








Sponsored by Intel

Fast Gradient Boosting Tree Inference
How to Boost Prediction Quality and Performance Using the Intel Data Analytics Acceleration Library
By Kirill Shvets, Machine Learning Engineer, and Egor Smirnov, Software Engineering Manager, Intel Corporation

Gradient Boosted Trees (GBT)¹ is an accurate and efficient machine learning (ML) algorithm for classification and regression tasks. There are many GBT implementations, but perhaps the most popular is the XGBoost² library. Our previous article, Accelerating XGBoost for Intel Xeon Processors(The Parallel Universe, issue 38)³, reported a significant improvement in CPU-based training for XGBoost. The performance for the Intel Data Analytics Acceleration Library (Intel DAAL)⁴ was shown to be even better. ML inference is just as important as training because end-users need model predictions as quickly as possible. That’s the focus of this article.
Performance Comparison
In this article, we’ll compare inference performance for the following GBT implementations:
- Forest Inference Library (FIL)⁵, a open-source library in RAPIDS cuML⁶ that provides GPU-accelerated inference for boosted decision tree models
- XGBoost CPU/GPU inference (master branch)
- Intel DAAL (version 2019, Update 5), a highly-optimized open-source library for Intel® platforms
Real-world data sets were used for performance analysis: Bosch, Epsilon, and Mortgage (Q1 2000 subset). We shuffled each data set and randomly selected the following subsets for the prediction stage:
- Bosch⁷ (968 features, ~1.1M total number of observations, 100K for prediction)
- Epsilon⁸ (2,000 features, 400K total number of observations, 100K for prediction)
- Mortgage⁹ Q1 2000 (45 features, ~9M total observations, 1M for prediction)
We chose model sizes sufficient to achieve best accuracy on the selected data sets (Appendix A). For performance measurements, we used AWS EC2 instances:
- CPU: c5.metal (2nd generation Intel Xeon Scalable processors, 2 sockets, 24 cores per socket),
- GPU: p3.2xlarge (NVIDIA Tesla V100).
For details, see the Configuration section below.
GBT inference requires less than 10 GB of memory for the most memory-hungry workload, Epsilon, in our comparison. Therefore, all the workloads considered here fit into the memory of the CPU and GPU instances.
It’s common in ML to apply the inference model to one data observation at a time (i.e., the batch size is set to 1). GBT inference can also be applied this way, but to be comprehensive, we’ll consider varying batch sizes.
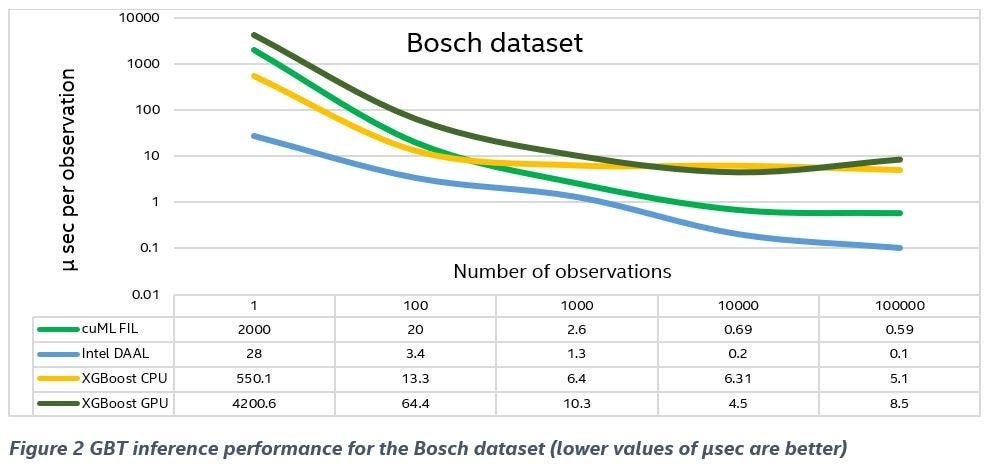
Figure 1, Figure 2, and Figure 3 show:
- The CPU implementation of XGBoost (yellow line) is competitive with the GPU implementation (dark green line), and even outperforms it on smaller batches.
- FIL (green line) is faster than stock XGBoost CPU/GPU in most cases (medium and large batch sizes), while Intel DAAL performs even better.
- The Intel DAAL implementation (blue line) significantly outperforms FIL (green line) on a one-row case.
- The Intel DAAL implementation (blue line) has better performancefor medium and larger batch sizes.


