Earlier this year, IBM announced that it would embed Apache Spark into its analytics and commerce platforms, and would offer Spark-as-a-service on its IBM cloud. IBM’s announcement underscored that using Spark as a means to ingest real-time data, with a paired analytics platform, is going mainstream.
“Spark adoption is growing rapidly with over 600 Spark contributors in the last twelve months,” said Daniel Gutierrez, a data scientist who spoke during a recent Tibco webinar. Spark is the most active Apache open-source project, he said, and is being used to solve an increasing variety and complexity of data problems.
In terms of Apache Spark use cases, organizations such as Edmunds.com, a car shopping site, use Spark to build a just-in-time data warehouse. Pinterest uses Spark through MemSQL to monitor real-time trends.
Netflix, meanwhile, has used Spark to solve different problems with video streaming. The list goes on.
Why use an in-memory, cluster computing framework such as Spark? According to a 2015 survey from Databricks, which was founded by the creators of Spark, 91 percent of Spark users pointed to Spark’s performance gains. Another 77 percent cited ease of use; 71 percent said ease of deployment. Use of advanced analytics was cited by 64 percent, and 52 percent pointed to Spark for use in real-time streaming.
Apache Spark Use Cases: Speed, Performance
Spark was originally developed at UC Berkeley’s AMPLab as a way to resolve efficiencies of running machine-learning algorithms. A catalyst for the development of Spark was to reduce long-running data queries, said Gutierrez, managing editor of InsideBIGDATA. This is particularly important with exploratory data analysis because after a period of time, you start losing your train-of-thought sample, Gutierrez said. The creators of Spark, however, soon released that Apache Spark use cases extended way beyond high-performance machine learning.
Compared to Hadoop MapReduce, Spark provides performance of up to 100 times faster for certain applications by allowing users to load data into a cluster, in-memory, and continuously query it. According to Databricks, Apache Spark in 2014 set a world record in the “Daytona Gray” category for sorting 100 terabytes of data. Spark—which tied the Themis team at UCSD, which used a MapReduce implementation–sorted 100 TB data in 23 minutes on 207 machines. Hadoop MapReduce took 72 minutes on 2,100 machines. (The 2015 winners of the Daytona Gray can be found here).
Why are increasing speeds important? It used to be the case that a terabyte of data was a big number, but not so anymore. Businesses need to process a growing amount of data from Internet of Things sensors, the Web, and mobile applications. The ability to process much of this data in real-time is crucial to many applications, including analysis of financial transactions, predictive maintenance, marketing/sales, and optimizing the output of solar panels. A delay of even a minute can derail some business models built on real-time analytics.
Flexibility and Integration
Apache Spark contains SparkSQL+dataframes, MLib for machine learning, and GraphX for graph computation. That rests on a core API that uses R, SQL, Python, Scala, and Java.
“The ability to use the same framework to solve so many different problems and use cases allows data professionals to focus on solving their data problems, instead of learning and maintaining a different tool for each use case,” Gutierrez said.
Also, “you can use your language of choice”—whether Scala, Python, Java, or SQL, he noted. “This means your focus is on making sense of your data instead of learning a new tool and language.”
Spark’s scalable, machine-learning library offers the ability to create predictive models, such as the Toyota 360 Customers Insights platform. Meanwhile, GraphX can embed a standard set of graph-mining algorithms, including for PageRank. How does that help? AliBaba, an ecommerce leader, used it to model the relationship between customers and items in its store.
Tradeoffs and Benefits
Spark is not intended to replace Hadoop’s MapReduce model but to run on top of Hadoop. In all likelihood, businesses will continue to use MapReduce for tasks where continuous real-time queries are not a pressing concern, as disk storage is cheaper than RAM, and large datasets may not be able to fit entirely in RAM.
But it’s not an either-or proposition. “Many large companies have begun to use systems like Hadoop and Spark together with their existing data warehouse and commercial database tools such as Oracle,” wrote two academic experts in a recent RTInsights article.
For managing a cluster, Spark can work with Hadoop YARN or Apache Mesos, and for storage it can interface with the Hadoop Distributed File System (HDFS), Cassandra, and other solutions.
