











Escalating public cloud costs have forced enterprises to re-prioritize the evaluation criteria for their cloud services, with higher efficiency and lower costs now front and center.
The highly elastic nature of the public cloud means that cloud services can (but don’t always) release resources when not in use. And services which deliver the same unit of work with higher performance are in effect more efficient and cost less. In the on-premises world of over-provisioned assets, such gains are hard to reclaim. But in the public cloud, time really is money.
See also: DataOps: The Antidote for Congested Data Pipelines
Data lakes on the cloud: How did we get there?
After the emergence of “Big Data” in 2005, it became almost impossible to handle the amount of data being produced using traditional SQL tools. Data-driven enterprises were introduced to the concept of the data lake along with processing and SQL engines as fundamental technologies to locate, process, and analyze data on a massive scale.
Platforms like Hadoop provided enterprises with a way to keep up with big data without breaking the bank. This meant that any company, regardless of its size, could emphasize the use of data to enhance decision-making processes, opening the door to big data analytics.
These on-premises big data solutions posed several challenges with regards to efficiency, complexity, and scalability. When building on-premises infrastructures, companies immediately became responsible for spinning up servers, dealing with outages and downtime, and also managing the software side, which required engineers to handle the integration of a wide range of tools used to ingest, process and consume data.
Aside from the upfront investment needed on storage and server equipment, on-premises data lakes were not flexible. If users wanted to scale up to support more users or more data, they needed to manually add and configure more servers, often resulting in over-provisioning costly environments or under-provisioning and compromising performance.
Enter “The Cloud,” a term used to describe hosted services available on-demand over the internet. Cloud computing promised and delivered a way for enterprises to have access to elastic and easily scalable processing and computing power that otherwise would be too expensive to implement and scale on-premises.
There are many reasons why cloud became the go-to platform for data lakes. First, the flexibility of their pay-per-use model allowed companies to expand or shrink the resources needed on-demand, based on their analytics workloads. Second, they no longer had to pay for maintaining hardware and keeping it up to date. Cloud technologies also provided a way to decouple compute from storage, allowing users to use engines to process their data while leaving it where it resides. Last but not least, leveraging the security, governance, and data availability provided by cloud vendors became part of companies’ data strategies.
The flexibility to increase compute capabilities to virtually infinite levels meant that enterprises had the ability to analyze massive amounts of data as fast as they wanted (and could afford given the associated increased cost). Data has a competitive edge, meaning that the success of the vast majority of companies depends on data and how fast they can analyze it. Cloud provides the winning platform, but performance comes with a price tag.
Shifting focus from performance to efficiency
Data sources are becoming increasingly cloud-based. IoT, manufacturing, social media, communications—all of these industries have cloud modernization programs in place that leverage the power of the cloud to store and analyze data. However, a large percentage of enterprises are realizing that the price tag of moving to the cloud can get pretty high, and are looking to implement cost controls.
Up to this point, static on-premises solutions drove companies that have made upfront investments on data lakes to focus on performance in an effort to make the most out of their current investments, especially when it comes to analyzing data. Big data analytics can be resource-intensive; ideally, in the cloud, if users want faster results, they can simply throw more computing to the tasks that they are executing. The caveat is that as performance increases, it becomes more challenging to keep your monthly cloud bills in check.
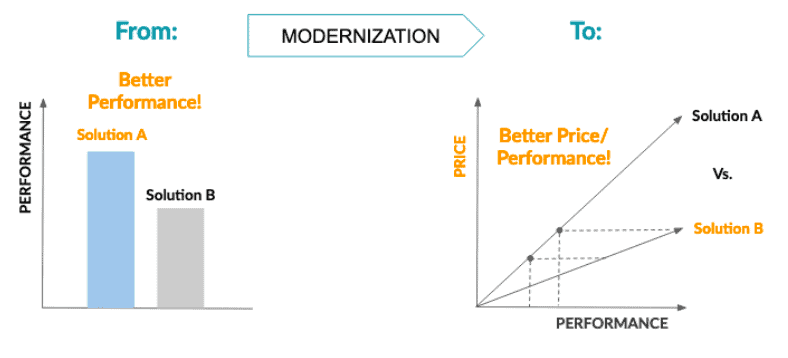
In the traditional cloud-performance benchmark approach, there can be two or more scenarios, but we will focus on the most common one: “A/B testing.” One of the many advantages of cloud computing is that users can test different solutions and pick the one that suits them the best. In this scenario (left chart), all that is measured is performance. Solution A’s performance is much better than Solution B’s. But that does not tell us the full story. The question organizations are starting to ask is: how much did that performance cost me?
