











The global pandemic of 2020 has upended social behaviors and business operations. Working from home is the new normal for many, and technology has accelerated and opened new lines of business. Retail and travel have been hit hard, and tech-savvy companies are reinventing e-commerce and in-store channels to survive and thrive. In biotech, pharma, and healthcare, analytics command centers have become the center of operations, much like network operation centers in transport and logistics during pre-COVID times.
While data management and analytics have been critical to strategy and growth over the last decade, COVID-19 has propelled these functions into the center of business operations. Data science and analytics have become a focal point for business leaders to make critical decisions like how to adapt business in this new order of supply and demand and forecast what lies ahead.
In the next year, I anticipate a convergence of data, analytics, integration, and DevOps to create an environment for rapid development of AI-infused applications to address business challenges and opportunities. We will see a proliferation of API-led microservices developer environments for real-time data integration, and the emergence of data hubs as a bridge between at-rest and in-motion data assets, and event-enabled analytics with deeper collaboration between data scientists, DevOps, and ModelOps developers. From this, an ML engineer persona will emerge.
1) Hyperconverged data management and analytics
Visual analytics, data science, data management, and AI-enabled business processes are colliding as the quest for business optimization accelerates. This is being accelerated by the global pandemic, forcing many enterprises into a swift digital transformation. AI engines and software suggestion systems are enabling this convergence – bringing automated and low code data prep and machine learning into BI, analytics, data science, business process, and app-dev working environments. Automating routine tasks frees up time for innovation and business optimization, allowing humans and AI-automation to work together efficiently.
The convergence of data management, analytics, data science, and DevOps will accelerate in 2021 and beyond, incorporating elements from cloud vendor services along with open-source and homegrown tooling. This will make it easier to implement end-to-end workflows and develop event-enabled business solutions in hybrid cloud environments. This hyperconvergence will also drive a need for broader data literacy, which is becoming critical across all business functions. The most efficient businesses in 2021 will be those that work to improve data literacy across functional areas and organization levels while embracing the convergence of data management, analytics, DevOps, and business process technologies in event-enabled environments. The result will be rapid and ongoing development of AI-infused apps, along with deployment and management of data science technologies in business operations.
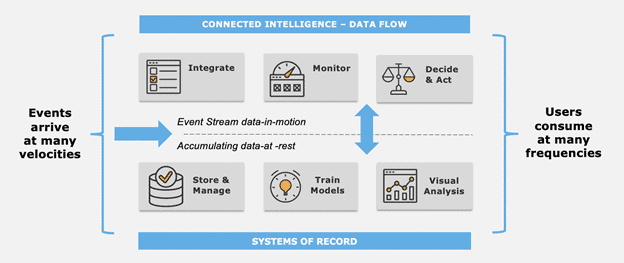
2) Creative combinations of in-motion and at-rest data
All data begins as business events that arrive at many velocities. Event-enabled companies integrate data on event streams, monitor trends, make decisions, and take actions on real-time data-in-motion. Modern businesses also accumulate data from event streams into at-rest data systems, where they train predictive models and create visual analytics applications for business strategy, tactics, and operations. Users consume these analyses at many different frequencies.
Going forward, we will see a combination of data-in-motion and data-at-rest feeding closed-loop, self-learning systems in operations. Specifically, I see a downtick in solutions that involve moving data and an uptick in solutions where data are analyzed directly on the event stream, within delegated cheap storage systems, and in fluid combinations of the two. According to IDC analyst Dan Vesset, “exciting use cases are in analyzing data from moving and stationary ‘things.’ We’re still in the early days of developing intelligence about the physical world.”
3) The emergence of data hubs as a bridge between hybrid data assets
As multi-cloud, AI-infused apps continue to drive value on the front lines, rolling updates from multiple disparate sources are fueling the underlying data. As a result, I see advances in data hub technologies for bridging cloud and on-prem data assets, transforming individual sources of data via cloud integration services like AWS Lambda and TIBCO Cloud Integration, and injecting real-time data to drive situational awareness. Master data management and data virtualization are key technologies for managing and bridging data assets with secure access across hybrid cloud environments for at-rest and in-motion data sources.
Ulta Beauty is providing real-time personalized experience, accelerated customer service, loyalty, and order updates with immediate data updates across all channels. Use cases like BOPIS (buy online pick up in-store) and curbside pickup are enabled by a responsive app mesh architecture where inner APIs abstract legacy data. Outer APIs surface shipping, customer, and inventory APIs for real-time customer experience.
Early on in the pandemic, Norton Healthcare mobilized an analytics command center for their medical records system Epic and operational systems for hospitalizations (including PUIs), testing, capacity, utilization, ventilators, and all healthcare services and operations. Norton pulls data in real time to refresh the apps, giving them a wealth of up-to-date information to monitor hospital operations and the pandemic effects. Additionally, Norton opened new telehealth lines of business while recasting equipment supply chains to protect health workers on the front lines.
As the business economy reopens and social behavior moves to new states of normal, we will see new ad-hoc data combinations come to fruition. For example, we will see real-time analytics on health status, building access and occupancy, crowd density, and network evolution to meet new business operations processes.
In all of these applications, master data management and advanced data virtualization will be key underlying technologies, combining at-rest and real-time data sources to continuously update critical analyses with governed access and security. I predict a confluence of data virtualization, data catalogs, and master data management systems to keep data and AI applications in order and to scale the merge of real-time and at-rest systems. In combination with the API-led microservice mesh, this will accelerate the rise of new high-value business applications in the COVID and post-COVID era.
4) The convergence of data science with DevOps, ModelOps
Working from home has accelerated collisions and collaborations between teams of data scientists, DevOps, and ModelOps developers to manage data science apps in production environments.
This convergence will accelerate as ModelOps continues to grow as a discipline. As a direct result, a new machine learning engineer persona is starting to emerge. In their role, they configure deployment scenarios in hybrid cloud environments, working with data scientists, data engineers, business users, DevOps, ModelOps, application development, and design teams to manage deployments, monitor and update data science workflows in production environments.
Deploying and managing models in production environments is a non-trivial exercise. To quote British statistician George Box, “all models are wrong, some are useful.” Models bring risk, and that risk needs to be managed. Unintended consequences can be significant. For example, if a model calls credit risk incorrectly, real money and reputation risk is at stake. Model robustness and deployments that track bias, provenance, and usage, along with rules-based systems that provide guard rails around interpretation and action, is critical. Model explainability is also important, as is adherence to the ever-accelerating set of regulatory guidelines from CCAR, CECL to CCPA, and emerging EU regulations on trustworthy AI.
ModelOps includes many components, including data preparation, data versions, quality checks, feature engineering, labeling, to name a few. We will see considerable evolution in this area as the data science to DevOps handshake adaptively radiates across business functions and applications. From regulated environments in financial services and healthcare to the more fluid worlds of tech and martech.
The future of real-time analytics
Advanced data management and analytics will be key to surviving and thriving in 2021. We will see a convergence of data management, analytics, data science, and real-time systems enabling new automated and self-learning solutions for real-time business operations. We’ll see data hubs emerge as a bridge between in-motion and at-rest data. We’ll see data scientists, app developers, DevOps, and ModelOps worlds collide and converge. Though the near-term future state of business and travel remains uncertain, we can confidently predict the ongoing central importance of data management and analytics as input to real-time connected experience systems while continuing to uplift in data literacy across all business functions and levels.







