











Modern travel search platforms must return flight options almost instantly. “Real-time” in this context means processing and responding within seconds or sub-seconds. Customers expect immediate results, even under heavy load, so flight-search systems use specialized architectures to meet stringent latency requirements.
Achieving sub-second response times for highly dynamic, high-volume flight data involves addressing several challenges:
- Highly Dynamic Data: Flight availability and pricing can change very rapidly – often every few minutes or even every second. Cache entries can go stale quickly if not updated.
- Massive Data Volume: There are thousands of possible flight combinations (routes, schedules, fares) for any query, resulting in huge datasets to index or cache.
- High Concurrency: Popular travel periods generate spikes of millions of simultaneous searches. The system must scale horizontally to serve high request rates without degradation.
- Multi-Source Integration: Real-time inventory often requires querying multiple airlines or global distribution systems, adding network latency and variability.
- Freshness vs. Performance: Systems must balance up-to-date data with caching. Aggressive caching can speed responses but risks showing outdated information.
Importantly, real-time analytics requires distributed storage, a distributed query engine, and caching to handle large data and deliver results within seconds or sub-seconds. In practice, achieving this for flight search demands a combination of caching layers, timeout/circuit-breaker controls, and asynchronous messaging.
Multi-Tier Caching Strategies
A fundamental technique is multi-tier caching. Caches store recent or frequent query results so that repeated searches return data without hitting slower backends. Commonly, systems use a fast in-memory cache on each application server (tier 1) plus a shared distributed cache cluster (tier 2). For example, an in-process L1 cache (e.g., on-heap or local Redis instance) can hold the hottest items, while a Redis or similar cluster serves as a larger L2 cache. The lookup follows the tiers in order: check L1 (in-memory) first; if a miss, check L2 (distributed); if still a miss, fetch from the source (database or API) and populate both caches. This layered approach combines the speed of RAM with the capacity of a distributed store.
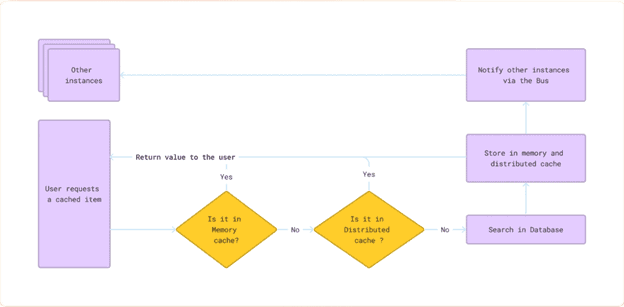
Figure: Multi-tier caching flow. When a user requests flight data, the system first checks a local memory cache. If the item isn’t found, it queries a distributed cache (e.g., Redis). A miss there triggers a fetch from the authoritative source (database or external service). The result is then stored in both the in-memory and distributed caches for future queries. By avoiding expensive upstream calls on cache hits, this flow dramatically reduces latency for hot queries.
However, caching flight data requires careful invalidation. Entries must expire or be cleared when underlying data changes. Simple time-based expiry (TTL) can remove data after a short interval (minutes or hours), but high volatility may require faster invalidation. For flight availability, invalidation is often event-driven: when a flight’s price or seats change, the system publishes an update that explicitly clears or updates the related cache entries. As the Redis docs note, cached flight availability and prices often update “every few hours,” so combining TTL with real-time invalidation helps keep data fresh.
Key caching best practices include:
- Cache what’s hot: Store frequent queries (popular routes, dates) and static reference data (airport info, schedules) in the highest cache tier. Rarer queries may rely more on lower tiers.
- Multiple layers: Use a very fast L1 cache (in-memory) for ultra-low-latency hits and a larger L2 cache (distributed) for capacity. For example, one system’s best practice is to put the most frequently accessed data in a small local cache and the rest in a shared cache.
- Appropriate expiration: Set TTLs that balance freshness vs performance. An airline fare cache might update every few minutes to several hours, depending on volatility. Event-driven invalidations (e.g., via pub/sub) can supplement TTLs to immediately expire changed entries.
- Monitor and tune: Track cache hit/miss ratios and refresh rates. Good cache hit rates mean fewer slow lookups. Adjust parameters (size, TTL) based on traffic patterns.
For example, a travel site that implemented a “fare cache” saw significantly faster searches: storing recent pricing and availability in memory avoided repetitive external calls, resulting in sub-second load times. That study reports that caching “reduce[s] the number of requests to GDS or other fare sources” and “improves the reliability of flight search results .”In essence, effective multi-tier caching offloads heavy query work from backend systems and can turn a multi-second query into a few tens of milliseconds.
