











Real-time applications, especially those that deal with streaming data, play a growing role in most organizations. Real-time applications are also becoming more demanding as they scale up in volume and encounter increasing business requirements for lower latency and more complex analytics.
Simultaneously, AI, especially generative AI, has been an intense area of focus for most organizations. These companies are keen to leverage the potential of AI on their corporate data – both structured and unstructured – which is continuously generated. Although most generative AI applications don’t deal directly with streaming data in real-time, a growing number of them do. Conversely, a growing number of real-time streaming applications use various kinds of AI as part of their business logic.
But what is the best software infrastructure for dealing with streaming data? The best-known high-volume, low-latency subsystems for handling streaming data are event stream processing (ESP) platforms such as Apache Flink. However, ESPs are only one of multiple alternatives for building real-time streaming applications, and the most effective solution depends on the requirements of the specific business problem.
In this document, Roy Schulte, Manish Devgan, and Sanjeev Mohan describe a relatively new kind of software platform for supporting demanding streaming applications called a Unified Real-time Platform (URP). We define how this new category is an evolution of event stream processing and introduce other elements of the platform, like a real-time data platform and real-time application enablement.
The real-time data management aspect of a URP provides low-latency access to data at rest (in memory or persisted), including some recent and past event logs, business data of record, and context data for analytics and enrichment purposes.
The real-time application enablement aspect comprises a programming model, design-time development tools, and run-time infrastructure for building real-time applications. This research explains the building blocks of a URP, the benefits it provides, and key use cases.
Introducing URP
URPs address the large set of use cases that require complex transformations and analytics on streaming data in motion and non-streaming data at rest. Some of the benefits of URP include the following:
- Take action on fresh data reflecting current events while accounting for related historical data at rest.
- Execute custom business logic and analytical functions, including ML inferencing on live data.
- Manage long-term reference and state data used in real-time applications.
- Deliver results with predictable, low latency at scale under varying loads by dynamically scaling (increasing or decreasing resources).
- Support both synchronous and asynchronous programming models – knowing that asynchronous offers better performance, responsiveness, scalability, resilience, and better resource utilization for many types of processing, although many other aspects of business applications must remain interactive and synchronous.
In a world overtaken by constant generative AI drum beats, the URP category has been growing exponentially and already has multiple solutions and technologies to build on. For many vendors, URP is an evolution of their previous ESP initiatives, but for others, it is a new category that makes it easier to implement high-value use cases.
Differences: ESPs, Data Platforms, and URPs
At the “10,000 feet high” level, URPs can be positioned relative to ESP platforms and real-time, streaming-enabled data platforms as follows:
Event Stream Processing (ESP)
ESP platform examples include Apache Flink, Confluent ksqlDB, Google Cloud Dataflow, Microsoft Azure Stream Analytics, Spark Streaming, TIBCO Streaming, and many others. They have played a crucial role in enabling certain real-time use cases that require complex, asynchronous, real-time transformations and analytics on continuous, unbounded data streams.
ESP platforms process sets of events (messages) from moving time windows (see here for a discussion of window types). Input data is usually ingested from messaging technologies (e.g., Kafka, Redpanda Data, Pulsar, Kinesis Data Streams, or Azure Event Hubs). The data is processed while it is “in motion,” i.e., without first being stored in a database (although ESP platforms incorporate internal, in-memory state stores that may be checkpointed and persisted for recovery purposes).
See also: Do You Need to Process Data “In Motion” to Operate in Real Time?
Processing logic is user-specified and is typically organized as Directed Acyclic Graph (DAG) pipelines that implement a sequence of operations that may incorporate filtering, simple aggregate operations (such as count, sum, or average), joins, sorting/shuffling, pattern matching or other operations. ESP platforms may be used to perform stream analytics for real-time business applications. Alternatively, ESP platforms are sometimes used to preprocess and condense streaming data to be loaded into a database (e.g., a data lake, lakehouse, feature store, or operational database) or fed into an analytics and BI platform (such as Microsoft PowerBI or TIBCO Spotfire) or a data science machine learning (DSML) platform.
ESPs can support high volumes of incoming data with very low latency, but they don’t provide many of the capabilities of a DBMS. ESP data is immutable (cannot be updated) and can only be appended through streaming operations. ESPs don’t provide efficient secondary indexing, flexible search capabilities, or complete data manipulation languages.
