Digital transformation means adopting new ways of working. Its key levers are DevOps and cloud. I prefer to use the word ‘evolution’ over ‘transformation’ because transformations fail. They fail because we treat them as projects, and projects fail.
Projects fail because they are waterfall and directed from the top of the organizational tree. Waterfall means that we work with huge batches of requirements and complete all the work in sequential steps using different teams. This big bang approach alienates the people we need to actively participate and drive the change because it’s inflicted on them. Britt Andreatta explains in her book ‘Wired to Resist’ why this problem occurs:
“Several structures in our brain are actually designed to protect us from the potentially harmful effects of change. Humans are wired to resist change, and we are working against our biology at every turn. It’s well documented that every year 50 to 70 percent of all change initiatives fail.”
There is a different way; smaller, evolutionary increments AKA agile. Evolution helps us see, plan and do the work in small increments. This way, we receive feedback quickly, see, plan and do the right next small increment of work, thereby mitigating the risk of going down the wrong path. Working in small increments helps us build small, autonomous, and multi-functional teams. These teams take direction from leadership, but they are self-managing and receive feedback directly from their customer. They choose to change.
In an enterprise, we have lots of different teams. In an ideal world, these teams are autonomous, i.e., they are not dependent upon one another. But when we are evolving from a siloed, structured, project-oriented way of working, this doesn’t happen overnight. So we seek to understand and categorize our teams by type and define how they interact with one another, where the dependencies are.
As a digital transformation progresses, leaders want to know that the organization’s performance is improving. Since organizations are comprised of teams, this isn’t always an easy question to answer. We need to get granular and understand each teams’ capability and empower each team to improve themselves.

I use the word ‘capability over ‘maturity’ because:
- Maturity indicates there’s a place where we are veterans, and while we may get more experienced, we’re never done because the horizon is always moving as we discover better ways of doing things and new technologies and techniques to propel us forwards.
- In DevOps, one team may be great at psychological safety, and another may be delivering new code to production several times a day. But talking about one being more mature than the other is not helpful – because they have different variables affecting them, and there are so many dimensions of capability to consider
One of these DevOps dimensions is observability. With its roots in mechanical engineering, observability’s recent rise in the world of software is caused by our adoption of cloud as a key lever for digital transformation.
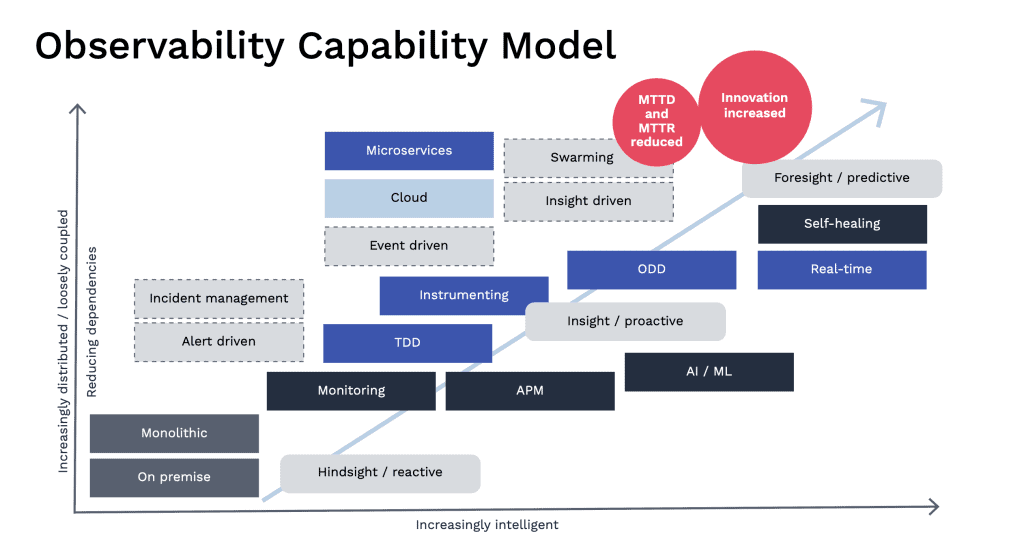
Observability has been applied to our digital world because of the inherent complexities of distributed computing; what happens when we move from monoliths to microservices. This observability capability model helps visualize what changes as systems become more loosely coupled (y-axis) and our operational environment becomes increasingly intelligent (x-axis):
How Systems Evolve
The transition from monolith to microservices occurs because the monolith is a constraint because of its huge size and tightly coupled nature. We have to test and deploy the whole thing to make a change which is very slow, and to compete, and we need speed. We rebuild, rearchitect or evolve these systems (using techniques like the strangler pattern) so that they are constructed of loosely coupled, small components that we can test and deploy autonomously and at speed. But now we have a complexity problem – lots of microservices to manage along with the APIs they use to talk to each other. Traditional monitoring no longer suffices, so we start to instrument observability into the systems and look for methods and tools to help us find the unknown unknowns. We practice Test-Driven Development (TDD) to build quality in and then combine these techniques with Observability-Driven Development (ODD) to ensure we can know what our customers are experiencing.
