











This article is aimed at architects, software engineers, product owners, and other IT leaders responsible for delivering systems that use data from event streams to improve operational decisions. It summarizes four kinds of software that perform real-time analytics on event streams: analytics and BI (ABI) platforms, stream-enabled DBMSs, event stream processing (ESP) platforms, and unified real-time platforms (URPs). It also identifies scenarios where each should be used.
Streaming Data
Stream analytics is an umbrella term for any technique that performs analytics on event streams. It’s the data that makes the difference from other kinds of BI and data science. An event stream is a continuous sequence of data records that report things that happen (i.e., “events”). Streaming data is quite common – every large organization has access to many streams already flowing over its internal network and the Internet. These include:
Internal streams generated by customer and employee interactions:
- Web clickstreams
- Call center phone logs
- Email and text messages
IoT streams emitted by vehicles, mobile phones, machines, and other physical devices:
- Machine logs
- Sensor readings
- SCADA streams
- Geolocation reports
Copies of business transactions and changed-data-capture (CDC) database events from OLTP applications:
- Customer orders
- Payments
- Advance shipping notices
- Telco call data records
- Hotel or airline reservations
External, Internet-based streams such as:
- Market data feeds
- News feeds
- Weather feeds
- Traffic data feeds
- Social computing activity streams, such as Facebook, LinkedIn, and X posts
Stream Analytics
Most stream analytics are actually performed offline, not in real-time. Streaming data is landed in a file or database; sent through some batch or micro-batch data engineering pipeline; stored in a data lake, data warehouse, lakehouse, or other database; and then processed by an application, BI tool, data science/machine learning (DSML) platform, or other AI tool in a batch or interactive exploration manner. This use of somewhat older streaming data works fine for strategic, tactical, and non-real-time operational decisions.
For the increasing number of time-sensitive operational decisions, that isn’t fast enough. Real-time analytics on streaming data is essential to good situation awareness, which is defined as “knowing what is going on so you can decide what to do.” Situation awareness leads to better operational decisions – better use of people’s time and other resources, better customer service, higher-yielding offers, less waste, less fraud, and many other benefits.
All four kinds of products described in this article can be used to process event streams in real time. All four commonly ingest streams from Kafka, Kafka-like, or other “event broker” messaging systems. Streams are sometimes processed as data in motion and, elsewhere, are processed as data at rest, i.e., after they have been stored in a database. If at least some of the data is fresh, i.e., produced in the last few seconds or minutes, the system can be considered as “real-time.” In this article, we use the term “real time” to mean “near real time,” also called “business real time” (see Do you need to process data “in motion” to operate in real time? for more explanation).
- ABI platforms usually process data at rest, but a few can process data in motion
- Stream-enabled DBMSs process data at rest in real-time (they can also process historical data at rest, not in real time, of course)
- ESP platforms process data in motion
- URPs generally process both real-time data in motion and historical data at rest
To choose the right kind of tool, you need to understand the problem, including the business goals, requirements, and constraints. Some of the key decision criteria include:
- What is the volume of the incoming event streams (messages per second)?
- How many entities (e.g., people, vehicles, devices) are being tracked?
- What latency is required (e.g., 99% of responses executed in subseconds, multiple seconds, or multiple minutes)?
- Is all of the data coming from real-time streams, or is historical data part of the decisions?
- Are the input event streams queryable as they arrive, or do they need extensive data quality and refinement steps (e.g., filters, transformations, rollups, feature generation)?
- What analytical techniques are required to make the decision (e.g., Gen AI, statistical ML, rules, etc.)?
In the remainder of this article, we will summarize the characteristics of four very different kinds of technologies. Each of these can be used separately although in some situations, the best approach is to combine two or even three of them for one project. This is not detailed enough to help you pick a particular product but hopefully it can get you started by understanding the broad product categories.
