essential.
The goal of automated integration is to enable applications and systems that were built separately to easily share data and work together, resulting in new capabilities and efficiencies that cut costs, uncover insights, and much more.
Digital transformation requires continuous intelligence (CI). Today’s digital businesses are leveraging this new category of software which includes real-time analytics and insights from a single, cloud-native platform across multiple use cases to speed decision-making, and drive world-class customer experiences.
Architecting for Data in Motion: Gone Are the Days of Data at Rest
The concept of “data in motion” is transforming the way organizations think about their technology stack and will determine which organizations can actually execute on AI and which are left drowning in endless streams of data.
Remember when enterprise applications used to treat data like filing cabinets, static and organized? Businesses used to operate under assumptions around “data at rest” – data that lives in a database or data lake waiting for business analysts to pull and analyze when needed.
Well, those days are long gone.
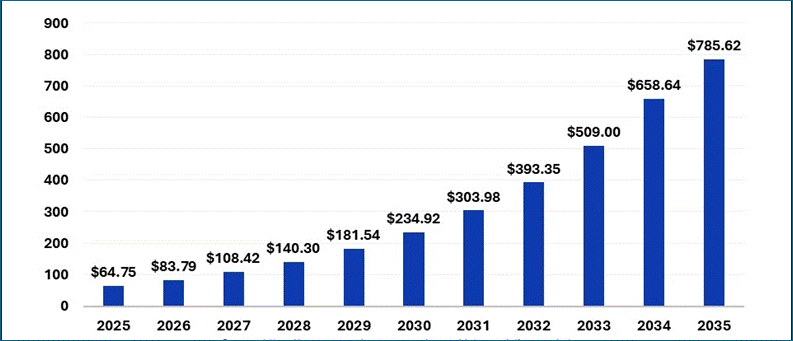
Accelerating storage demands alone paint a picture of the seismic shift taking place. According to Precedence Research, the data analytics market is expected to grow from almost $84 billion in 2026 to over $785 billion in 2035, and unless companies rearchitect how they approach data pipelines, they will experience bottlenecks, vendor lock-in, or worse – stalled business innovation and machine learning adoption.
Enterprises across industries are starting to realize that their biggest data hurdle is no longer how to store it, but how to move it. The concept of “data in motion” is transforming the way organizations think about their technology stack and will determine which organizations can actually execute on AI and which are left drowning in endless streams of data.
Figure 1: Global Data Analytics Market Size 2025-2035.
Three Reasons Enterprises are Shifting from Data at Rest to Data in Motion
1. Everything is moving, particularly with AI
What makes this shift revolutionary? Let’s look back just five years. Data lakes and databases were seen as the answer to large data problems. Batch processing data into those storage solutions was enough. Applications pushed data, and business analysts pulled it out and worked with it.
Don’t get me wrong, enterprises still need to store massive amounts of data. In fact, the need to store data will likely grow exponentially. With organizations shifting to hybrid, multi-cloud environments by default, we’ll see innovation at every layer around how to collect, store, and protect data. The difference now is that you also need to move it like never before.
Applications today need constant feeds of data to function. Solutions need to communicate with other apps and processes in real-time, generating petabytes of data in motion on a daily basis. Plus, AI and machine learning are destroying pre-existing notions of how data flows through organizations.
But it’s not just about volume. While enterprises now generate data measured in semi-truck loads, as AWS puts it, they also need to orchestrate the seamless movement of data between cloud providers, observability platforms, data analytics engines, and AI/ML frameworks.
If you don’t architect your telemetry pipelines right, you’ll be stuck paying inflated cloud prices while your competitors streamline data flows between cloud providers, applications, and AI systems. AI as a Service won’t solve your data movement problems. In fact, many of these systems require you to move even more data to their platforms to train AI models. Preparing for AI means transforming your infrastructure so that your systems can handle the rapid velocity of data in motion. AI systems don’t learn from just a snapshot of your data – they need constant streams of high-quality data from across your infrastructure.
With Gartner expecting 80% of enterprises to implement some type of generative AI mechanisms by 2026, preparing for AI isn’t optional. If your organization plans to adopt AI and machine learning systems, you need to start preparing for how those tools will ingest data. And that preparation starts with building the infrastructure to support your AI goals – beginning with data pipelines.
2. Multi-cloud isn’t going anywhere, and it’s costly without the right approach
The reality is that most businesses know they have a problem when it comes to data movement. For some, it’s ballooning cloud bills due to redundant data being moved between platforms. For others, it’s data science projects taking months because your ETL pipeline can’t get data into a usable format fast enough. A lot of businesses simply accept these setbacks as the cost of doing business in the cloud. They don’t have to.
Imagine paying to ship empty boxes from one side of the country to another. Companies are essentially doing this when they don’t have control over their data pipelines. Moving data from one cloud provider to the next is cumbersome. Providers have different data formats they’ll accept. Different APIs. Different connectors. Each time you move data, you pay to do it. And the ecosystem is growing, with the global multi-cloud networking market projected to have reached $7.43 billion in 2025 and expected to grow to $49.29 billion by 2034.