Streaming-enabled Data Platforms
Many modern data platforms, particularly in-memory DBMSs, in-memory data grids, time-series DBMSs, data historians, and some multimodel DBMSs, provide support for streaming data (we’ll defer the discussion of the relative merits of these different data managers for another day). At a minimum, this involves adapters that continuously consume data from Kafka or other messaging subsystems and an internal architecture that makes data quickly available to analytics tools or other applications.
Data platforms support data “at rest” in the sense that data has been stored before it is used. To reduce the time lag (i.e., latency) between the arrival of data and when it is processed by applications, data platforms may implement one or more optimizations:
- Operating in-memory (long term persistence is sometimes also supported)
- Deferring some or all indexing operations to background agents
- One-thread–per-core architectures (e.g., Seastar)
- Schemaless or schema-on-read data handling
Some streaming-enabled data platforms can scale to extremely high rates of data ingestion and can store up to petabytes of data so sheer volume is generally not a problem. Some examples of streaming-enabled data platforms include, in-memory DBMSs such as Aerospike, Materialize, memcached, Redis; time-series DBMSs such as Amazon Timestream, Aveva PI, InfluxDB, Microsoft Azure Time Series Insights, TimescaleDB; real-time, OLAP-type analytics DBMSs such as Clickhouse, Druid, Featurebase, Kinetica, Pinot, Rockset; and multimodel DBMSs such as Cassandra, Microsoft Cosmos DB, MongoDB, ScyllaDB and SingleStore.
See also: Beyond Kafka: Capturing the Data-in-motion Industry Pulse
However, streaming-enabled data platforms can’t, by themselves, provide the end-to-end low latency required by extreme real-time business applications because of the need to transform the incoming data before it can be consumed.
In common data architectures, raw incoming data is ingested into a “bronze” landing zone and then processed through multistep data engineering pipelines (e.g., through “silver” validation and then “gold” abstraction zones) to turn it into a form where it can be served to analytics or business applications. For near-real-time purposes, data pipeline transformations can be processed at frequent intervals through integrated frameworks such as Apache Spark or Snowflake Snowpark. However, multistep data pipelines that put data at rest several times in sequence are too slow for highly demanding ultra-low-latency real-time applications.
ESP with Streaming-enabled Data Platforms
An increasingly popular solution to this problem is to use an ESP platform in conjunction with a high-performance, streaming-enabled data platform. Developers use the ESP platform to implement a real-time streaming data engineering pipeline that processes and abstracts the data as it arrives (in motion). New data from the ESP platform is continuously stored into the data platform where it is immediately accessible to analytics and business applications.
Examples include Apache Flink (with RocksDB), Kafka Streams (with or without ksqlDB), or Spark Structured Streaming (with RDDs) in front of Aerospike, Redis, MongoDB, or other high performance data platform. This architecture requires significant design and engineering expertise but results in high-volume and low-latency systems because the data engineering pipeline is continuous and efficient.
Unified Real-time Platform (URP)
We finally get to see how a URP is an integrated and distinct category that overcomes some of the limitations of ESPs and streaming-enabled data platforms used separately or together.
URPs are integrated subsystems that combine most or all of the capabilities of an ESP and a streaming-enabled data platform into a single product. In addition, they also provide related application enablement facilities that go beyond the application hosting capabilities of a conventional ESP platform or data platform because a URP hosts both asynchronous, event-driven, streaming operations (like an ESP) and synchronous, request/reply operations (like a data platform).
Some URP vendors have literally taken an open-source ESP and integrated it with a high-performance data platform and application development tools to assemble their URP offering. However, more than half of the URP vendors that we have seen have built their URPs organically. For example, Gridgain started with an in-memory data grid and added streaming, analytical, and development features. Hazelcast also started from an in-memory data grid and then wrote its own full-blown ESP platform component (Hazelcast Jet). KX started with a column-oriented vector database and added more streaming capabilities, Python support, and a real-time analytics layer.
See also: Introducing the Data-in-Motion Ecosystem Map
URPs eliminate the need for architects to assemble, integrate, and manage their own ESP/data platform combination. This reduces the number of software products and (often) the number of vendors involved in a project and the time-to-solution.
