











Deploying open-source Apache Kafka in production offers tremendous capabilities for powerful data streaming at scale. But the road to blissful production deployment often comes with a few surprises along the way. To maintain the performance, reliability, and data durability of your production Kafka cluster, it’s crucial to monitor, prepare for, and react to these seven potential conditions:
1) Unbalanced partition assignment
This is a particularly critical component of maintaining a healthy Kafka cluster. When designing your cluster, balance the number of topics and partitions with the number of consumers and consumer groups that will consume the messages—as well as with the producers that write to these topics.
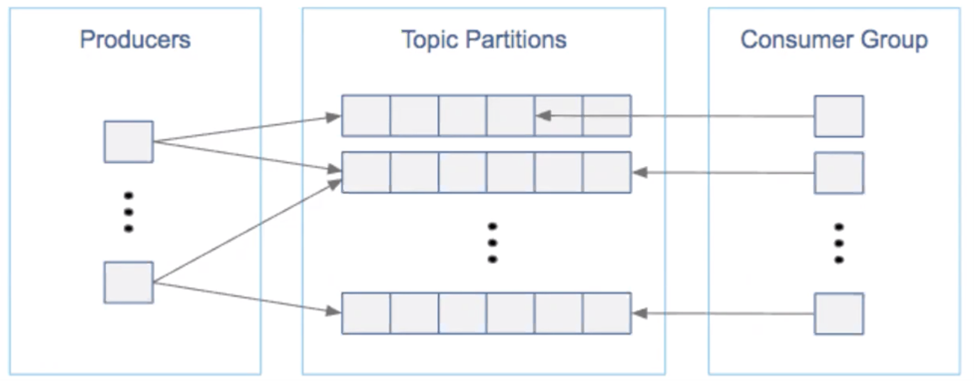
Keep distributed parallel architecture in mind by distributing load, with respect to writes and reads, evenly across partitions. Consider the throughput of producers and consumers you’d like to achieve to estimate the number of partitions you need.
To find the right number of partitions, first calculate the number of producers required by dividing the total expected throughput for the system by the throughput of a single producer to a single partition. Then, calculate the number of consumers by dividing the total throughput by the max throughput of a single consumer to a single partition. Make the total number of partitions equal to the greater of these two numbers.
Remember that you can specify the number of partitions either when a topic is created or afterward. Because the number of partitions affects the number of open file descriptors, be sure to set an appropriate file descriptor limit. Overprovision, don’t underprovision—reassigning partitions gets costly.
Once partitioning is assigned, you can no longer reduce the number of partitions, but you can create a new topic with fewer partitions and then copy over the data. More partitions also increase the pressure on Apache ZooKeeper to keep track of them, using more memory. If a node goes down, more partitions mean a higher latency in partition leader election; for optimal performance, keep partitions below 4000 per broker.
See also: Achieve (and Maintain) Real-Time Apache Kafka Optimization
2) Offline partitions
If a partition in the production environment goes offline, you’ve got a critical condition requiring a critical alert. An offline partition usually means that a server has restarted or a critical failure has occurred. In a Kafka cluster, one broker takes leadership duties to manage and reassign partitions as necessary. An offline partition happens when that elected leader partition dies. Without an active leader, the partition won’t be readable or writable, which could mean losing messages.
To prevent the damage of this state, monitor these three key metrics: 1) OfflinePartitionCount, 2) ActiveControllerCount, and 3) GlobalPartitionCount. OfflinePartitionCount is the number of partitions without an active leader. An alert should be sent if this metric has a value greater than 0. ActiveControllerCount is the number of active controllers in the cluster, and should alert if the sum of all brokers is any number other than 1. GlobalPartitionCount is the total number of partitions in the cluster.
3) Under-replicated partitions, or too many partitions per topic
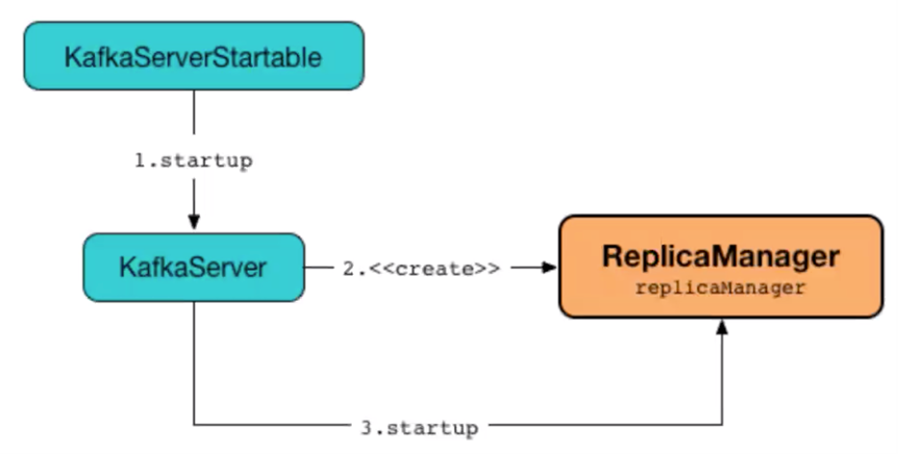
Major issues can occur if the set replication factor for the Kafka cluster is too large or too small. When a Kafka cluster starts, a ReplicaManager is created and starts in tandem. ReplicaManager also uses LogManager to manage log replicas.