Fail-Fast Timeouts and Circuit Breakers
Even with caches, flight-search services often must call external systems (airline inventories, payment services, etc.). Slow or failed calls in a distributed system can introduce unacceptable delays or outages. Thus, it’s crucial to implement fail-fast mechanisms and circuit breakers. A well-configured timeout ensures that the system does not block forever on a slow call: if a backend request doesn’t return within a strict deadline (often a few hundred milliseconds), the request is aborted, and the user receives a quick error or fallback. Timeouts “prevent resource exhaustion” and keep services responsive by terminating stalled calls. In practice, each service interaction has a reasonable timeout based on performance data so that network blips or slow endpoints don’t tie up threads or I/O.
The circuit breaker pattern is often used to isolate failures. This monitors the error rate of downstream calls and, on repeated failures, “trips” to block further attempts. In the closed state, calls pass normally. If too many errors occur (e.g., five failures in a row), the breaker switches to Open: all new calls immediately fail without trying the down service. After a cooling-off period, the breaker moves to Half-Open to test recovery. If a few trial calls succeed, it resets to Closed; if they fail, it goes Open again. This strategy avoids constant retries that would further tax a struggling service. As Azure’s patterns documentation explains, a circuit breaker “quickly rejects a request for an operation that’s likely to fail, rather than waiting for the operation to time out,” helping maintain system response time.
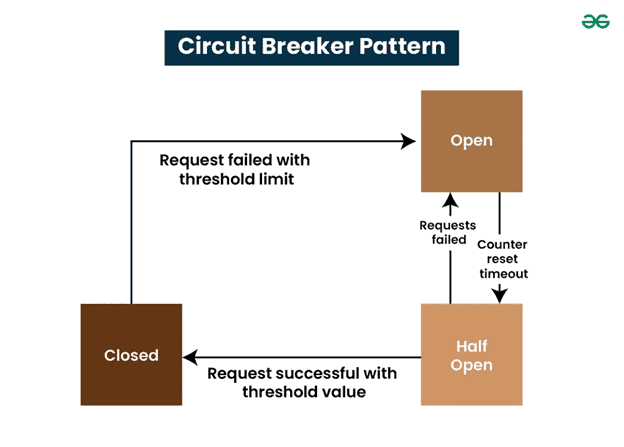
Figure: Circuit Breaker states (Closed, Open, Half-Open). In the Closed state, requests to a downstream service (e.g., a flight-info API) go through normally. If failures exceed a threshold, the circuit opens, and subsequent requests immediately return errors or use a fallback rather than waiting on a slow call. After a timeout, the breaker enters Half-Open and allows a few test requests; success resets it to Closed. This flow prevents a cascade of delays: when one service is failing, the circuit breaker “stops forwarding requests to the failing service” and isolates it.
In a flight-booking context, this might mean that if a flight availability service is down, the booking component’s circuit breaker opens to halt further calls. The booking service can then return a partial result (e.g., only cached data) or an immediate error rather than hanging. Once the flight-info service recovers, normal operation resumes. These resilience patterns (timeouts + circuit breakers) ensure that one slow component doesn’t stall the entire search system and that failures are detected and contained quickly.
Additional failure-isolation techniques include graceful degradation: for example, if a data source is unavailable, the service might return slightly stale cached results or omit non-critical options rather than failing completely. The goal is to preserve low-latency operation even under partial outages. Overall, by “failing fast” on slow requests and isolating faulty services with circuit breakers, the system maintains sub-second responsiveness.
See also: Unlocking Real-time Insights: The Power of Messaging and Event-driven Architecture
Asynchronous Processing and Message Queues
High-throughput flight search architectures also rely on asynchronous decoupling. Message queues or streaming platforms allow different parts of the system to communicate without blocking. For instance, instead of invoking downstream services via synchronous calls, a microservice can publish a message to a queue that a consumer service processes independently. This is valuable both for user queries and background updates:
- Decoupling: A message broker sits between producers and consumers, enabling temporal decoupling. The producer (e.g., a web API or data updater) submits a message and immediately continues. The consumer (another service) reads from the queue when ready. AWS documentation notes that message queues “enable asynchronous communication, which means that the endpoints producing and consuming messages interact with the queue, not each other.” In practice, if one consumer is slow or down, producers simply queue messages; other parts of the system continue operating normally.
- Load Buffering: Message queues naturally buffer bursts. If 10,000 flight-update events arrive suddenly, the queue accumulates them while consumers scale up to handle the load. No requests are dropped; they are processed as capacity allows. This helps smooth traffic spikes that are common in travel (e.g., initial surge when new schedules load).