Analytics and BI platforms
ABI platforms include products such as Microsoft’s PowerBI, SalesForce’s Tableau, Cloud Software Group’s Spotfire, and numerous others.
Conventional ABI reports and dashboards are typically outside the boundaries of real-time because all of their data is more than 15 minutes old. However, ABI products have been used for many years for some (near) real-time reports and dashboards, e.g., refreshed every few minutes, sometimes even more frequently.
Most ABI products have now added some support for streaming data, although the majority of products handle streams indirectly by first storing the data in a database (making it technically data at rest) before processing it like any other ABI data. However, a few ABI platforms, including Cloud Software Group’s Spotfire and Microsoft’s PowerBI, can process moderate amounts of streaming data directly (data in motion), further reducing the latency. ABI platforms have evolved into general purpose end-user interfaces for analytical data by being combined with various other products, such as data science/machine learning (DSML) platforms, and being embedded into applications.
Where to use (See Figure 1):
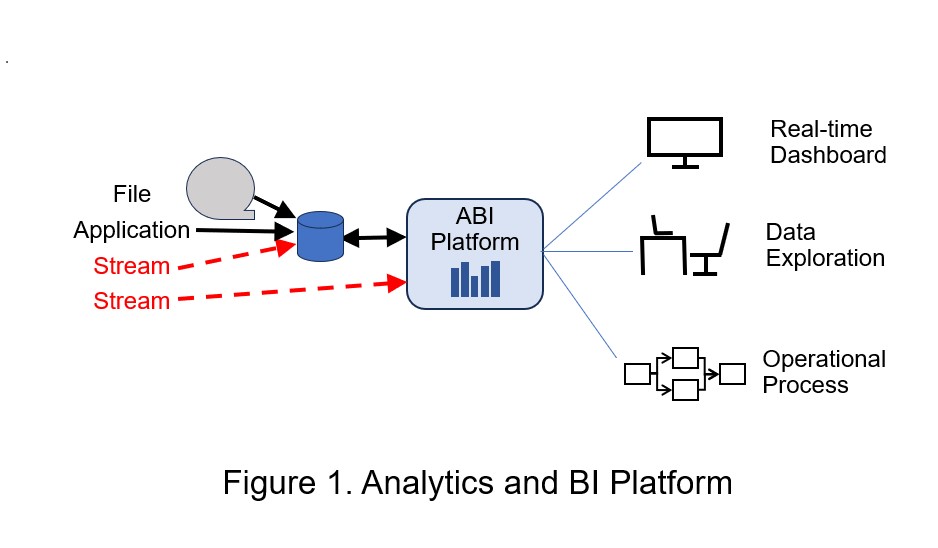
ABI platforms are used for (near) real-time reports and dashboards that update with new information every few minutes, sometimes every few seconds, or, rarely, even sub-second. They provide descriptive analytics (what happened in the past and what is happening now) and sometimes project what may happen in the future (predictive analytics).
Strengths:
- ABI platforms compute a wide variety of aggregations (“rollups”) and generate useful graphics and stories that convey the important aspects of the information.
- ABI platforms also support ad hoc queries, which makes them useful for interactive exploration of the data and drilling down into the details (i.e., diagnostic analytics, a type of descriptive analytics).
Limitations:
- ABI platforms can’t, by themselves, provide fast response times with high volume event streams. However, they can be used with high volume streams if paired with a stream-enabled DBMS or ESP platform that filters and condenses the stream down to a manageable rate (see below).
- ABI platforms are not relevant for tasks that require sub-second responses to emerging situations. Virtually all ABI applications show data to people, and people inherently introduce latency in the end-to-end response process. Sub-second responses require full automation (no person in the loop).
- Some ABI platforms now provide action frameworks that can trigger a “push” type of alert (to people) or even an automated response (i.e., an API call invokes an external service). However, the action rules are fairly basic and don’t handle very low-latency sense-and-respond scenarios.