Data movement is hard, and organizations are spending billions of dollars trying to simplify it. However, forward-thinking organizations have learned that when done correctly, a multi-cloud strategy can improve business resilience and risk mitigation by 68% while experiencing 58% less service disruptions.
Architecting data pipelines that are flexible and vendor agnostic is the key to a successful multi-cloud strategy. By controlling your data pipelines, you’re empowered to move quickly and take advantage of each cloud provider’s unique value propositions.
3. Controlling data = cost savings
Businesses that have implemented intelligent telemetry pipelines have, on average, seen an 18% reduction in costs by simply optimizing where certain hybrid cloud workloads should live. Think about taking advantage of reserved or spot instances for compute when processing workloads – enterprises can save millions on cloud bills just by tuning where their workloads run.
CloudZero’s 2024 State of Cloud Cost Intelligence Report found that only 30% of respondents knew where their cloud budget was going. An estimated $44.5 billionwas expected to be wasted in 2025, thanks to disconnects between developer and FinOps teams. That’s not loose change behind the sofa.
Companies are scrambling for visibility and control over their cloud spend. Adoption of FinOps tools has doubled in the last year as organizations seek to manage ballooning cloud costs. Infrastructure spend is real money.
Vendor lock-in is the nightmare fueling multi-cloud adoption
Here’s the issue: once you start using a vendor’s platform, it’s difficult to leave. Data ingestion is a great example. Vendors want your data, and lots of it, so they make it easy to send everything their way. When that happens, your data pipeline becomes an afterthought. Why architect something flexible when the vendor has already told you exactly how to send it all to them?
But as tooling changes, business needs evolve, and your priorities shift, you’re stuck with a vendor-specific data pipeline that becomes painful to switch.
Avoiding vendor lock-in is another primary driver for multi-cloud adoption, with an estimated 69% of enterprises using more than one cloud provider to help achieve this goal.
Enterprises that have cracked the code on solving their data movement challenges think about their telemetry infrastructure like programmable infrastructure. They architect their pipelines with flexibility in mind so that they can easily:
Dictate where different types of telemetry data should go: Not all data belongs in the same destination. Security logs need to route to a SIEM, metrics to an observability platform, and high-volume, low-value data to a cheaper long-term store. A flexible pipeline lets you make those routing decisions at the infrastructure level rather than rebuilding integrations every time your destination mix or your business needs change.
Transform data into the format their destination needs: Different platforms expect different data schemas. A well-architected pipeline handles the translation in-flight, filtering out noise, enriching events, and restructuring fields before data ever reaches its destination. Each destination gets data in the shape it expects without requiring custom work on either end.
Stop or reroute data at specific points in the pipeline without starting from scratch: When a destination goes into planned maintenance or a source system is temporarily unavailable, a well-architected pipeline gives teams the control to make targeted adjustments without shutting everything down. Without that control, a single unavailable endpoint can create backpressure that disrupts the entire pipeline.
Experiment with new ML tools without having to build new data integrations for weeks on end: When your pipeline is vendor-agnostic, adding a new destination is a simple configuration change. Teams can trial a new analytics or ML platform by routing a subset of data to it, without committing to a full migration.
This is just the beginning. Gartner predicts that “worldwide spending on AI is forecast to total $2.52 trillion in 2026, a 44% increase year-over-year,” and that “Building AI foundations alone will drive a 49% increase in spending on AI-optimized servers for 2026, representing 17% of total AI spending. AI infrastructure will also add $401 billion in spending in 2026 as a result of technology providers building out AI foundations.”
Worldwide AI Spending by Market, 2025-2027 (Millions of U.S. Dollars)
Market
2025
2026
2027
AI Services
439,438
588,645
761,042
AI Cybersecurity
25,920
51,347
85,997
AI Software
283,136
452,458
636,146
AI Models
14,416
26,380
43,449
AI Platforms for Data Science and Machine Learning
As more and more AI workloads take up increasing portions of total compute and data transfers between clouds grow exponentially faster than internal cloud transfers, data infrastructure is only going to see more change. Grab your galoshes. It’s about to rain data.
Mike Kelly is the Co-Founder and CEO of Bindplane and a telemetry industry veteran. At Bindplane, he leads the company’s mission to simplify and scale enterprise observability through OpenTelemetry and cloud-native innovation. With over two decades of experience spanning software engineering, product leadership, and executive management, Mike has built a career at the intersection of data infrastructure and modern observability. Before leading Bindplane, he served as CTO at Blue Medora, where he oversaw the development of one of the industry's first cloud-native telemetry pipelines. Earlier in his career, he worked in engineering and leadership roles in industrial automation and enterprise software.
Agentic AI changes where value is created in the software stack. When analysts discuss the “death of SaaS,” they rarely mean that cloud applications will disappear. Instead, they mean the SaaS model may lose its central role in enterprise computing.