In an effort to modernize their cloud infrastructure and gain control of their variable costs, we see companies shifting their attention to how different solutions scale performance along with cost. In this scenario (right graph), we see that Solution B is able to reach the same levels of performance of Solution A but with a much more efficient cost balance.
Performance, efficiency, and the role of elasticity
Implementing and maintaining big data computing and storage on-premise forced users to have to provision resources for peak use. The problem with that approach is that often, resources are not used at maximum capacity, leaving users with idle hardware.
There is a similar challenge with the current state of the cloud; the nature of analytics workloads is ever-changing, which makes them unpredictable and hard to estimate. When deploying data analytics solutions on the cloud, it is not uncommon to see these solutions handling all the workloads from all different teams in the organization. The nature of the teams using cloud resources is dynamic as well; enterprises can have financial analysts running light queries against data during office hours, while data engineers may have a resource-intensive data transformation job scheduled to run for a few hours every night.
To avoid slow performance in scenarios like this, it’s normal for users to find themselves over-provisioning their cloud deployments, which means they have to pay for cloud resources they’re not using. However, since the performance is needed at certain peak times, it is not viable to simply hit the brakes on resources, since this will sacrifice performance.
The good news is that there is a new battleground being paved for cloud services in 2020, where elasticity plays a big role as a solution for dynamic workloads. To put it simply, cloud elasticity refers to the process where cloud providers put systems in place to add/remove resources automatically, in order to provide the exact amount of assets required for the current task. Examples of such tasks include handling user traffic surges on Cyber Monday, performing database backups, or running a sentiment analysis algorithm. With cloud elasticity, users don’t waste money on resources that they don’t need.
4 key elements for efficient data lakes
The decoupling paradigm offered by cloud vendors is one of the best things that could happen to big data analytics. Separation of computing and data-enabled users to run processing engines in the data lake to work with data, however, they wanted. This separation also means that organizations can realize greater flexibility, greater analytical capacity, and greater financial viability.
Users have the advantage of running Spark jobs on EMR, leveraging data lake query engines to power business intelligence workloads, or use data science engines to do machine learning, all on top of the same data while it remains in its original location.
To successfully tackle the performance and cost balance in big data analytics, enterprises will need to leverage processing engines that provide the following key elements:
Workload isolation and maximum concurrency: This element will allow analytics teams within the organization to run their tasks directly on cloud storage without resource contention. Implementing elasticity within the processing engine is paramount to obtain full control over processing costs.
Tailored sizing: One of the main challenges of processing data on the cloud is finding the sweet provisioning spot. Enterprises often plan for peak points in their timeline (launch of a new product, end of fiscal year, etc.). As a result, during low demand times, all those resources remain idle while still accruing costs. By being able to dynamically size processing engines for each workload, enterprises can ensure full performance at optimum cost efficiency for each scenario.
Elastic scaling: Elasticity is a powerful concept that can be leveraged on processing engines, enabling users to take advantage of cloud vendors’ virtually infinite capacity to independently scale workload engines. This ability is key to optimizing deployments for high concurrency; enterprises can now automatically eliminate resource consumption and the high cost of idle workloads.
Bottom line
The ever-increasing size and volume of data that enterprises had to deal with not too long ago pushed them to adopt data lake solutions that would allow them to harness value from that data. Technologies like Hadoop made it easier for industries of any size to gain value from data and enhance data-driven operations without sacrificing profits.
Fortunately, cloud computing arrived on the scene just in time, providing a way for enterprises to modernize their data processing and storage infrastructure. Advantages such as flexible price models, resource elasticity, business continuity, increased collaboration, disaster recovery, sustainability, automatic software updates, and security made it very attractive for companies to move to the cloud while also providing a platform to increase analytics performance at a reasonable cost.
Performance in the cloud is easy to achieve, but it will become harder to justify if costs continue to increase. In 2020, a new battleground for cloud services is being defined where both vendors and users are seeking ways to implement new levels of elasticity that provides both high performance and cost-efficiency. Welcome to the new decade of the cloud, where cloud services will compete on the dimension of service efficiency to achieve the lowest cost per compute.