- To achieve relatively fast response times (e.g., a few seconds after the arrival of new data), the input data must arrive in a queryable form. If the input data requires significant data engineering to improve data quality or to abstract the data, latency will be much higher.
Stream-enabled DBMSs
More than 90 percent of business applications that process streaming data put it in some database or file before making it accessible to analytical tools or applications (i.e., it becomes data at rest). Virtually any database can be used to hold streaming data. In the majority of cases, the streaming data is not used in (near) real-time, i.e., it is more than 15 minutes old, and often hours or days old, before being used. As mentioned above, this works fine for most BI, data science, and even business application purposes but not for real-time operational applications.
Note that the data is at rest whether it is used in real-time or not, and regardless of whether it is in memory or in a persistent store.
As real-time use cases proliferate and become a bigger factor in DBMS selection, many DBMSs have added streaming capabilities. However, the actual implementation and performance of “streaming” in various DBMSs and data lakes vary tremendously. Basic support merely implies having adapters to ingest data, such as clickstreams or changed-data-capture records, from Kafka, Kafka-like, or other messaging systems.
In most cases, the raw incoming streaming data is not in a usable (queryable) form. Therefore, a few more-advanced streaming DBMS and data lake implementations support real-time dataflow variations of the Medallion design pattern. The system continuously filters raw streaming data, improves data quality, and computes complex events (abstractions such as aggregate rollups, patterns, and ML features) before storing the data.
It would be TL;DR to fully explore the differences in data models and data management techniques among the DBMSs that have explicit support for real-time streams, and there are significant overlaps among the following categories of DBMS. Nevertheless, here is a high-level outline and a few product examples (note that these are not comprehensive product lists or recommendations; many other good products are not mentioned due to lack of space):
- In-memory data stores, such as Aerospike, memcached, and Redis, provide extremely low latency, sometimes sub-millisecond, by keeping data in memory or SSDs.
- Streaming DBMSs, such as Materialize, Noria, and RisingWave, incorporate internal dataflow pipelines and incrementally materialize views as they run.
- Time series DBMSs, such as Amazon Timestream, Aveva PI, InfluxData, Microsoft ADX, and TimescaleDB, are high performance, append-only persistent data stores that are specifically optimized for timestamped, streaming data. Some of these products are mostly or entirely directed at industrial (“IoT”) data.
- Real-time analytics DBMSs, such as Clickhouse, Druid, FeatureBase, Imply, Kinetica, Rockset, and Tinybird, support very low-latency retrieval and OLAP-type analytics on very large data sets.
- Search-based data managers, such as Elastic, OpenSearch, and Splunk, are optimized for less-structured time series data, particularly logs.
- Multimodel DBMSs, including Cassandra, MongoDB, Scylla, and Singlestore, are widely used for scalable, low-latency applications with streaming data.