Domain-specific LLMs are how businesses move from AI curiosity to AI utility where outcomes are measurable, adoption actually sticks, and teams trust what the model tells them.
Neoclouds offer performance specialization, which increasingly is factored into what some call multi-compute strategies. In general, what that means is that enterprises are using hyperscalers for general workloads, neoclouds for model training, and edge infrastructure for inference.
To implement a successful agentic AI initiative, business leaders need to define clear jobs with measurable impact, ensure tight cost controls, and construct strong guardrails around these systems.
The concept of “data in motion” is transforming the way organizations think about their technology stack and will determine which organizations can actually execute on AI and which are left drowning in endless streams of data.
The industry’s movement toward sovereign AI reflects a maturation of the market and an acknowledgment that AI at scale requires the same rigor in governance and infrastructure design that enterprises have long applied to other mission-critical technologies.
Analysis and market insights on real-time analytics including Big Data, the IoT, and cognitive computing. Business use cases and technologies are discussed.
Advertiser Disclosure: Some of the products that appear on
this site are from companies from which TechnologyAdvice
receives compensation. This compensation may impact how and
where products appear on this site including, for example,
the order in which they appear. TechnologyAdvice does not
include all companies or all types of products available in
the marketplace.

 Best Practices for Deploying and Scaling Industrial AIArtificial Intelligence (AI) is transforming industrial operations, helping organizations optimize workflows, reduce downtime, and enhance productivity. Different industry verticals leverage AI in unique ways.Link to The Center for Adaptive Edge Intelligence
Best Practices for Deploying and Scaling Industrial AIArtificial Intelligence (AI) is transforming industrial operations, helping organizations optimize workflows, reduce downtime, and enhance productivity. Different industry verticals leverage AI in unique ways.Link to The Center for Adaptive Edge Intelligence The Center for Adaptive Edge IntelligenceAdaptive edge intelligence brings real-time decision-making to the point of data creation, whether from sensors, machines, or cameras.Link to The Value of Vehicle Electrification
The Center for Adaptive Edge IntelligenceAdaptive edge intelligence brings real-time decision-making to the point of data creation, whether from sensors, machines, or cameras.Link to The Value of Vehicle Electrification The Value of Vehicle ElectrificationElectric vehicles (EVs) present automakers with many design, engineering, and manufactu ring challenges.Link to Accelerating Manufacturing Digital Transformation with Industrial Connectivity and IoT
The Value of Vehicle ElectrificationElectric vehicles (EVs) present automakers with many design, engineering, and manufactu ring challenges.Link to Accelerating Manufacturing Digital Transformation with Industrial Connectivity and IoT Accelerating Manufacturing Digital Transformation with Industrial Connectivity and IoTDigital transformation is empowering industrial organizations to deliver sustainable innovation, disruption-proof products and services, and continuous operational improvement.Link to Smart Manufacturing for Automotive
Accelerating Manufacturing Digital Transformation with Industrial Connectivity and IoTDigital transformation is empowering industrial organizations to deliver sustainable innovation, disruption-proof products and services, and continuous operational improvement.Link to Smart Manufacturing for Automotive Smart Manufacturing for AutomotiveLeading a transportation revolution in autonomous, electric, shared mobility and connectivity with the next generation of design and development tools.Link to Center for Data Pipeline Automation
Smart Manufacturing for AutomotiveLeading a transportation revolution in autonomous, electric, shared mobility and connectivity with the next generation of design and development tools.Link to Center for Data Pipeline Automation Center for Data Pipeline AutomationAs businesses become data-driven and rely more heavily on analytics to operate, getting high-quality, trusted data to the right data user at the right time is essential.Link to Center for Automated Integration
Center for Data Pipeline AutomationAs businesses become data-driven and rely more heavily on analytics to operate, getting high-quality, trusted data to the right data user at the right time is essential.Link to Center for Automated Integration Center for Automated IntegrationThe goal of automated integration is to enable applications and systems that were built separately to easily share data and work together, resulting in new capabilities and efficiencies that cut costs, uncover insights, and much more.Link to Continuous Intelligence: Insights
Center for Automated IntegrationThe goal of automated integration is to enable applications and systems that were built separately to easily share data and work together, resulting in new capabilities and efficiencies that cut costs, uncover insights, and much more.Link to Continuous Intelligence: Insights Continuous Intelligence: InsightsDigital transformation requires continuous intelligence (CI). Today’s digital businesses are leveraging this new category of software which includes real-time analytics and insights from a single, cloud-native platform across multiple use cases to speed decision-making, and drive world-class customer experiences.
Continuous Intelligence: InsightsDigital transformation requires continuous intelligence (CI). Today’s digital businesses are leveraging this new category of software which includes real-time analytics and insights from a single, cloud-native platform across multiple use cases to speed decision-making, and drive world-class customer experiences.