For XGBoost GPU and CPU performance measurements, input data was provided in the native format, XGBoost DMatrix. For prediction with GBT in Intel DAAL, we passed NumPy contiguous arrays.
For internal implementation reasons, the cuDF data format isn’t performance-oriented for FIL. This meant that we had to provide NumPy contiguous arrays as an input, since it’s a more efficient―and faster―way to load data on a device than an external load (e.g., the CuPy library that we also used). However, in real end-to-end ML workloads on the GPU, it’s more common to do ETL with cuDF and input a cuDF DataFrame without data conversion (i.e., without any additional overhead). Figure 4 shows that the cuDF format for FIL inference is dramatically slower than FIL with the NumPy data format, especially compared to Intel DAAL. We get expected performance in end-to-end machine learning applications.
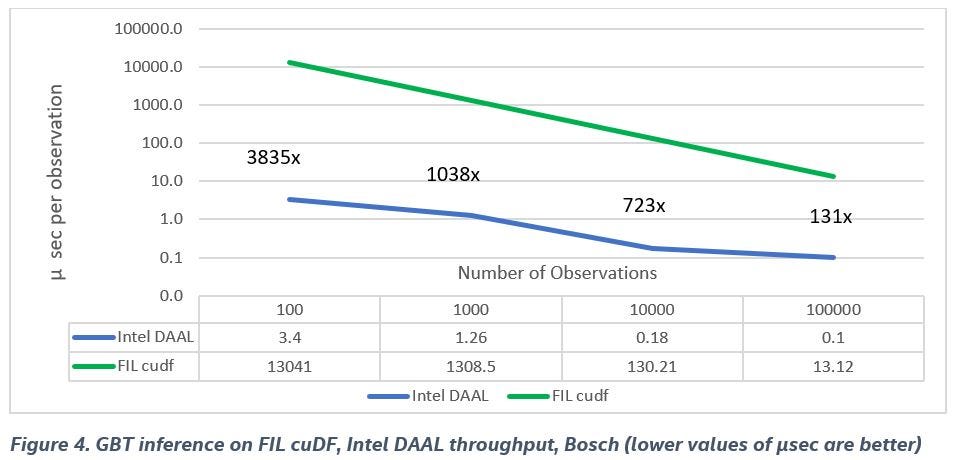
We can draw the following conclusions from our performance measurements:
- Inference on Intel DAAL is significantly faster than other implementations when the batch size is equal to 1, which is one of the most important use-cases.
- Inference on Intel DAAL is faster even for bigger batches and for reasonably-sized models.
- XGBoost CPU and GPU inference is approximately the same for all datasets.
- The cuDF format (commonly used in end-to-end applications) for FIL inference is dramatically slower than Intel DAAL inference.
Cost Analysis
We selected the most efficient CPU and GPU implementations to determine prediction cost: Intel DAAL and cuML FIL. The following AWS EC2 instances were used in our experiments (costs as of December 2019)¹⁰:
- CPU: c5.metal, $4.08 per hour
- GPU: p3.2xlarge, $3.06 per hour
Table 1 shows an example of prediction cost computation for the Epsilon data set (100K observations). Figure 5 shows a prediction cost comparison for Intel DAAL versus FIL.

