











It’s a data-driven world, and today’s companies are ingesting and leveraging more data than ever before. Data pipelines are becoming increasingly complex, with more inputs serving more users across the company. The ubiquity of data, and its widespread use across teams, leads to a delicate interplay between data teams and software engineers.
Data teams have several tools in their belt to manage data quality, such as data testing and data observability. However, there is also a need to go even further upstream to coordinate with the team members who most often generate a company’s data: software developers.
Today’s data teams rely on software systems and services that generate data, but they have little control or ownership over them–even when those systems are internal. That means when well-intended software engineers make upstream changes, they can unwittingly create downstream data quality issues (schema changes, duplicate data, missing data, broken pipelines—the list goes on) completely unbeknownst to the data team within the same organization.
So, what’s a data team to do? One emerging option that’s gaining steam (and buzz) is the data contract. When implemented thoughtfully, data contracts can enhance the relationship between data creators and data consumers and can make data more reliable and useful.
What are data contracts, and is implementing them the right choice for your organization?
See also: The 4th Shift in the Evolution of Finding Insights from Data
What is a data contract?
A data contract is an agreement between data producers (i.e., software engineers) and data consumers (i.e., data engineers) on how emitted data should be organized (its schema) so it can be reliably consumed by downstream data pipelines for its intended use.
The term “data contract” may be buzzy and new, but in practice, it should feel somewhat familiar. The data contract is not dissimilar from the Service Legal Agreement (SLA) used in other areas of the business, which details both what a customer can expect from a service provider and what happens if the service provider doesn’t meet those expectations. Instead of outlining the details of services, data contracts delineate agreements between data producers and consumers regarding the schema and semantics of data.
How data contracts work
Data contracts are a nascent practice, and as such, there is no standard solution or architecture. However, these architectures do have some similarities.
They typically have a mechanism allowing data engineers or data consumers to express their data requirements and schema. A data pipeline and underlying infrastructure is then built to those specifications, ideally with as much automation as possible. That pipeline has some sort of enforcement mechanism, perhaps a Kafka schema registry or dbt test, to ensure the data flowing through it matches expectations. There is also usually a mechanism for decoupling the operational database from downstream systems.
When does it make sense to implement data contracts?
The simple answer to this question is, “When it’s better to have no data or delayed data than to have bad data.” In other words, your most critical production-grade pipelines.
This is because data contracts, by design, prevent data from flowing into the warehouse when there has been an unexpected schema change. For some processes, like dashboards that are refreshed daily, it may make more sense for data teams to detect and fix those broken pipelines as they occur rather than to enforce a contract. In other cases, such as data provided to customers, it will be more important every effort is taken to prevent any data incidents from occurring.
Before embarking on a data contract process, you will also want to ensure that you’ve covered the data basics of ingestion, orchestration, and data observability.
What does a data contract look like?
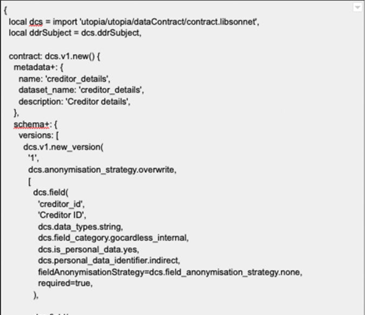
An example of an abridged data contract in JSON. Courtesy of Andrew Jones
A data contract can start its life as simple as a spreadsheet with the name of the dataset, schema requirements, and semantic meaning as columns. Contracts are then typically expressed within an IDE in a language like JSON or AVRO.
Data contracts are bespoke agreements between data producers and consumers at a given organization, and as such, each data contract is unique. There are, however, certain common characteristics that various data contracts used for various purposes might contain. These features include the following information:
- The type of data being extracted
- The type and frequency of data ingestion (i.e., real-time, batch, or lambda architecture-based ingestion)
- Details of data ownership/ingestion, whether individual or team
- The levels of data access required
- Information related to security and governance (e.g., anonymization)
- Any system(s) that ingestion might impact
What are the drawbacks of data contracts?
It’s not enough to have the enthusiasm of the data team in establishing data contracts: it’s also critical to gain buy-in from the software engineering function. To a data team member, establishing sound agreements that govern data use and management may sound like a no-brainer, but it can be challenging to bring software engineers—who may be wary of additional rules and systems that slow down their work—aboard. Before an organization can leverage data contracts effectively, it first needs to ensure that all involved parties understand the purpose of the task.
Data contracts can also have similar drawbacks to data testing. It is difficult for both data producers and data consumers to anticipate what data should look like. It is also difficult to then codify, manage changes, and enforce that understanding at scale. This is one of the reasons focusing data contracts on the most important, production-grade pipelines are such a critical task.
What’s next for the future of data contracts?
Data contracts are a tool du jour among modern data teams. But what’s next for this relatively nascent trend?
Will they lose steam?
While the potential of data contracts is high, the obstacles that bar the path to their widespread adoption are real. Communicating the value of data contracts to half of the interested parties is difficult—and could be prohibitively challenging at scale.
The success of data contracts is often predicated on relationships, alignment, and communication between data and software teams. Going forward, will data and software teams be able to align priorities and overcome the upfront hurdles that stand in the way of data contract adoption?
Ironically, the same obstacles that threaten data contract implementation—i.e., trepidation over more complicated processes—could be solved by a data contract process. Instituting a more comprehensive process that endows various teams with more autonomy and makes data access easier and more reliable can solve organization-wide issues if all constituents can see the value in that process.
Will they grow in adoption?
As companies increasingly treat data like a product, the use of data contracts could proliferate. Indeed, implementing data contracts within various types of data architecture—especially certain types of decentralized data architecture—makes sense. As data grows in value, it’s helpful (and necessary) to implement new tools and systems to stop issues before they even occur in order to keep data pipelines running smoothly.
Certain companies, including GoCardless and Convoy, have already pioneered the data contract approach. GoCardless, for example, set out on an extensive intra-organizational communication tour before instituting data contracts with the aim of mitigating upstream data quality issues. Convoy uses data contracts as an integral part of its data warehouse maintenance process.
Are data contracts right for you?
Data contracts may soon be a common feature of the modern data organization. As more users across more departments use more data for more purposes, it becomes ever more important to ensure the quality and reliability of that data at every step of the data pipeline. And as every company becomes a data-driven company, the responsibility for the data that fuels operations extends beyond the data team.
Data contracts are one tool in a growing arsenal of solutions to data-related challenges that threaten to hold modern businesses back. When implemented thoughtfully with buy-in from all constituents, data contracts can offer an important step into the future.







