











Apache Kafka is a particularly powerful open source technology for real-time data streaming – and if you’re reading this, I probably don’t need to convince you that. But as you also might very well know, achieving and maintaining a Kafka deployment that is continually optimized for scale and performance requires diligent attention. For those leveraging Kafka to achieve digital transformation within their data layer, ongoing attention is critical to ensure the open source event streaming platform is doing what it does best across all your use cases.
As someone working with Kafka day in, day out, here’s how to ensure your Kafka deployment is on the right track.
Cluster level configuration and defaults
Log management
Log behavior should be customized to avoid management challenges. This means setting up a log retention policy, cleanups, compaction, and compression activities.
Log behavior is controlled using log.segment.bytes, log.segment.ms, and log.cleanup.policy (or the topic-level equivalent) parameters. Unless there’s a special use case for retaining logs longer on a per-topic basis, set cleanup.policy to “delete” to delete log files of certain file size or after a set length of time. When required, set it to “compact” to hold onto logs. Log cleanup consumes CPU and RAM resources, so balance compaction frequency with performance when using Kafka as a commit log.
Why compaction? Compaction ensures retention of at least the last known value for each message key within the data log for a single topic partition. The compaction operation also cleans up all key duplicates. In the case of deletes, the key is left with a ‘null’ value called a “tombstone,” denoting deletion.
Hardware requirements
By design, Kafka is low overhead and well-built for horizontal scaling, with no significant hardware or infrastructure requirements. Inexpensive commodity hardware can run Kafka quite successfully:
- CPU. Kafka operations generally aren’t CPU intensive unless SSL and log compression are required. A 2-4 core CPU can work well; more cores will improve parallelization. Where compression isn’t a factor, use the LZ4 codec for the best performance.
- RAM. In most cases, Kafka can run optimally with 6 GB of RAM for heap space. However, it’s best to allocate additional RAM. For production loads, use machines with 16-32 GB RAM (or more as required). Extra RAM bolsters OS page cache and improves client throughput. While Kafka can run with less RAM, its ability to handle load is hampered.
- Disk. Kafka’s sequential disk I/O paradigm doesn’t require quick access. SSDs work fine, as do multiple drives in a RAID setup, but NAS is not recommended.
- Network and filesystem. XFS and EXT4 Linux filesystems are recommended. Network throughput needs to support client traffic, and monitoring network IO and throughput helps to improve capacity.
Apache ZooKeeper
When using ZooKeeper alongside Kafka, it’s critical to follow proven best practices for optimized performance and reduced latency. While a developer environment can use a single ZooKeeper node, a production cluster should include three. Take the load placed on nodes into consideration – large Kafka deployments may call for five ZooKeeper nodes to reduce latency.
Also, provide ZooKeeper with as much network bandwidth as possible. To further reduce latency, use the best disks available, store logs separately, isolate the ZooKeeper process, and disable swaps.
Replication and redundancy
For a resilient Kafka deployment, proper management means everything. As a best practice for most production environments, increase Kafka’s default replication factor from two to three. This ensures that the loss of one broker – or even the unlikely loss of two – doesn’t interrupt availability.
Another consideration is data center rack zones. For example: if using AWS as your cloud of choice, Kafka servers should be in the same region but should be utilizing multiple availability zones to ensure redundancy and resilience.
The key Kafka configuration parameter for rack deployment is broker.rack=rack-id. As Apache Kafka documentation explains: “When a topic is created, modified or replicas are redistributed, the rack constraint will be honored, ensuring replicas span as many racks as they can (a partition will span min(#racks, replication-factor) different racks).”
The following diagram demonstrates an example with nine Kafka brokers (B1-B9) spread over three racks.
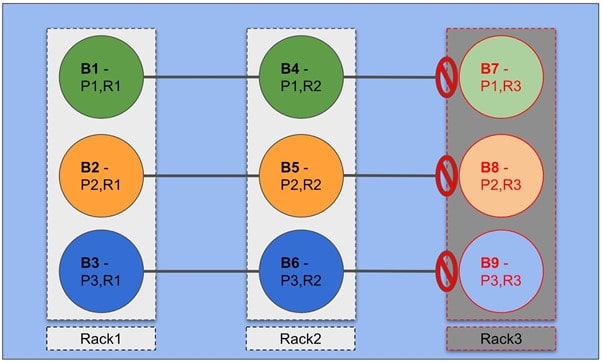
Here, a single topic with three partitions (P1, P2, P3) and a replication factor of three (R1, R2, R3) will have one partition assigned to one node in each rack. This scenario achieves high availability, with two live replicas of each partition (even when a complete rack fails).
Topic-level Apache Kafka optimization
Topic configurations tremendously impact Kafka cluster performance. Configurations should be set correctly from the beginning to avoid the need for challenging alterations. If changes are required, simply create a new topic. Always test new topics in a staging environment before moving them into production.
Use the recommended replication factor of three. To handle large messages, break them into ordered pieces if possible, or use pointers to the data. Otherwise, enable compression on the producer’s side. If messages are larger than the default log segment size of 1 GB, consider the use case and options. Partition count is a crucial setting as well (discussed below).
Topic configurations have a “server default” property that can be overridden for topic-specific configurations. This example creates a topic from the console with a replication factor of three, and three partitions with other “topic level” configurations:
bin/kafka-topics.sh –zookeeper ip_addr_of_zookeeper:2181 –create
–topic my-topic –partitions 3 –replication-factor 3 –config
max.message.bytes=64000 –config flush.messages=1
Continuously managing Kafka to maintain optimization means balancing trade-offs to achieve high throughput, low latency, high durability (ensuring messages aren’t lost!), and high availability. Kafka is also designed for parallel processing, and fully utilizing it requires a balancing act itself. Partition count is a topic-level setting, and the more partitions, the greater the parallelization and throughput. However, partitions also mean more replication latency, rebalances, and open server files.
To optimize partition settings, calculate the throughput you wish to achieve, then calculate the number of partitions needed. Begin from the estimate that one partition on a single topic can deliver at least 10 MB/s. Alternatively, run tests using one partition per broker per topic, check the results, and double the partitions if more throughput is needed. As a guideline, keep total topic partitions below ten and total cluster partitions below 10,000 (otherwise, challenging rebalances and outages will occur).
This example creates a Kafka topic with a set number of partitions:
bin/kafka-topics.sh –zookeeper ip_addr_of_zookeeper:2181 –create
–topic my-topic –partitions 3 –replication-factor 3 –config
max.message.bytes=64000 –config flush.messages=1
The below example increases the partition count after creation (this impacts consumers – do this only after addressing all consequences):
bin/kafka-topics.sh –zookeeper zk_host:port/chroot –alter –topic
topic_name –partitions new_number_of_partitions
Wrapping Up
Apache Kafka is relatively easy to get started with but can have some complexities to maintain if you don’t know what boxes to tick and what paths to avoid. Don’t let that scare you off; the benefits of Kafka are well worth the effort and critical to data-layer modernization. (And, of course, Kafka is open source and works incredibly well in its pure, 100% open source version – no proprietary or open core add-ons needed.) By carefully managing cluster and topic-level configurations – and balancing throughput, latency, durability, and availability in line with the needs of your application – a continually optimized Apache Kafka deployment is there for the taking.







