











As Chief Analytics Officer at FICO, many people assume I spend most of my time tucked away in the data science lab, wearing a white coat amidst the clatter of chalk against blackboard and fingers against keyboard, a slide rule stuck in my chest pocket. In reality, I spend a lot of my time with customer audiences worldwide, explaining how artificial intelligence (AI), machine learning (ML) and other leading-edge technologies can be applied to solve today’s business problems.
Neural networks are one of those technologies. They are a critical component machine learning, which can dramatically boost the efficacy of an enterprise arsenal of analytic tools. But countless organizations hesitate to deploy machine learning algorithms given their popular characterization as a “black box”.
While their mathematical equations are easy executed by AI, deriving a human-understandable explanation for each score or output is often difficult. The result is that, especially in regulated industries, machine learning models that could provide significant business value are often not deployed into production.
See also: 3 Ways to Join the AI Revolution Now
To overcome this challenge, my recent work includes developing a patent-pending machine learning technique called Interpretable Latent Features. Instead of explaining AI as an afterthought, as in many organizations, our new technique brings an explainable model architecture to the forefront. The approach is derived from our organization’s three decades of experience in using neural network models to solve business problems.
Why Explaining ML is Important
An explainable multi-layered neural network can be easily understood by an analyst, a business manager and a regulator. These machine learning models can be directly deployed due to their increased transparency. Alternately, analytic teams can take the latent features learned and incorporate them into current model architectures (such as scorecards).
The advantage of leveraging this ML technique is twofold:
- It doesn’t change any of the established workflows for creating and deploying traditional models
- It improves the models’ performance by suggesting new ML-exposed features to be used in the “traditional rails.”
See also: Top Open Source Tools for Deep Learning
This capability – to take an input dataset and learn the interpretable latent features—has been deployed in customer production environments. In this way, FICO helps customers deconstruct any lingering “black box” connotations of machine learning by unleashing the power of interpretable latent features.
Here is a brief overview of our approach that you might find useful in your enterprise. You’ll see that a key is exposing and simplifying hidden nodes.
Introduction to Explainability
A neural network model has a complex structure, making even the simplest neural net with a single hidden layer hard to understand. (Figure 1) Our methodology exposes the key driving features of the specification of each hidden node. This leads to an explainable neural network. Forcing hidden nodes to only have sparse connections makes the behavior of the neural network easily understandable.
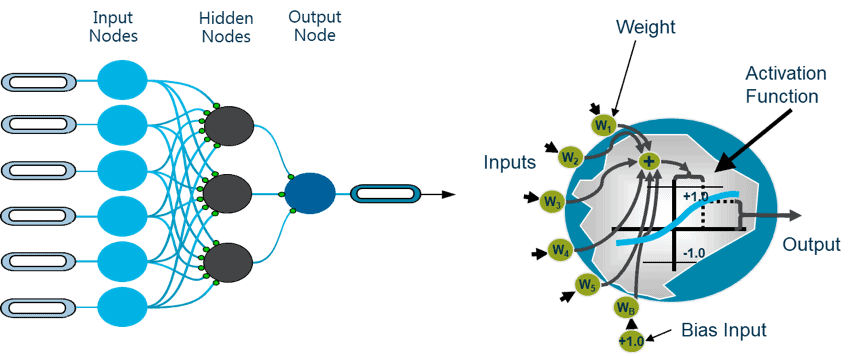
Figure 1: Even the simplest neural network can have a single hidden layer, making it hard to understand.
Generating this model leads to the learning of a set of interpretable latent features. These are non-linear transformations of a single input variable, or interaction of two or more of them together. The interpretability threshold of the nodes is the upper threshold on the number of inputs allowed in a single hidden node, as illustrated in Figure 2.
As a consequence, the hidden nodes get simplified. In this example, hidden node LF1 is a non-linear transformation of input variable v2, and LF2 is an interaction of two input variables, v1 and v5. These nodes are considered resolved because the number of inputs is below or equal to the interpretability threshold of 2 in this example. On the other hand, the node LF3 is considered unresolved.
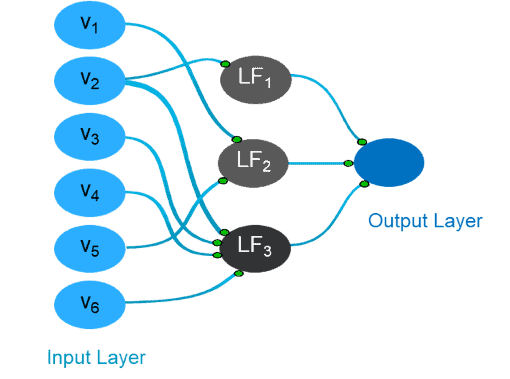
Figure 2: Getting there. Nodes LF1 and LF2 are resolved. Node LF3 is unresolved because the number of its inputs exceeds the interpretability threshold.
Resolved Nodes are Explainable Nodes
To resolve an unresolved node, we tap into its activation. A new neural network model is then trained; the input variables of that hidden node become the predictors for the new neural network, and the hidden node activation is the target. This process expresses the unresolved node in terms of another layer of latent features, some of which are resolved. Applying this approach iteratively to all the unresolved nodes leads to a sparsely connected deep neural network, with an unusual architecture, in which each node is resolved and therefore is interpretable. (Figure 3)
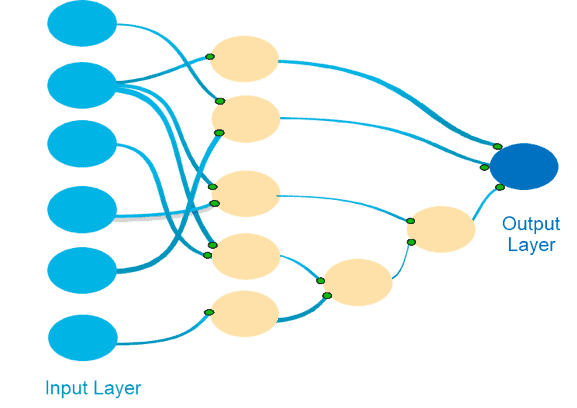
Figure 3: Achieve interpretability by iteratively applying a resolution technique.
The Bottom Line
Making complex neural networks understandable to human analysts at companies and regulatory agencies is a crucial step in speeding machine learning into production. Interpretable Latent Features is a new machine learning technique that helps demystify ML, enlightening and moving key stakeholders along the path to business value.






