











Man, oh man, it is not the first time we’ve heard someone say, ‘ETL is dead,’ countered, of course by someone else saying ‘ETL is not dead, it’s even bigger than before.’ And the merry-go-round continues. Certainly, one thing is clear: Cloud data analytics is alive and well. Most recently, we have seen ETL begin to solve the problem of operational analytics in a serious way.
Data is useful, but its true value is only realized when it is made actionable. For years, organizations have used data transformation to clean and prep data for business intelligence and reporting. As organizations transition to a cloud-first approach for analytics, many have begun to explore their first data science projects to seek a competitive edge, to stand out from the crowd, to find that unique, previously-not-exploitable business insight to find lost treasure…you get the idea. Within modern data practices, we are beginning to see the last mile of analytics as operational analytics, where ‘insight meets action.’
See also: How Data Pros Turn Actionable Insights into Business Impact
The Promise of Operational Insights
Companies like Snowflake have turned the business / financial world on its head by delivering data analytics at tremendous scale and a fraction of the cost of yesteryear’s data warehouses –– going as far as to create a new category called Cloud Data Platforms. The ease of loading data from any source in a couple of clicks is commonplace. But, while everyone focuses on this newfound promise and the visual analytics that it brings, we’ve also started to see business demand to solve the ‘actionable insights problem.’
The end goal for businesses is no longer just about getting the data into a BI dashboard. Now, it becomes more about developing insights that can be pushed back into the business applications from whence it came. The analytics-ready data of the data platform, when synchronized back into the business layer, is quickly becoming the way by which an account executive sorts their customer call list, with new data attributes, such as a ‘propensity to buy score,’ available to them in the CRM. This shift is driving a revolution in the way we use ETL, moving from a tool mindset to a platform mindset, where a single investment in a data pipeline can deliver more than one outcome.
Beyond ETL…reversing it
Processes such as ones that perform Extract, Transform, Load (ETL) capabilities break down data silos and allow data scientists to more easily access and analyze data — and ultimately turn that data into those actionable business results. ETL has long been the necessary first step in the data warehousing process that lets you make more real-time changes and decisions.
However, data infrastructure has evolved rapidly and transitioned from traditional ETL to the new order of Extract, Load, Transform (ELT). ELT is a process where data teams pull data in its rawest form and load it into a data warehouse or data lake (often in the cloud) to be transformed to create a 360 view of a given data asset: be it customer, product, contract, employee, or patient. But even with ELT, many companies have hit a barrier with their important data being stuck in data warehouses, so they need yet another evolution of the process to break the cycle.
This process has advanced again in an effort to make data operational and achieve that greater business goal. However, this advance doesn’t end the use of ETL or ELT. They aren’t dead –– rather, they’re just reversing the flow.
Understanding Sync Back
The term “reverse ETL” — or operational data analytics in a modern cloud ETL approach — has been coined and is centralized around the idea of pushing curated datasets from the analytics environment back out to operational systems for real-time action or customer experience. This technique empowers data teams to easily prep bulk data, move it outside the cloud data warehouse, and operationalize it for their organization.
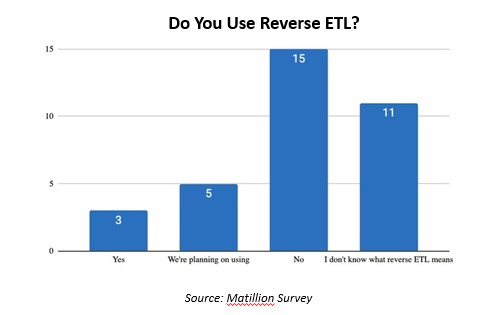
So what’s the big excitement around this? The workflow and operational analytics process allow business leaders and decision-makers to achieve truly actionable data and interact with customers and make changes that will improve their business more instantaneously. In a recent poll we conducted, 9% of customers say they are already using reverse ETL, and 15% say they are planning to. But 32% said they don’t know what reverse ETL is. Either some market education is required, or we need to think about the term itself.
As a term, “reverse ETL” doesn’t truly encapsulate the value of this motion. When enriched analytics data is synchronized back to operational systems, the extract, load, and transformation process is not just simply “reversed.” Instead, the results of all this upfront effort are spread further around the business into places where they are more accessible to daily decision-makers, even performing improvements to customer interactions with better matching to customer behaviors and preferences in real time.
“Sync back” takes the specific attributes from data that has been curated from the data platform and makes it actionable for business users by pushing this data back into the operational system. Essentially, sync back is an extension of ETL. By enabling the flow of data from the data platform to the people who actually need it, everyone in an organization is empowered to make better business decisions in the moment because the underlying systems feel smarter and are more context-aware.
In many cases, the business users aren’t even required to change how they work. It all just feels more natural, and it just works. For example, a hotel chain can glean more information about a customer than ever before, including their habits and hotel preferences. This innovation could help them revamp customer service efforts and cater to customer desires, generating more repeat business and beating out their competitors. Of course, synchronizing data to operational systems isn’t new; however, the lowering of the skill sets required in IT teams to deliver such use-cases has massively changed for the better with modern cloud ETL software.
Still, with enterprises moving more data into the cloud and adopting modern cloud platforms, data teams are under more pressure than ever to deliver analytics-driven insights across their organization. To create a smoother process for data teams, it’s important to have a single product to track the data being loaded and generate insight within the data warehouse. A single product also streamlines flow and ensures personal information is protected and not being widely shared.
Why should your business reverse the flow?
Why sync data back into the business? The short answer is to give the end-user a complete picture of the data within the app that they use every day. Currently, there’s a hole in what analysts and customers can view of the data, in particular with a software as a service (SaaS) app. This information gap leads to a segmented view of the customer. By reversing the flow of data, the world of data analytics and customer insights unlocks, and personalized insights become a reality. And business happens where the customer is.
As a real-world example, take a large enterprise that provides financial services software. The data team uses a cloud data integration platform to pull web traffic data into their cloud data warehouse and then prepares that data to be consumed by a machine learning algorithm, which then produces a lead score. The data integration platform then syncs this new insight into a CRM such as Salesforce so the sales team can prioritize accounts to focus on. Why Salesforce and not a business intelligence dashboard? Because Salesforce is where the sales team lives every day. This helps the organization get to insights quickly so they can act on information in near-real-time.
Achieve real-time actionable insights across industries
Since implementing sync back is similar to implementing ETL, organizations don’t have to start from scratch. In fact, some existing ETL tools already support reloading of data as well –– making the transition that much easier. In addition to supporting operational analytics and enhancing customer experiences, synchronizing back to operational source systems can amplify industries such as sales, marketing, customer service, and data automation.
Sales: Just like in the example above, using sync back to move customer data back to a CRM system can offer greater insight to amplify sales campaigns.
Marketing: In order for a marketing team to run more efficiently, campaigns –– specifically email campaigns –– should be automated to allow access to more personalized customer data. This, in turn, grants businesses better access to subscriber preferences so they can make real-time alterations to campaigns and generate meaningful results.
Customer service: Pulling information out of a data warehouse to make it actionable provides support people access to product usage data that can help them offer better customer service at any given moment. It also allows them to sync consolidated customer data into an existing support application to prioritize tickets better.
Data automation: Sync back can help automate the number of spreadsheets and report requests data teams get on a given day, allowing those teams to get some value back in their day to enable them to perform their jobs faster.
When the world’s workforce is backed with current, updated data, they can deliver a more seamless and personalized customer experience. No matter what cloud data platform or vendor organizations use, they can all benefit from a bi-directional ETL approach to get data insights out of cloud data warehouses faster and back into the hands of business leaders and decision-makers.
ETL is not dead. It’s even bigger than before.