Where to use (See Figure 2):
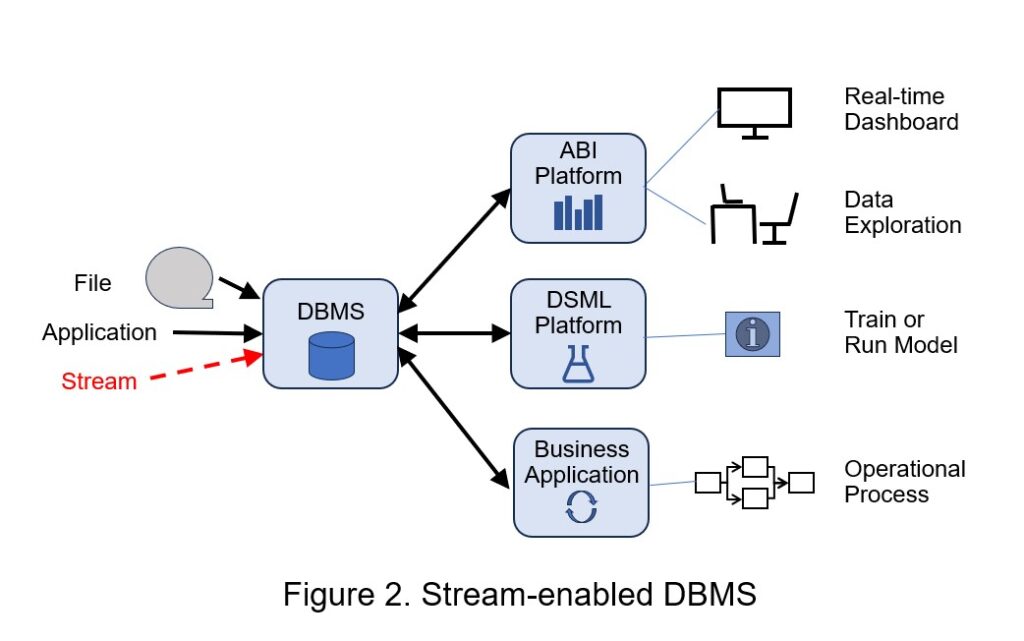
Stream-enabled DBMSs can support many real-time and virtually all non-real-time stream analytics scenarios, including batch processing. Used with ABI platforms, they enable descriptive analytics (what happened in the past and what is happening now) and are sometimes used to help project what may happen in the future (predictive analytics). They also support operational business applications, sometimes including transaction processing.
Strengths:
- All of these products can support very large databases, although some products are significantly more scalable than others.
- Similarly, all of these products can support fairly low-latency applications (e.g., subsecond response times depending on the scenario), although again, there is a wide variation in their latencies in different use cases.
Limitations:
- Stream-enabled DBMSs generally cannot support ultra-low-latency applications that require single-digit millisecond or sub-millisecond end-to-end response action times (including the application logic).
- The majority of stream-enabled DBMSs don’t provide their own real-time dataflow pipelines to pre-process streaming data as it arrives. However, streaming data engineers can use a separate ESP platform to front-end the DBMS to perform this function. Alternatively, if the business requirements can accept higher latency, data engineers can land streaming data in a raw zone and use a standard batch or micro-batch data pipeline to refine the data.
Event Stream Processing Platforms
ESP platforms include Flink (from Aiven, Amazon, Apache, Confluent, Cloudera, and many other vendors), Arroyo (from Apache and Arroyo Systems), Axual KSML, Espertech Esper, Google Cloud Dataflow, Hitachi Streaming Data Platform, Kafka Streams (from Apache and Confluent), Microsoft Azure Stream Analytics, SAS Event Stream Processing, Spark Streaming (from Apache, Databricks, and many others), TIBCO Streaming, and similar products.
ESP platforms perform incremental computation on streaming data as it arrives while the data is in motion and before it is stored in a separate database or file. ESP platforms keep data in internal buffers (state stores) temporarily to support multistage real-time data flow pipelines (sometimes called jobs or topologies). They apply calculations on moving time windows (typically minutes or hours in duration) and may take checkpoints to enable faster restarts.