One big attraction for Apache Spark is that it’s “data agnostic,” Gutierrez said. Users can enrich processing capability by combing Spark with Hadoop and other Big Data frameworks. SparkSQL, in addition, can act on structured and semi-structured data and can work with data formats such as JSON, Parquet and Database.
Spark Architectures, or “Sparkitectures”
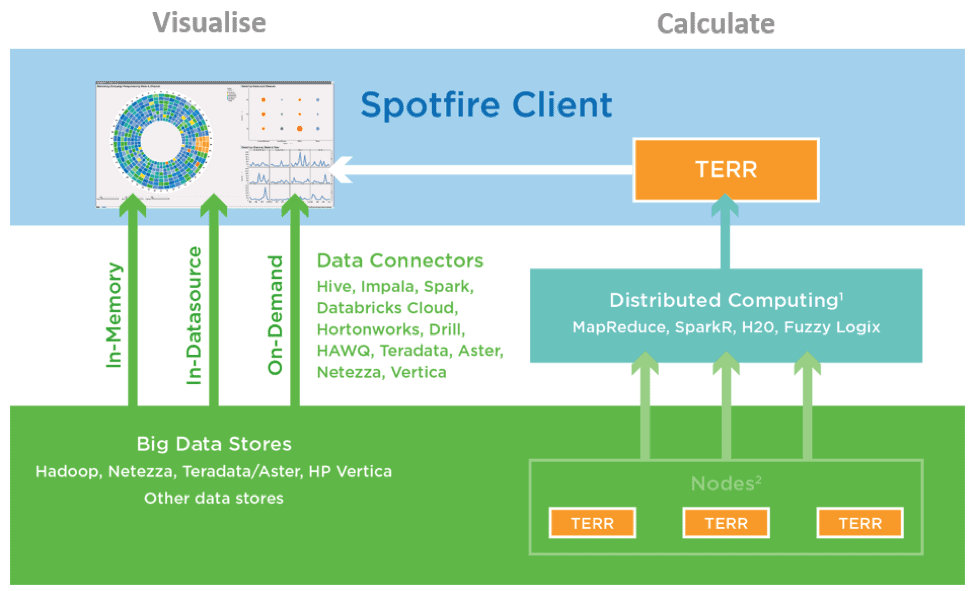
Tibco provides a data recovery and advanced analytics connector to Spark, alongside the industry’s first commercial integration with SparkR, which is connected to the Spotfire in-memory data engine. Spotfire provides data visualization and real-time analytics, with a focus on making advanced analytics accessible to business users that may not code. The R language is a popular statistical programming language for predictive analytics, and a feature of Tibco’s Enterprise Runtime for R, or TERR engine, which is a key component of Tibco’s predictive analytics software. Here’s an example of SparkR architecture from Tibco:
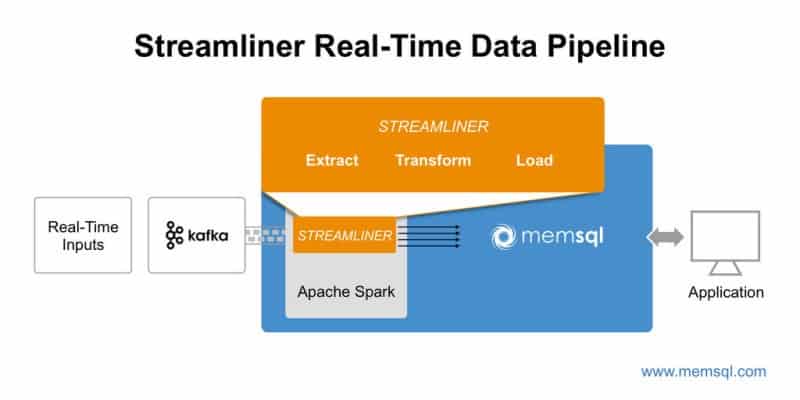
And here’s another from MemSQL, which makes use of Apache Kafka, a messaging system, and MemSQL Streamliner for building real-time data pipelines: