











The performance of today’s demanding analytics workloads is often limited by the database architecture and other factors. Increasingly, businesses are turning to Presto, a high-performance, distributed SQL query engine that lets users query a variety of data sources such as Hadoop, AWS S3, MySQL, Kafka, MongoDB, and more.
We recently sat down with Dipti Borkar, Co-Founder & CPO at Ahana and discussed the types of workloads that can benefit by using Presto and the advantages to consuming Presto as a managed service. Here is a summary of our conversation.
RTInsights: What type of workloads benefit from using Presto?

Borkar: Before we get into the workloads that are best fits for Presto, let me share a quick overview of the platform itself. Presto is an open source project that was created at Facebook. They donated it to the Linux Foundation, and today, it operates under a community governance model. It’s hosted by the Presto Foundation. At the core, it is an in-memory distributed SQL engine. It’s federated, which means that you can query data across data lakes, as well as databases and a range of different data sources. So you can use open formats like JSON, CSV, as well as some of the popular columnar formats like Parquet and Apache ORC, which are highly efficient, and query data sources like MySQL, PostgreSQL, and Elastic, along with different categories like NoSQL, RDBMS, caches, streaming systems, etc. The beauty of this is that you can correlate across these data sources.
You can have joins across different databases and data lakes. That’s the power of Presto. Going back to the workloads that are good fits for Presto, I group them into three different areas.
#1: Interactive Workloads
The first is interactive workloads, and there are three main use cases that fall under this category.
Use Case 1: Reporting & Dashboarding
You can think of Tableau or any of the BI tools that run on top of the data, which essentially use SQL at the back, which then can run on Presto. Increasingly it is the preferred choice, especially in this disaggregated stack with data lakes, with S3, GCP, and others, where you can run a BI tool on top and have the data sources, the data lakes, or relational database below it.
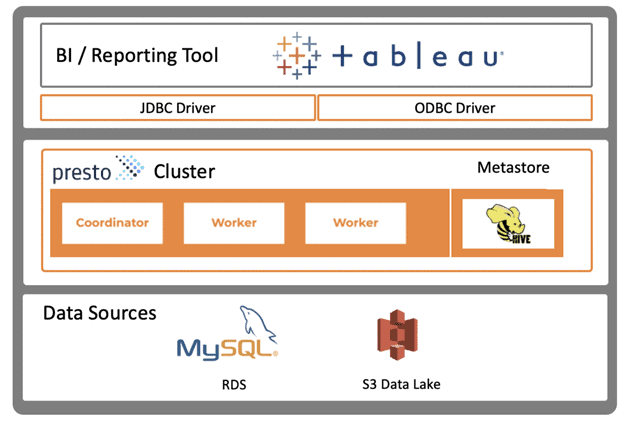
That’s one of the core use cases for Presto: reporting and BI. A data platform team can support Presto. And data analysts running Tableau can query a range of different data sources.
Use Case 2: Data Science
The second interactive workload is more on the data science side of things. Beyond reporting, which is more traditional, increasingly we are seeing Presto used for data science workloads. A data scientist now writes a notebook with a Jupyter, Apache Zepplin, or any of the popular notebook tools, or they are using Python tools, which are then creating structured data sources or structured objects in the data lakes. You have these data science notebooks running, connecting to Presto via JDBC driver, and then looking up data sources like S3 via a metastore like Glue or Hive that maps these objects.

Use Case 3: Federated Analytics across data sources
And then, something that’s not mutually exclusive but overlapping is federated workloads, where you are querying across the different data sources that enterprises increasingly have. So, they might have MySQL for the relational database, Redshift for the data warehouse, and many more. This data is not aggregated, but you want to query across some part of it. And that’s the federated interactive use case.