How Visibility Evolves
- From having hindsight and being reactive to problems when they are reported, often by the customer, always by alerts which are frequently so voluminous, we suffer from alert fatigue.
- To having insights into system behavior and being proactive about determining when issues might occur thanks to understanding events and discovering and remediating before the customer sees and reports them.
- To having foresight into systems’ behavior and using tools that provide insights into patterns that enable us to be predictive about when failures might occur and take remediating steps before they do and automate repeatable remediations to create self-healing in our systems.
How Incident Management Evolves
We evolve our systems to increase throughput and stability and, in doing so, increase complexity, so we learn new techniques and tools to help us pinpoint problems. At the same time, we’re reorganizing as autonomous, multi-functional teams because we recognize that this also helps us accelerate the flow of value outcomes to our customers and optimize quality. We build it, and we own it, so it makes no sense now to have a multi-tiered service desk model with escalations and hand-offs and delays, and people who don’t know our product like we do try to fix it. And we’ve got the data because we instrumented it into our product. And we’ve got the tools because we chose them to help us run our product. So, we intelligently swarm instead,
AIOps
There is a problem with observability. Its name is data. The complexity of a distributed systems environment is a problem in its unpredictability, anomalies, and unknown unknowns. But a bigger problem is the huge amounts of data it creates and the limited cognitive loads of humans. The solution is to ask our machines to help us with our machines. We have machines that can help us understand all the data our other machines are emitting now in ways the human brain simply cannot. Enter our AI. AIOps is a force multiplier. This AIOps capability scale explains how as teams evolve their use of these technologies, they gain increasing benefits.
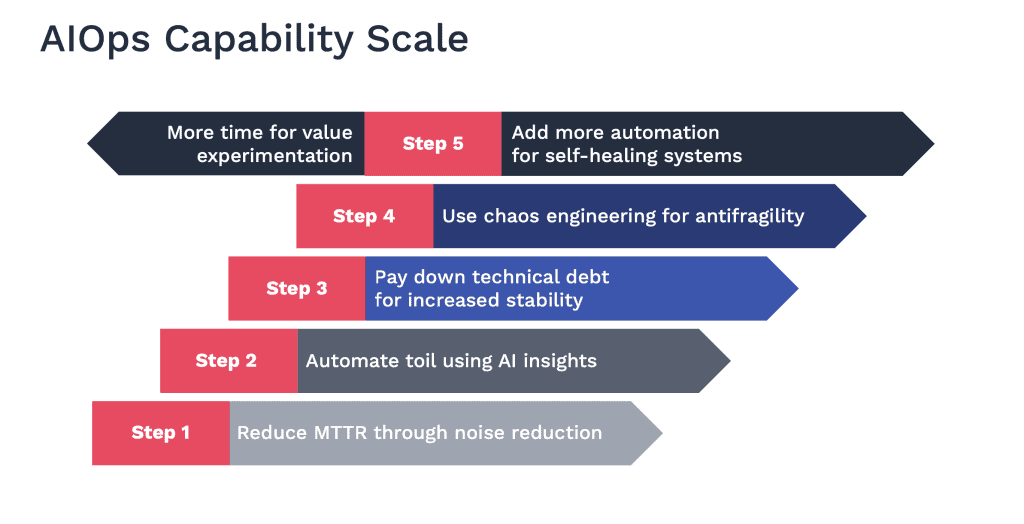
Step 1: Reduce MTTR Through Noise Reduction: AIOps is typically adopted when teams are under pressure from high volumes of unplanned work caused by unstable and complex systems. This working environment is more than unpleasant; it causes burnout and is unsustainable. These teams likely have a multitude of monitoring systems and will be suffering from alert fatigue. At this initial step, the implementation of AIOps alleviates alert fatigue through noise reduction by de-duplicating and correlating alerts and events. This greatly reduces both the Mean Time To Discover and Mean Time to Resolve incidents, and consequently the amount of time spent on unplanned work. It doesn’t resolve the underlying causes of ongoing issues yet, though.
