











Innovation from the machine learning industry is putting new and extensive demands on the real-time capabilities of organizations’ data platforms. Within a few clicks or from a cursor pattern, customized in-app behaviors reward users for their sustained attention. Data has to flow through streams while being shoved through complex transformations and queried for additional context from known histories—all within milliseconds.
Gone are the days of primarily thinking in large, monolithic predictive models. Machine learning has a need for speed, one that requires a new way of thinking about architecture. Some interesting, hard problems now lie at the intersection of composable stream processing, fast movement of small payloads, and explainable predictions. In this article, I’ll discuss why ML needs to move faster and look at three important architectural investments to help address the challenges of adding real-time ML (which applies to “near real-time,” too) into your applications: orient your data around processing time, rely on the power of SQL with streaming, and build in observability.
Real-time machine learning is just as much an area of innovation for distributed, composable infrastructure as it is for inventing mathematically sound, fast feedback loops for continuous learning. Let’s dive in.
Machine learning is going real-time
Over the past 10-plus years, machine learning practitioners learned that latency matters in their world, especially for user-facing applications.
“Data fed to ML models is often most valuable when it can be immediately leveraged to make decisions in the moment.” Yu Chen, senior software engineer, Headspace.
Google’s experiments demonstrated that increasing web search latency from 100 ms to 400 ms reduces the daily number of searches per user by 0.2% to 0.6%. In 2019, Booking.com found that an increase of 30% in latency cost about 0.5% in conversion rates — “a relevant cost for our business.” And merchants have estimated fraudulent transactions account for an average of 27% of their annual online sales. The longer it takes for you to detect the stolen credit card, the more money you’ll lose.
In March 2022, Nnamdi Iregbulem of Lightspeed Venture Partners (a member of the team that poured $240M into Grafana Labs in April) said: “Organizations are increasingly fed up with traditional data infrastructure, which is slow to yield answers to key business intelligence questions and often out of date and out of sync with current business realities.” Zhamak Dehghani captured in her recently published book “Data Mesh” the sentiment that echoes among data teams by describing the worst place your data can be for analytical processing: “in its transactional database.”
These insights point toward a dueling pressure that time places on data architectures. On one side, we’re bound by physics and math: how fast can we move bits and perform relevant calculations with context? In the other direction, algorithms are trained and rewarded for specific outcomes: how do we encourage that human behavior in fewer steps and in less time?
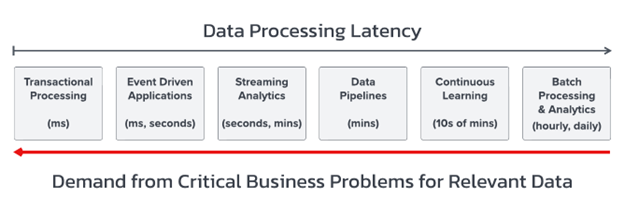
Figure 1: The dueling pressure of time that is moving innovation in the machine learning industry toward real-time data predictions with continuous, online-learning models.
The world of real-time data predictions with continuous, online-learning models demands a different set of expectations for your data and data teams. Teams that are considering real-time machine learning will deeply examine each of the following three ways of thinking about their data.
1. Orient your investments by data processing time
“No matter how great your ML models are, if they take just milliseconds too long to make predictions, users are going to click on something else.” Chip Huyen, Machine Learning is going real-time.
To ML practitioners like Chip Huyen—and the teams she’s worked with at Netflix, Nvidia, Primer, and Snorkel AI before founding her own stealth startup last year—delivering data-driven insights with ML at the right time requires specific architectures. The most skilled engineers, like Huyen’s co-founder and former Netflix lead of stream processing Zhenzhong Xu, navigate by deeply understanding the link between data processing latency and the business objective, as illustrated below.