#2: Batch Analytics
The second type of workload we see Presto used for is Batch Analytics. Think of traditional transformation workloads generated using tools like Informatica or Talend. Now, what’s increasingly happening is the transformation is done in the data lake itself. The data is landing first in the data lake, and then it is being transformed and ETL’d [extracted, transformed, and loaded].
So the first generation was Informatica and Talend. The second generation was Hive and Spark. And with the innovations that Facebook has added, we’re seeing more of these batch workloads moving to Presto instead of Spark or Hive.
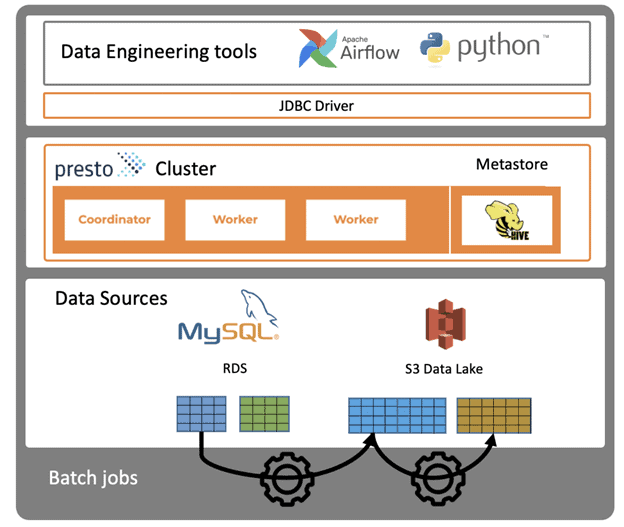
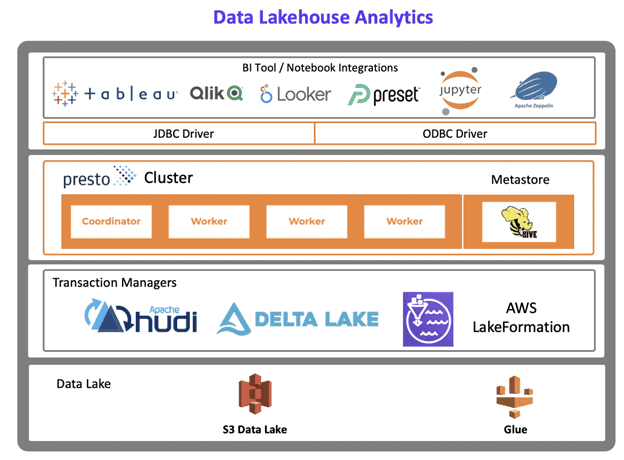
#3: Data Lakehouse Analytics
Finally, there is an emerging category called the lakehouse, which is when a data lake meets a data warehouse. This is an emerging workload where we are seeing more transactionality being added to the data lake. It can be a combination of interactive and batch workloads. In this new stack, you have transaction managers added on top of the database.
RTInsights: How is Presto different from other analytics and query engines like Spark and Hive?
Borkar: Apache Hive is an SQL engine but was built for HDFS and depends on storing data to disk. While this worked well, the Hadoop era with HDFS coupled with the slow speed of Apache Hive jobs and dependence of disk is prompting users to evaluate other engines. This is particularly the case for interactive workloads where low latencies are required, but as explained above also for batch workloads.
When you are looking for lower latencies, not hours, but minutes or seconds, you need a completely different engine and a different kind of architecture to meet those needs. That’s how Presto took over as a replacement for Apache Hive at Facebook – it has now taken on almost all the Hive workloads at Facebook and is not only being used for interactive workloads, but also batch workloads.
Apache Spark is a general-purpose computation engine. While it is a very powerful tool for all kinds of workloads, it is not built like a database. This is one of the key differences between Presto and Spark. Presto is built like a database similar to MPP SQL engines. That means it is highly optimized just for SQL query execution. Spark is better for ETL workloads. In addition, Presto uses an in-memory, pipelined architecture versus Spark that requires intermediate results to be persisted. This makes Presto a faster engine for structured data analytics.
