











Structured and unstructured streaming data are ubiquitous – we just don’t realize it. From data continuously streaming from phones to sensors gathering and streaming data, CCTVs everywhere, streaming data is zooming by all the time. Streaming technologies are being leveraged by organizations across different verticals, like supply chain, eCommerce, cybersecurity, and many more, to harness this flowing data and derive the right insights at the right time and place.
Types of Streaming Solutions in the Market
Streaming is a rapidly growing space with multiple solutions and vendors with overlapping capabilities. The landscape can be confusing with terms like “streaming platforms,” “stream processing,” “streaming databases,” and “streaming libraries.” The different solutions are briefly discussed below.
- Streaming platforms, like Confluent, AWS MSK, and Azure Event Hub, are an all-encompassing end-to-end platform that decouples data producers and consumers, buffers data, and enables ingestion, processing, and analytics.
- Stream processing engines, like Apache Flink, Apache Samza, Apache Storm, Apache Heron, Spark Structured Streaming, Amazon Kinesis, Google Dataflow, and Azure Stream Analytics, have streaming processors to read events from streaming platforms, transform and feed to consumers or write back to streaming platforms.
- Streaming databases allow immediate processing of flowing data to provide the results of pre-determined queries. They provide high throughput data ingestion and querying with a larger context window as compared to stream processing frameworks. It provides a unified abstraction where streams and tables are a converged concept, with the stream being an unbounded table with an interface. These databases can replace streaming engines and serving systems and leverage incrementally updatedmaterialized views for processing. They treat storage as a first-class citizen and store intermediate results with timestamps for observability and traceability for strong consistency guarantees. Examples include ksqlDB, Materialize, and Rising Wave.
- An emerging category is real-time OLAP engines for serving high query/sec (QPS) for high concurrency, low latency applications using a scatter-gather pattern for query execution. Examples include Apache Druid, Apache Pinot, Clickhouse, Rockset, and StarRocks.
- A stream processing library is a package plugged into a streaming platform for processing. It provides a programming model to build stream solutions with streaming operators. They integrate with the streaming platform on which they are deployed. Examples include kSQL, IBM Streams, Akka Streams, Faust, and others.
See also: 12 Streaming Analytics Solutions to Consider in 2024
Characteristics & Challenges of Streaming Solutions
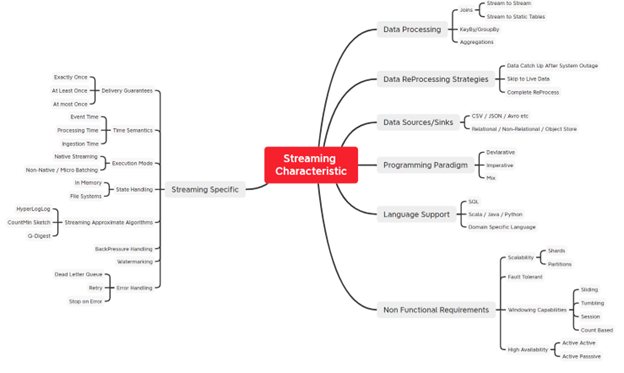
Some of the defining characteristics of streaming data include immutability, arriving out of order and with an unpredictable pattern, and non-determinism. This makes working with streaming systems challenging. Because of the changed paradigm in streaming, where data flows continuously and queries are static, it requires architects and developers to comprehend new concepts, like watermarking, windowing, back-pressure handling, delivery semantics and guarantees, state management, and the ability to keep up with unpredictable workloads and patterns to handle duplicate and missing data. Understanding, developing, testing, and operationalizing streaming systems has a steep learning and adoption curve.
Streaming systems need to be resilient to failures across data tiers, systems, hardware, and software to ensure graceful recoverability, consistency, and correctness across different failure scenarios. Streaming data is unrecoverable unless buffered within a given retention time. Hence, streaming platforms need to address single points of failure and incorporate capabilities like checkpointing to recover from failures.
Testing streaming solutions poses challenges in simulating scenarios spanning general and edge cases within and across data centers. Operationalizing streaming solutions and setting up fault-tolerant environments present additional challenges from the right sizing and tuning for optimal performance across diverse workloads.
Figure 1 shows a mind map of major characteristics across the different categories of streaming systems.
Criteria for Selecting Streaming Solutions
Due to the inherent complexities in streaming systems, it is important for enterprises to keep things simple and not over-engineered and select the right tools, frameworks, and platforms that abstract away the associated complexities. Note that not all streaming solutions support characteristics, as shown in Figure 1.
Streaming solutions are not a good fit for hard real time use cases when there is a need for single-digit milli-second end-to-end latency. Streaming solutions are also not a good fit where accuracy is critical, like accounting use cases. Before embarking on building streaming solutions, organizations must have a clear understanding of the technologies available, their strengths, and limitations and correlate them with functional use cases and requirements.
Streaming components do not exist in isolation, more so in today’s disaggregated data ecosystem. It is wise to choose solutions that integrate with other tools and frameworks in the ecosystem. Organizations must know where a streaming solution is going to be useful – in data integration, stream processing, or streaming analytics – and, based on that, decide what kind of solution is most appropriate.
As enterprises see a growth in the adoption of streaming across a range of use cases, criteria like disaster recovery – RTO (Recovery time objective), cross-data center and multi-cluster access, and data sovereignty need to be carefully evaluated and assessed. It is important to outline non-functional requirements (NFRs) like uptime SLAs, desired ingestion throughput, concurrency, end-to-end latency in percentiles, disaster recovery strategy, enterprise support, and SLAs around cloud services across all the use cases.
Streaming platforms are complex, with lots of interdependent tuning and performance knobs, which require a deep understanding of distributed systems architecture. Organizations are advised to perform performance benchmarks with their workloads and correlate them with vendor and publicly available benchmark results. Stream processing engines like Spark and Flink should not co-exist on the same cluster as the streaming platform, and this increases end-to-end latency due to network overheads.
Other questions architects and engineers should ask include:
- Does the solution let data producers and consumers interact using single or multiple protocols – this is especially important for interoperability in larger organizations where streaming solutions need to integrate with legacy and older systems in place and with cloud services.
- Does the solution make it easy to ingest, integrate, combine, enrich, and connect data across multiple systems?
- Can the solution replay the sequence of events within a window context and preserve the order of incoming events (if that is a strict requirement for the business)
- Can the solution guarantee event delivery with no data loss with an adjustable RPO (Recovery Point Objective)?
- What are the throughput constraints and elastic scalability capability based on workloads?
- Can the solution be deployed across cloud providers and on-premises?
- What kind of data governance is available – from securing data at rest and in transit to multi-tenancy, schema management, lineage tracking auditing, and metadata management?
Streaming skills are difficult to find, and streaming developers are some of the highest paid in the industry. Enterprises need to take stock of what kind of skill sets are available in-house and how they can be up-skilled or bring in external help with streaming development, testing, and deployment. Technical POCs and NFR (non-functional) capabilities are critical aspects to be assessed along with licensing, TCO, and customer and community support before choosing a solution.
Conclusion
The streaming landscape is littered with failed technologies. It is therefore imperative for organizations to carefully evaluate and select streaming solutions. Over the last few years, streaming solutions have matured to enable rapid development and deployment, which minimizes the learning curve and abstracts out deeper technical details required to build and operationalize. These tools, though, considerably reduce the configurability and flexibility, and organizations need to weigh the pros and cons before selecting a solution.