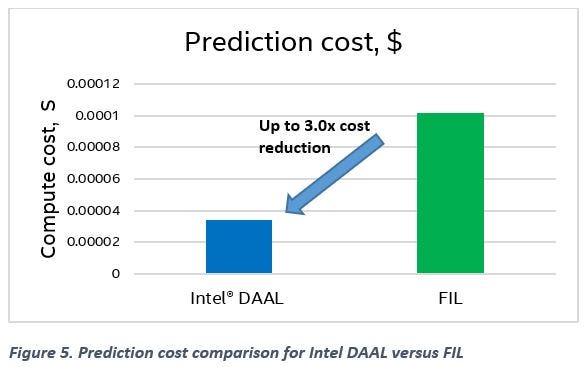
The same cost calculations for other datasets show:
- Bosch dataset: 4.4x gain with Intel DAAL versus cuML for prediction cost
- Mortgage data set: Intel DAAL is on par with cuML
Compared to the GPU implementations, GBT inference with Intel DAAL on the CPU is faster and less expensive.
Functionality Comparison
We compared available functionality in XGBoost, Intel DAAL, and FIL and summarized it in Table 2.
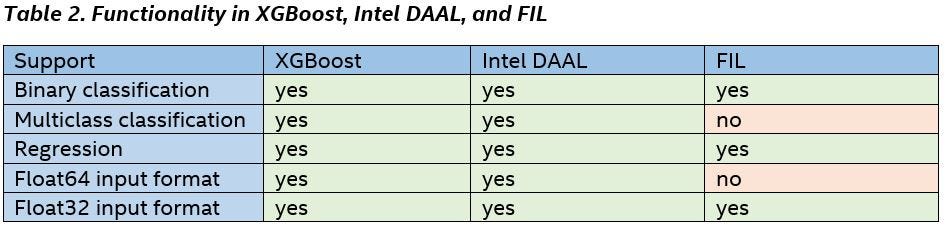
Due to limitations in FIL, all performance comparisons were provided in single-precision floating-point format and using binary classification and regressions data sets.
What Makes Intel DAAL Faster?
To maximize the utilization of modern Intel Xeon processors, Intel DAAL applies the Intel Advanced Vector Extensions 512 (Intel AVX-512) vector instruction set for fast GBT inference (Figure 6). The main operations in GBT inference are:
- Data comparison for evaluating conditions in each split-node
- Random memory accesses (read) to tree nodes and single features from predicted observations
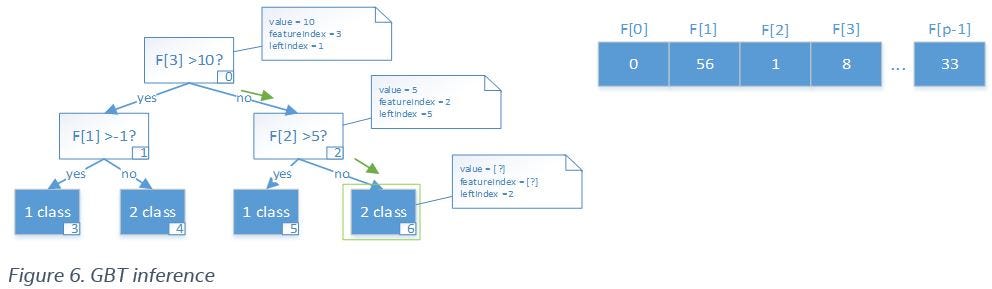
To process an observation via one tree, we used this idea until reaching a leaf-node. On the current node of the tree, we compared a certain feature value from the observation F[node.featureIndex with the split value node.value from the node. The index of the next node is defined as:

The main inference operations, comparison and random memory accesses, can be efficiently implemented with the vpgatherd{d,q} and vcmpp{s,d}Intel AVX-512 vector instructions. To apply these instructions, search the tree for a few observations (a block of rows) at the same time for each tree:
- Gather information, splitting values
valueand feature indicesfeatureIndexfrom certain tree nodes for each observation in the block of rows - Apply vector comparisons between
valueandF[featureIndex]for the observations - Compute indices for the next nodes for each observation based on the comparison
We do this for each observation until we reach the leaf nodes in the tree.
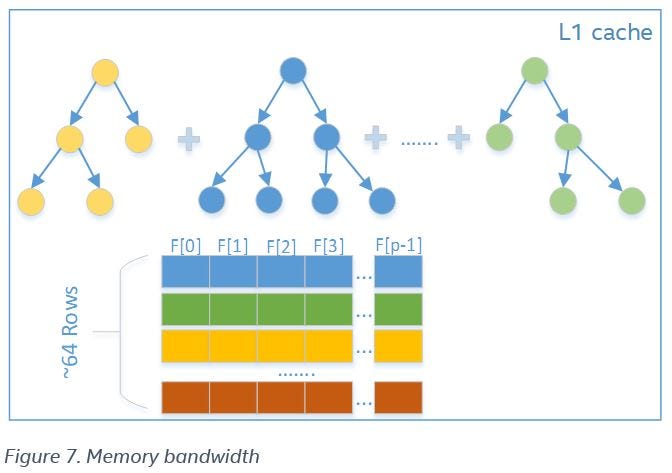
The performance of the algorithm depends on the efficiency of memory accesses and memory bandwidth. Intel DAAL uses smart data blocking for tree structures to improve temporal cache locality, a subset of trees, and a block of observations that fits in the L1 data cache size. After this, we implement the required prediction for the observations with the subset of trees. As a result, most of data accesses lead to L1 data cache hits with the highest memory bandwidth (Figure 7).
Faster Performance
Summarizing the results of our performance comparisons, we can conclude that we can achieve the same prediction quality much faster performance using GBT in Intel DAAL on a CPU compared to other implementations. The inference with Intel DAAL is significantly faster for online inferencing (i.e., when the batch size equals 1). This is an important use-case in applied ML, because it’s important to minimize the time required for handling the user-supplied data and predicting the outcome (e.g., object detection in autonomous driving), and there’s no possibility of accumulating a bigger batch of data.
For general cases when data was accumulated in bigger batches, Intel DAAL on the CPU also outperforms both the FIL GPU and XGBoost. For maximum available batch size, we have a relative speedup for Intel DAAL versus FIL: 4x for Epsilon, 5.9x for Bosch, and 1.4x for Mortgage.
Besides fast performance, Intel DAAL provides a user-friendly Python interface, with code for inference that’s simple and short.
In computational cost calculations, we saw that for the same payload, the cost for CPU-based inferencing with Intel DAAL is, on average, 2.85x times cheaper than for FIL¹⁰.
Code Examples
For XGBoost:
# x_train, labels, x_test = ... # Train model with XGBoost model_xgb = xgb.train(..., xgb.DMatrix(x_train)) # Generate predictions (as a NumPy array) predicts = model_xgb.predict(xgb.DMatrix(x_test))
For Intel DAAL:
import daal4py as d4p # x_train, labels, x_test, n_classes = ... # Train model with Intel DAAL train_algo = d4p.gbt_classification_training(n_classes, ...) train_result = train_algo.compute(x_train, labels) # Generate predictions (as a NumPy array) pred_alg = d4p.gbt_classification_prediction(n_classes) predicts = pred_alg.compute(x_test, train_result.model)
For FIL:
from cuml import ForestInference # Load the classifier previously saved with xgboost model_save() model_path = “xgb.model” fm = ForestInference.load(model_path, output_class=True) # Generate predictions (as a gpu array) fil_preds_gpu = fm.predict(X_test.astype(‘float32’))
References
[1] Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System, in the 22nd SIGKDD Conference on Knowledge Discovery and Data Mining, 2016.
[2] XGBoost Library
[3] The Parallel Universe, Issue 38
[4] Intel DAAL
[6] cuML
[7] Bosch data set
[8] Epsilon data set
[10] AWS EC2 Pricing as of 12/02/2019. URL: https://aws.amazon.com/ec2/pricing/on-demand/. Region: US East (N. Virginia)
Configuration
Algorithm Parameters
While the number of trees and max tree depth parameters varied for each data set, all other parameters were fixed (Table 3). Performance data were collected in November 2019.

For FIL inference we used a pre-trained XGBoost model.
Due to FIL limitations, performance was measured only for single-precision floating-point format (float32), since FIL doesn’t support double format currently.
Hardware Configuration
CPU configuration: c5.metal AWS EC2 instance (2nd generation Intel Xeon Scalable processors): 2 sockets, 24 cores per socket, HT:on, Turbo:on OS: Ubuntu 18.04.2 LTS, total memory of 193 GB (12 slots/16 GB/2933 MHz).
GPU configuration: p3.2xlarge AWS EC2 instance: Intel Xeon E5–2686 v4 processor @ 2.30 GHz, 1 socket, 4 cores, HT:on, Turbo:on; GPU: Tesla V100-SXM2–16G (driver version: 410.104, CUDA version: 10.0), OS: Ubuntu 18.04.2 LTS, total memory: 61 GB (4 / 13312 MB).
Software Configuration
- RAPIDS FIL (Forest Inference Library) — version 0.9
- Intel DAAL — version 2019 Update 5
- XGBoost — master (ef9af33a000f09dbc5c6b09aee133e38a6d2e1ff)
Other software: Python 3.6, Numpy 1.16.4, Pandas 0.25, Scikit-lean 0.21.2.
Appendix
Accuracy on a tested subset generally correlates with two major model parameters: the number and depth of tree estimators. Thus, we chose model sizes that are sufficient to get a better accuracy on classification data sets (Table 4 and Table 5).


Inference accuracy on a selected model (Epsilon “1000–4”) is approximately the same with Intel DAAL for FIL and XGBoost CPU/GPU: 0.874400. On another selected model (Bosch “100–12”) accuracy is also approximately the same with Intel DAAL for FIL and XGBoost CPU/GPU: 0.99444.
For regression inference on the Mortgage dataset, we used the parameters published by NVIDIA for their RAPIDS benchmarks (the trained model has 100 tree estimators with maximum depth equal to 8).