Where to use (see Figure 3):
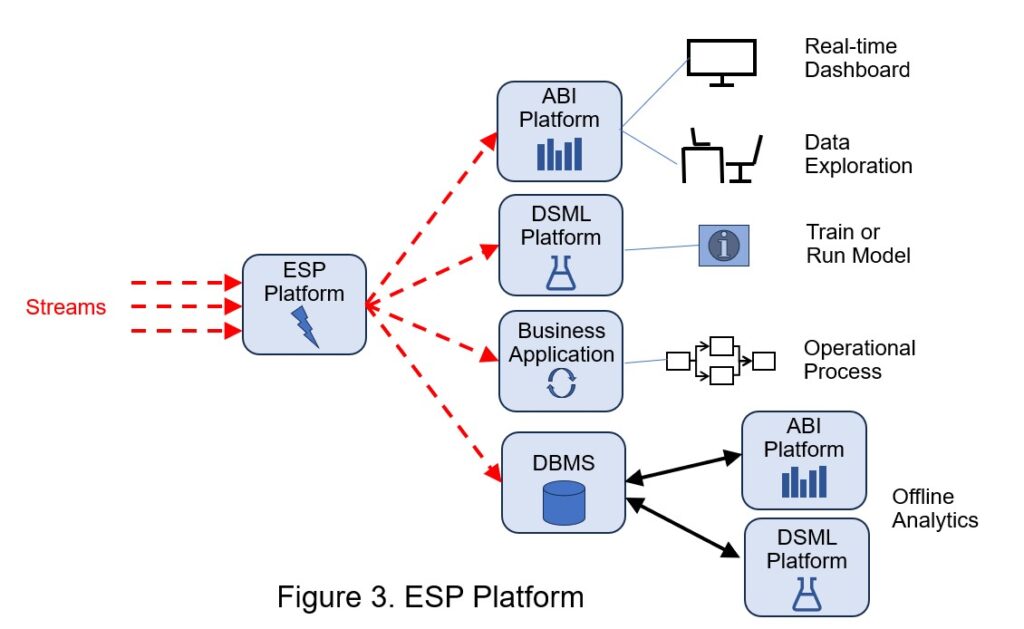
Although organizations sometimes acquire ESP platforms as separate products, they are increasingly bought as part of a larger suite. For example, most industrial IoT platform products incorporate an ESP platform. Vendors also bundle ESP platforms into other products, such as data integration tools, customer engagement platforms, supply chain management tools, AIOps platforms, or unified real-time platforms. Use cases include:
- ESP platforms are often used for ultra-low-latency stream analytics. They may update real-time dashboards, send alerts, or trigger automated event-driven responses (“sense and respond”). They provide descriptive analytics (what is happening now) or predict what might happen in the future based on finding leading indicators of emerging threats or opportunities.
- As mentioned above, ESP platforms are also commonly used to ingest, transform, and store high-volume streaming data into data lakes, feature stores, other databases, and file systems (“stream data integration”). This is particularly relevant for DBMSs and data lakes that lack their own real-time data flow pipeline capabilities.
- Again, as we mentioned earlier, ESP platforms are occasionally also used to front-end ABI platforms to filter, abstract, and reduce the volume of input data to a level that the ABI platform can handle. Both Microsoft and TIBCO have integrated their ESP platforms with their ABI products to make this easier to implement.
Strengths:
- ESP platforms can scale to many millions of events per second and provide single-digit or even sub-millisecond latencies in some use cases.
- ESP platforms make it relatively easy to implement various kinds of moving time windows, including fixed-length and session windows. Most have ways to deal with out-of-order and late-arriving events.
- ESP platforms can execute a wide range of logic, including filtering, simple rollup aggregations (e.g., count, sum, average), rules, pattern detection, generative AI and other ML inferences, and custom user-written transformations.
- Some ESP platforms support reading and writing in both batch and streaming modes.
Limitations:
- It is not easy to develop ESP platform applications that combine real-time streaming data with older historical data. ESP platforms don’t store long-term data-of-record or reference data. Joining tables with streams is possible but complicated.
- Internal ESP storage is not accessible by external applications. Some ESP platforms produce data stores that can be dynamically read by other applications (for example, ksqlDB and Flink Table Store – two very different concepts), but these are not as functional as full-blown DBMSs.
- ESP platforms are overkill for low-volume event streams or where ultra-low latency is not required unless the application needs temporal windowing or pattern detection.
Unified Real-time Platforms
URPs are an increasingly popular kind of software that combines many or all of the capabilities of an ESP, a programmable application engine, and a stream-enabled DBMS or data grid (see Unified Real-time Platforms):
- The application enablement aspect of a URP supports asynchronous, event-driven operations and synchronous request/reply operations. It includes build-time development tools and run-time infrastructure for backend (data facing) business logic with real-time analytics that may include Gen AI, other kinds of ML, or rule processing.
