











Machine learning engineers have grappled for decades with the challenges in managing and automating ML pipelines to speed up model deployment in real business applications. Increasingly, businesses are turning to Continuous Integration and Continuous Deployment (CI/CD) and other methods to help.
Much like DevOps, which software developers leverage to increase efficiency and speed up release cadence, MLOps streamlines the ML development lifecycle by automating manual tasks, breaking down silos across ML teams, and improving the quality of ML models in production while keeping business requirements central to every project. Fundamentally, it’s a way to automate, manage, and speed up the very long process of bringing data science to production.
See also: 4 Real-Time Data Analytics Predictions for 2021
Data scientists have recently started to adopt a paradigm that focuses on building “ML factories,” an approach that increases efficiency by automating ML pipelines that take data, pre-process it, then train, generate, deploy, and monitor models.
But deploying models to real-world scenarios is complicated: the code and data change, causing drifts and compromising models’ accuracy. ML engineers often must run most or all the pipeline again to generate new models and productionize it. Each time the data or codebase changes (which is often), they do it all again. This is the major problem with building ML models without MLOps. All the complexity of manual work incurs significant overhead because data scientists spend most of their time on data preparation and wrangling, configuring infrastructure, managing software packages, and frameworks.
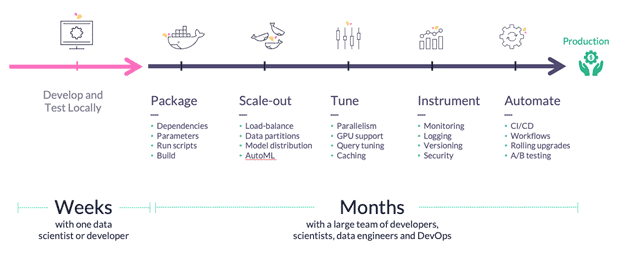
In DevOps, the twin development practices of Continuous Integration and Continuous Deployment (CI/CD) enables developers to continuously integrate new features and bug fixes, initiate code builds, run automated tests and deploy to production, which automates the software development lifecycle and facilitates fast product iterations.
It is fairly simple to implement CI/CD in DevOps environments: code, build, test, and release. It is far more complicated to apply these practices to ML pipelines and presents several unique challenges. Data, parameters, and configuration versioning are aspects of ML development that require the use of powerful resources (data processing engines, GPUs, computation clusters, etc.) to execute.
Due to the inherent complexity in creating, running, and tracking ML pipelines, data scientists and ML engineers now automate MLOps the CI/CD way.
Yet MLOps is more complicated than traditional DevOps due to:
- Tight coupling between the data and the model
- Managing data, code, and model versioning
- Silos create friction between data engineers, data scientists, and engineers
- Skills mismatch: Data scientists are not often trained engineers and thus do not always follow good DevOps practices
- Burdensome processes to identify model drift and trigger a pipeline for retraining the model
- A lack of automation to manage manual work
- Difficulty in migrating ML workloads from local environments to the cloud
These complexities require a robust platform capable of incorporating CI/CD principles into the ML lifecycle, thus achieving true MLOps.
CI/CD helps to accelerate and improve the efficiency of workflows while decreasing the time it takes data scientists to experiment, develop, and deploy models into production for real business applications.
A proper MLOps process by definition should ensure CI/CD for data and ML intensive applications. But a strong CI/CD system is critical to this process. It should understand ML elements natively, and it also must remain in sync with any changes to underlying data or code, regardless of the platform on which the model runs.
ML engineers aiming to truly automate ML pipelines need a way to natively enable continuous integration of machine learning models to production.
Implementing CI/CD for ML and MLOps with Github Actions
The wide variety of platforms designed to implement CI/CD and automate builds in software development environments provides developers with lots of flexibility when building DevOps pipelines.
But Data scientists are very limited in this space due to the lack of interoperable tools for properly versioning, tracking, and productionizing ML models.
Several services can incorporate CI/CD into ML pipelines. Still, they place data scientists into a black-box silo situation so that they must build, train, track, and deploy within a closed technology stack.
Existing open-source systems that offer such functionality may not always play nicely with the platforms and tools data scientists prefer, thereby necessitating customized deployment tools or embarking on a steep learning curve to work with unfamiliar tools.