URPs also minimize processing overhead and latency by tightly integrating the components (see Figure 1) into a single offering. URPs generally support higher volumes and lower latencies than most user-built ESP/data platform combinations, although this depends on the particular URP product and the application. Some of representative URP products (alphabetically) are:
- Axiros Axess ACS
- Cogility Cogynt
- Evam Actions, Evam Marketing, Evam Enterprise Cache
- GigaSaces Smart DIH
- Gridgain Unified Real-Time Data Platform
- Hazelcast Platform
- Joulica Customer Experience Analytics
- KX Kdb Insights
- Nstream.io Platform
- Pathway
- Radicalbit Helicon
- Scaleout Streamserver
- Scuba Analytics’ Continuous Intelligence Platform
- Snowplow Behavioral Data Platform (BDP)
- Timeplus Platform, Timeplus Cloud
- Unscrambl Qbo
- Vitria Via Analytics Platform, Vitria Via AIOps
- Volt Active Data
- ZineOne Intelligent Customer Engagement
Many others, especially the cloud service providers, have components that provide URP functionality but the runtime platforms appear to be less tightly integrated. However, they do provide an integrated developer experience which provides some of the benefits of the URP.
URP Components
The foundational elements of a Unified Real-Time Platform are shown in Figure 1.
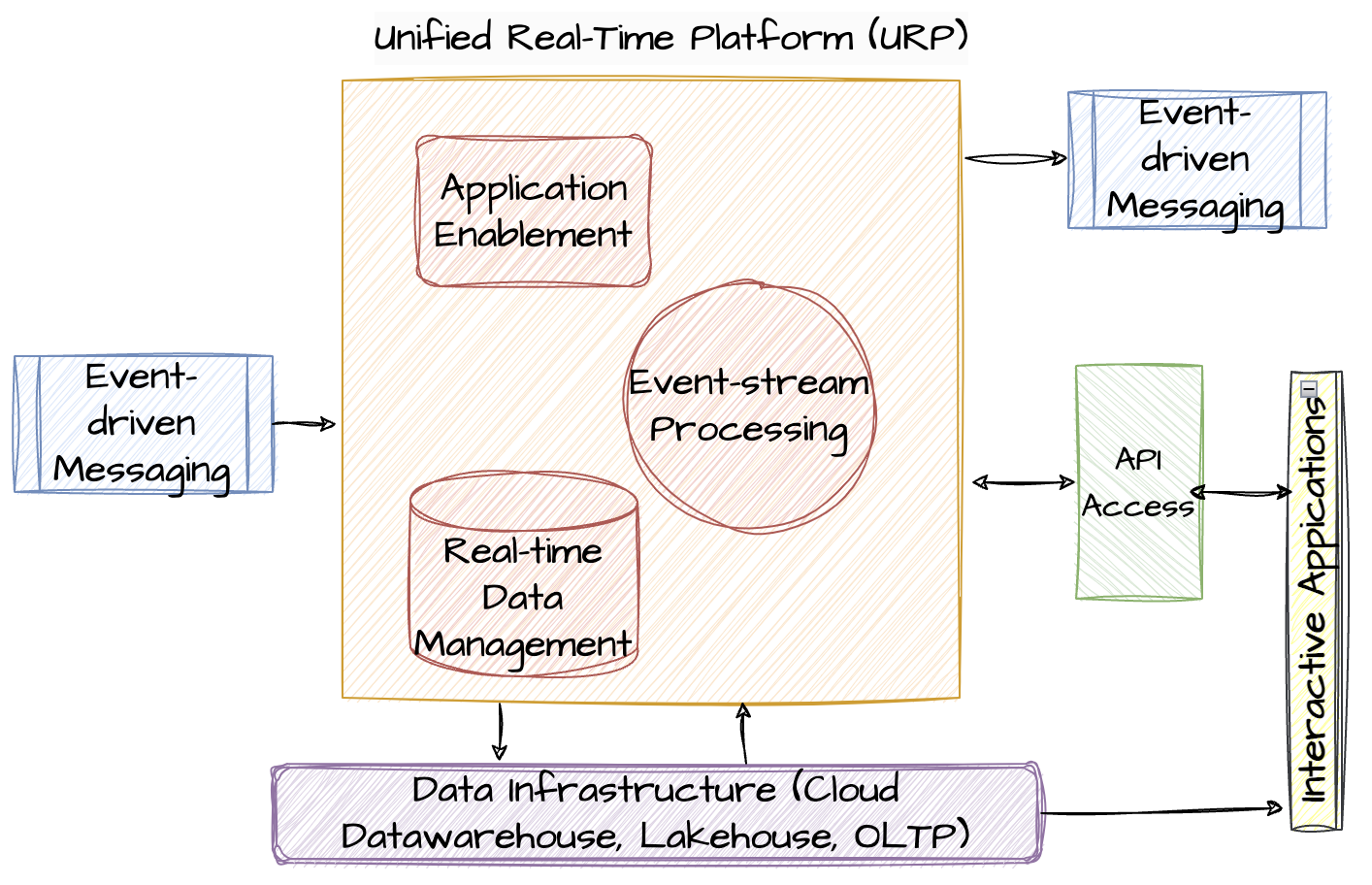
Figure 1: Building blocks of URP
The Real-time Data Management element of a URP manages recent and historical data-at-rest in memory and provides various strategies for persistent storage. The data usually includes transaction data as well as context data that supports real-time analytics, such as generative AI, other kinds of machine learning, and rule processing.