Step 2: Automate Toil Using Insights: Now that the teams are spending less time on unplanned work, they can reuse these newly available hours to identify where they are repeatedly performing the same manual tasks and automate them away. Insights from the AIOps tools will help them prioritize these efforts based on the frequency and severity of the issues they repeatedly face. Now they have even more time available.
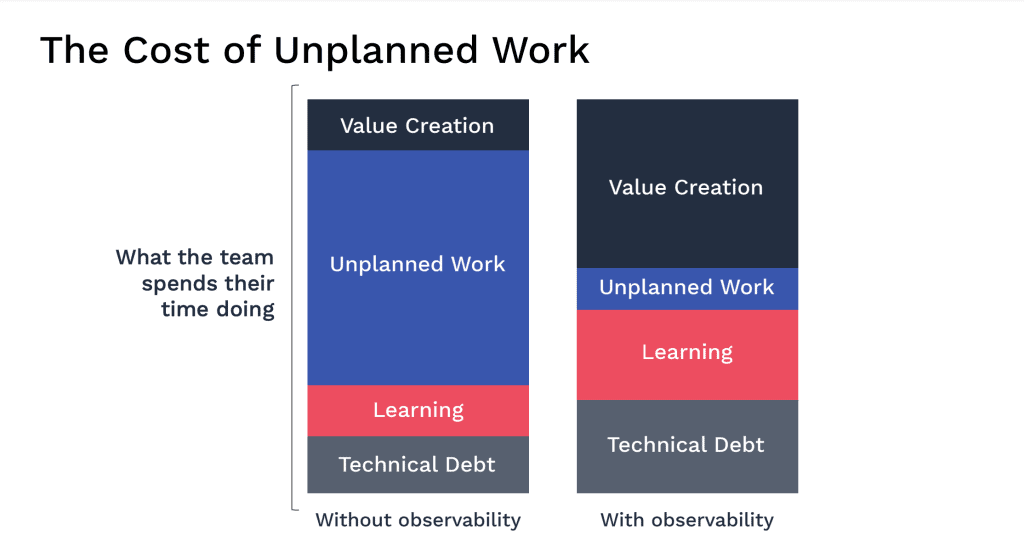
Step 3: Pay Down Technical Debt for Increased Stability: These insights also tell us where our systems are most vulnerable to breakages, likely the areas where technical debt has been accrued through coding shortcuts, unresolved low-level defects, or lagging patching. Now the teams have time to pay this down and can plan their work (they can do this for toil automation, too) by writing user stories in their backlog. The teams can monitor their backlog over time now for work types – they’ll see that unplanned work dropping, an increase in toil automation, and tasks addressing technical debt. Then those will start to decrease too as the systems become more stable.
Step 4: Use Chaos Engineering for Antifragility: Once the systems have achieved sufficient stability and the teams are confident and can see they have the time available, they can start planned, controlled experiments to break them and learn from the results. We move beyond stability here towards resilience and then antifragility.
Step 5: Add More Automation for Self-healing Systems: All this time, the team now has on their hands! Unplanned work is close to zero since the causes of it have been resolved, there’s no toil left, and even when something bad does happen, it’s so quick to discover and resolve it. The team’s practiced automation to pay down that toil, and now they can take it a step further and automate fixes. This is self-healing; think of it as teaching your machines to look after themselves and each other.
Consequences
There’s only really one that matters; the sublime customer experience. If your customers are happy (and your business model works), you will have a high-performing organization. As your teams evolve their observability and AIOps capabilities, your customers can experience uninterrupted service. Another work item type the teams can be working on is innovation – this is value creation for your customers. This is the stuff that differentiates you from your competitors and propels you to the top of your market.