If a broker goes down and one or more replicas are unavailable, these under-replicated partitions represent a critical condition. To resolve this, restart the broker and check the logs for errors. Setting up more partitions than necessary is also a danger. Each partition uses considerable RAM and increases CPU load. As a best practice, keep partitions per topic under 50 in most circumstances. In the production cluster, it’s critical to monitor the in-sync replica count, under-replicated partitions, reassigning partitions, and the under-minimum in-sync replica (UnderMinIsr) metric.
4) Lost messages
While Kafka provides message persistence, it’s still possible to lose messages—especially due to misconfiguration. It’s also possible to introduce monitoring to remediate and prevent these issues. If messages are disappearing, look at configuration settings for producer acknowledgments and retries, replication factor, unclean leader election, consumer auto-commits, and messages not synced to disk.
Producer acknowledgments
Producer acknowledgments sets the number of acknowledgments that the leader needs to receive before the producer considers a request completed. If set to 0, the producer will continue on whether or not messages persist, putting them at risk. If set to 1, the producer continues once the leader persists the message. However, if they’ve yet to be replicated and the leader goes down, they will be lost. If set to “all,” a message is guaranteed to persist on all replicas that are in sync.
Producer retries
Producer retries, and the delivery timeout setting (delivery.timeout.ms) can result in message delivery failures. If the timeout value is small, Kafka will keep retrying and timing out, causing message loss. It’s also important to set max.in.flight.requests.per.connection to 1 to ensure messages arrive in the correct order (values over 1 could cause reordering).
Replication factor
The replication factor for each topic can be set when it’s created (it’s only set to 1 by default). Again, setting producer acknowledgments to “all” will ensure that replicas successfully receive messages.
Unclean leader election
An unclean leader election happens when an unclean broker—one that isn’t finished replicating the latest data updates from the previous leader—becomes the new partition leader. Keep unclean.leader.election.enable set to false to prevent this (a true setting is considered a last resort, used when availability is more important than durability).
Consumer auto-commits
If enable.auto.commit is set to true and a consumer fails, it won’t read messages older than the committed offset. Consider a false setting to avoid this.
Messages not synced to disk
Kafka settings for log.flush.interval.messages/log.flush.interval.ms or flush.messages.flush.ms control when the OS can flush messages to disk. If all brokers go down at the same time, messages are at risk if they weren’t flushed to disk (so don’t let that happen).
5) Incorrect ordering of messages
If two message batches are sent to a single partition and the first fails and retries while the second goes through, the second batch’s records can appear first in order. Setting max.in.flight.requests.per.connection to 1 prevents this issue.
6) Deteriorating Kafka performance
KafkaMetricsGroup provides key performance measures for understanding how a Kafka cluster will perform under heavy load.
Latency and throughput are key metrics. Tune performance by including just enough brokers to achieve desired topic throughput and latency. Also tune Kafka producers by setting batch size (the data bytes collected before sending messages to the broker) as high as you can. Increase linger time (the maximum time for buffering data in asynchronous mode) as well for higher latency and throughput. Ensure balanced leaders, and replication sets in-line with system needs and how important it is to preserve data. As a best practice, start with one partition per physical storage disk and one consumer per partition. Bottlenecks happen at the consumer reading the topic: to avoid this, also set the number of consumers equal to the number of partitions.
To complete replicas quickly, raise the value of num.replica.fetchers and replica.fetch.max.bytes.
If less thread is available for creating a replica, increase buffer size with replica.socket.receive.buffer.bytes. Use num.partitions to ensure data can be written in parallel, increasing throughput.
7) Using older versions
If your production cluster isn’t using the latest version of Kafka, errors can occur due to mismatches in compatibility across different clients, brokers, and third-party applications. Newer Kafka brokers can communicate with older Kafka clients, but not vice versa. Avoid these issues by upgrading Kafka as necessary.