The Event-stream Processing element of a URP enables the continuous analysis of streaming data (events) as it is generated. A URP supports most or all of the functions of an ESP platform, depending on the product.
The Application Enablement element includes its programming model, design-time development tools, and run-time infrastructure for executing backend (data facing) business logic (e.g., user-defined functions) for transactions and analytical functions (e.g., ML inferencing).
See also: Perspectives on Real-time and GenAI Convergence
The table below shows the purpose in terms of customer outcomes of each component of the URP. Note that URPs demonstrate a wide range of internal architectures, with varied performance characteristics, programming models, and features. Although they are similar in the sense that they support these capabilities on a high level, the products are not interchangeable and do not serve the same applications equally well.
| Core Component | Customer Outcomes |
| Real-time Data Management | Low-latency data management at scale |
| Low-latency data querying/analytics at scale | |
| Real-Time (ML-based) predictions based on real-time data | |
| Event-stream Processing | Process streaming data and take action |
| Fast data transformation and movement | |
| Application Enablement | Faster time to market with ease of developing and taking real-time applications to production |
In conclusion, some of the core capabilities of the URPs include:
- The URP programming model must support parallelism by allowing operations on different portions of the data stream or data-at-rest to be executed concurrently for low-latency data access and efficient processing of data in motion.
- URP products include non-functional capabilities to configure, deploy, manage, monitor, and secure the URP infrastructure and applications.
- Users specify application logic in common programming languages, such as Python, SQL, or Java; domain-specific languages (DSLs); or UI toolkits. DSLs may simplify the development process at design time, enhance the expressiveness for debugging, and improve the control and reliability of the system.
- Many URPs support a dataflow programming model to build and configure real-time streaming pipelines that operate on data continuously flowing through the system to apply computations, including joins performed as the data arrives with another data stream or data at rest. URP pipelines are typically represented as DAGs where nodes represent processing units or operations and edges the flow of data between operations
- Some URP products also provide development and run-time capabilities for front-end (end user facing) logic for custom web, mobile, or other business applications or real-time dashboards.
- Some URP products provide purpose-specific templates and built-in functions for vertical or horizontal business applications such as customer engagement, supply chain management, financial services, or telecommunications.
URP Use Cases
Real-time applications transform conventional methods across industries. This section showcases examples spanning diverse verticals where real-time technologies are being harnessed. From finance to retail, transportation, entertainment, energy, telecommunications, security, industrial manufacturing, and software solutions, each sector is experiencing the significant advantages of real-time use cases.

Summary
Unified Real-Time Platforms (URPs) are a new category of software designed to handle demanding applications that deal with both streaming data (think constantly flowing data like sensor readings or financial transactions) and data at rest. They combine elements of traditional Event Stream Processing (ESP) platforms and real-time data management, while providing additional application enablement features into a single, integrated system.
As organizations scale up, the requirements for lower latency and more complex analytics on continuously generated corporate data become paramount. However, there is considerable confusion regarding the space of real-time streaming. In this document, we demystify the space and help both vendors and end-users understand the components of a URP so that customers can pick the right product aligned to their use cases.
The URP category is experiencing exponential growth, offering solutions that simplify implementation for high-value use cases and reduce the complexity of managing multiple software products.
This is the first document in an ongoing series. We plan to publish an evaluation criteria for URPs and compare various products at the architectural level and programming approaches.
About the authors

Manish Devgan is a seasoned product leader and innovator. He has successfully led the development of numerous software products at companies such as BEA Systems, Oracle, Terracotta, Software AG, and Hazelcast. Manish holds several patents and is a published author.

Sanjeev Mohan is an established thought leader in the areas of cloud, modern data architectures, analytics, and AI, and the author of Data Product for Dummies. Until recently, he was a Gartner vice president directing research for data and analytics. He has been a principal at SanjMo for over two years where he provides technical advisory to elevate category and brand awareness.

Roy Schulte is a former Gartner Fellow and co-author of the book “Event Processing: Designing IT Systems for Agile Companies”. He holds a BS and MS from MIT, and his recent work focuses on stream processing, real-time analytics, and decision intelligence.