RTInsights: What are the advantages of using Presto?
Borkar: There are several key reasons why Presto is so popular. The first one is that there’s data everywhere in all these different data sources. And increasingly, people are spending more time on moving data out and transforming it than getting insights from it. The value of data really is the insight that you get from the data. Once it’s processed, you start asking questions about the data.
Instead of moving data in and around, wouldn’t it be easier to not ingest it into yet another system and move it to yet another place, but just leave it where it is and query it? That’s what Presto does. Presto doesn’t need to move your data. It can query your data in place, in popular formats. Some formats are obviously more performing than the others, but there’s no ingestion needed. You’re not loading it into yet another system and you’re not locking it in to a proprietary system. So, it stays open. You can use open formats, and that’s one of the powers of Presto.
A second advantage is SQL. It’s survived so many years. It’s the unified interface for structured data. So you can drop Presto into many of your existing use cases without a whole lot of changes. Otherwise, migrations become very hard. And that’s the power of Presto. It can very easily be plugged into anything that uses JDBC, ODBC, and standard drivers.
Third is performance. At the end of the day, people are impatient, and systems need data fast. Presto is fast and is built for high performance. It’s in-memory, and it continues to get faster as the innovation has continued.
The fourth benefit is federation and the power of correlation across different data sources. Presto is built to be a pluggable engine. It’s very easy to build a connector, so it’s pluggable. Of course, not all data sources are equal. Most of the data is going to go into a data lake – we see that in about 80% of the workloads. But that leaves 20% where you do something else. For example, 5% of your workloads might occasionally be a thing like a join across two or three data sources. That is the power of federation. You don’t need to move data around. You can do it with the same engine that you do your regular analytics with.
And finally, in this disaggregated stack, storage is separate, and the query engine is separate. The power of that is that you can now have these database-like engines be cloud-native. They are almost stateless. They’re not managing data itself. So you can have Presto on containers. You can run it in a Kubernetes container in a cloud architecture on Amazon, as an example. It is very easy to scale up, scale down, and scale-out. With the power of cloud and the power of a Presto query engine, you get the best of both worlds.
RTInsights: Why use a managed service for Presto like Ahana Cloud?
Borkar: It’s amazing to see these large internet companies like Facebook, Uber, and more running mission-critical workloads on Presto. But at the end of the day, it is a distributed system, and it is complicated. There are hundreds of thousands of knobs and configuration parameters that need to be tuned and managed. Internet giants have the talent and the resources to go with Presto.
Most SaaS companies, mid-sized companies, and even large enterprises may have a three, five, ten-person data platform team. They are not only managing Presto but everything else in the ecosystem. It can be extremely challenging. What we’ve seen from the Hadoop era is you want to spend less time on managing and more time on actually getting insights.
I would say the number one reason for a managed service is that you don’t need to know those parameters–let the service do the job and make it easy to use. Managed services also come with an acceleration layer. Presto is just an engine. It depends on a range of other components. It depends on the metadata store, which converts object stores into tables, databases, tables, and columns. You have to either bring one up on your own and manage it, or you have to integrate with Glue in AWS.
A Presto managed service like Ahana Cloud is a complete package. With a click of a button, you can have a managed Hive Metastore up and running that’s integrated with everything including Glue and other data systems.
Next is operational ease of use. Scaling up, down, auto-scaling…there are a lot of issues beyond just the initial installation and tuning. The management itself can be complicated. Upgrades, stopping class, or starting classes handled automatically–all of that can be taken care of by a managed service.
And finally, there might be capabilities that you can realize when it’s a completely integrated infrastructure. You can better innovate on the engine to actually make it more powerful. As an example, with Ahana, it runs two to three times faster out of the box compared with open-source Presto, and when you add data lake IO caching, you get even better performance. These are some of the big advantages of managed services. They include ease of use, easy deployment, easy management, less time on Ops, and more time on getting insights.