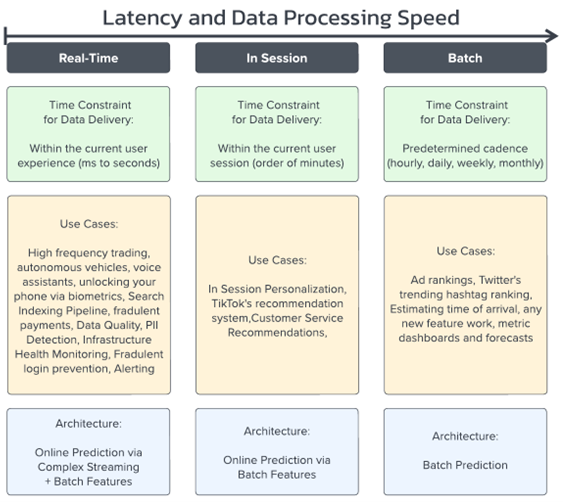
Figure 2: A broad organization of data architectures according to common types of data processing use cases.
Innovation in machine learning is moving away from batch prediction. Real-time machine learning demands faster correlations and predictions that can be achieved within a user’s session. Data must be processed to deliver customized experiences within less than a second (at best) or within minutes (at most).
The world of real-time data is all about moving small payloads of data as fast as possible in an explainable way. Deciding where and how to invest in real-time data technologies requires understanding streaming tools like Apache Pulsar, which brings us to our second point.
2. Solve hard ML problems with SQL and streaming technologies
Expert practitioners say that real-time ML is mostly an infrastructure problem. They also say you should only change so many moving parts at once. There are two adjacent groups of technologies that practitioners cling to as constants in this world of fast-paced change: data query languages and streaming technologies.
First up: SQL dominates as the production language of choice for querying and processing data. In other words:
“Put more bluntly: Sometimes we want to apply ML to problems better solved with SQL queries and ‘basic math.'” “How to tackle machine learning’s MLOps tooling mess,” by Matt Asay
Second, streaming technologies have moved into a more prominent role in machine learning infrastructure. In this world, the data store/database is falling out of the narrative in favor of stream transport (Pulsar and Apache Kafka, for example) and stream processing (Flink, Kinesis). We see similar themes in Gwen Shapira’s architectural recommendations.
While operational data stores drive user experiences, the industry is converging on streaming systems to drive near and real-time machine learning. Smart investments use data platforms that offer both operational and streaming capabilities via SQL or SQL-like languages.
3. Observability: Monitoring the system’s heartbeat
The move toward real-time machine learning will be successful only if it’s accompanied by observability into system behavior—for the entire end-to-end process. This isn’t far-fetched; we’re talking about data practitioners taking center stage in building infrastructure, after all.
The successful adoption of real-time machine learning will, like the success of distributed computing during the past decade, most likely be accompanied by improvements in observability. They’ll build on the foundations of tools like Grafana, Prometheus, and open tracing with advances in the technology and the practices.
Let’s revisit Zhenzhong Xu, who held a central role in developing Netflix’s stream processing architectures from 2015 to 2022. His lessons from system outages show the critical need for fast feedback loops about system performance when troubleshooting the latest production issues caused by a new ML model. It’s in these moments that data takes the main stage—it’s the only way to provide answers to a host of important questions:
- What do we expect to go right, when it goes right? How will we know?
- What do we expect to go wrong, and why?
- How often would we expect errors, and why?
- How will we want to be notified of those errors?
- How will we detect model performance?
- What can we know about model drift and when it’s time to deploy a new approach?
Teams that venture into production applications of machine learning are inevitably also investing in real-time telemetry—no one wants to fly blind. But all of this information is more than just telemetry; it’s the system’s very heartbeat.
That is, data that’s ready for real-time machine learning will be seen, measured, and understood at every step along the way. Investment in machine learning infrastructure is an investment in lineage tracking and traceability for continuous improvement and compliance.
Wrapping up
Innovation from within the machine learning industry is heading toward real-time capabilities for your data.
The problems that need to be tackled now lie at the intersection of composable stream processing, fast movement of small payloads, and explainable predictions. Data that is ready for machine learning will be observable, supported by real-time infrastructure, and primarily processed with streaming technologies.
For the near future, the language of choice will be SQL, and stream processing will take center stage. Successful teams will prepare for observability, as understanding these systems in real-time requires data about data.