- Event Streaming: Real-time flight data (price changes, cancellations, seat inventory) can be sent as events. Platforms like Apache Kafka or similar allow high-throughput, fault-tolerant streaming of such events. Downstream services (cache updaters, search indexers) subscribe to relevant topics and update their state in near-real-time. Because the queue persists events, even if a service temporarily lags or restarts, no updates are lost.
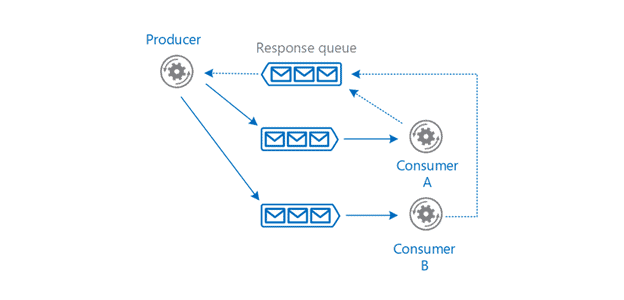
Figure: Asynchronous producer-consumer via a message queue. Here, producers send messages into a broker (queue). Consumers A and B independently pull from the queue when they are ready. The dashed line shows consumer A sending results back via a response queue. This decoupling means the producer never blocks waiting for a consumer. The queue ensures messages persist until a consumer processes them.
Using queues in flight search systems might involve ingesting global flight schedules via an event stream, then distributing those updates to regional caches, handling reservation requests by queuing booking tasks, or logging and analytics by pushing user interactions into a processing pipeline. The main benefit is that critical path latency isn’t tied to every downstream operation. For example, a search request can enqueue tasks to update recommendation models asynchronously while immediately returning cached results to the user.
Additional Architectural Considerations
Beyond the above, several other practices help achieve low latency in flight search systems:
- Horizontal Scaling: Use multiple stateless service instances behind load balancers. Add more servers (or containers) to handle higher loads. Caches can be shared or replicated across nodes. Because caches are in-memory, an increase in instances provides more aggregate cache capacity.
- Search Indexing: Precompute and index queryable flight data (e.g., via a search engine like Elasticsearch). Rather than querying relational tables for every search, the system can maintain an up-to-date index of available flights and fares. Index updates can occur asynchronously (via queues) whenever inventory changes. Queries against such an index yield results in milliseconds, even for complex route combinations.
- Efficient Data Models: Denormalize data and use key-value or columnar stores for frequently accessed data. Minimize join operations in real-time flows. For example, store pre-joined route+price documents in a cache or index.
- Protocol Optimization: Use compact data formats (like binary serialization or JSON with field filtering) to minimize payload sizes. Compress data in transit if beneficial. Small responses reach the client faster.
- Geographic Distribution: Deploy services and caches close to major user bases. Edge servers or CDNs can cache static content (like UI assets or common data), while regional API endpoints reduce network round-trip time.
- Timeout Budgeting: Allocate an overall latency budget (e.g., 500 ms) across components. Ensure individual services respond far quicker than the total budget to allow assembly time.
- Monitoring and Auto-Scaling: Continuously monitor latencies at each layer. Auto-scale resources (compute or cache nodes) when queue depths grow or latencies rise.
Each of these complements the core strategies. For example, an in-memory data grid like Apache Ignite or an elasticache cluster (Redis, Memcached) can scale horizontally to serve more users. Open-source tools such as Redis (for distributed caching) and Kafka (for high-throughput messaging) are commonly used in these architectures.
Conclusion
Delivering flight availability in real time (sub-second latency) under heavy load is challenging but achievable with the right architecture. Key strategies include multi-tier in-memory caching to serve hot data instantly, strict timeouts and circuit breakers to isolate slow dependencies, and asynchronous message-driven designs to decouple components and buffer spikes. Handling “petabytes” of data and millions of users in real time requires distributed query engines and caching. Indeed, one case study achieved a 95% reduction in search time (from 3 s to 150 ms) by redesigning the caching layer and moving to in-memory data stores.
Ultimately, there are trade-offs between freshness, consistency, and cost, but thoughtful design can satisfy real-time criteria. By combining layered caches, proactive invalidation, fail-fast controls, and scalable asynchronous pipelines, a flight-search system can reliably present the freshest possible results within the strict timeframes that modern users expect. These architectural patterns, when applied judiciously, enable real-time flight availability systems to scale and perform without explicit dependence on any particular vendor solution.