- The event stream processing aspect supports continuous data flow computation and stream analytics on data as it arrives. Many URPs have a stream processing engine that is separate from the application enablement engine to handle fast stream ingestion, time windows, and out-of-order and late-arriving events.
- The real-time data management aspect supports storing and access to real-time data and historical data in memory or in a persisted store. Its data model and close integration with the application enablement and stream processing capabilities are key to URP performance.
URP products can be categorized as either URP platforms or URP solutions (which are built on embedded URP platforms):
- A URP solution is a set of features and functions, an application template, or a full (tailorable) commercial off-the-shelf (COTS) application or SaaS offering that is focused on a particular vertical or horizontal domain. URP solutions are available for various types of customer relationship management (CRM); supply chain management; (IoT) asset management; transportation operations (trucks, planes, airlines, maritime shipping); capital markets trading; and other verticals. For example, URP solutions related to differing aspects of CRM include Evam Marketing, Joulica Customer Experience Analytics, Scuba Analytics’ Collaborative Decision Intelligence Platform, Snowplow Behavioral Data Platform (BDP), Unscrambl Qbo, and ZineOne Customer Engagement Hub.
- Platforms are generic URP infrastructures suitable for use in many industries and applications. They are technically a subset of solutions because the user company or a third-party partner must build the application from scratch, whereas solutions generally need less customizing. URP platforms are offered by Gigaspaces, Gridgain, Hazelcast, KX, NStream.io, Pathway, Radicalbit, Timeplus, Vantiq, Vitria, Volt Active Data, XMPro, and other vendors. Some vendors that sell platforms also offer partial or fairly complete URP solutions for one or two domains.
In a separate article (How to Select a Unified Real-time Platform), we’ll look at URPs in more detail and list some of the other vendors.
Where to use (See Figure 4):
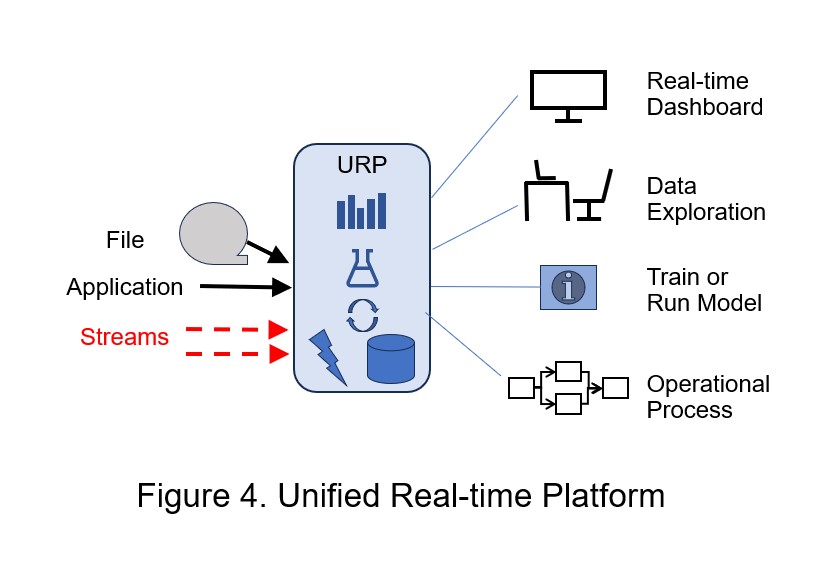
URPs are relevant for systems that perform complicated real-time calculations on both streaming and historical data. They can calculate what happened, what is happening now, and what is likely to happen in the future. Further, they can execute critical parts of business applications. URPs serve (1) management control applications that monitor large, complicated operations; (2) applications that execute business transactions; or (3) those that do both:
- Real-time management control applications monitor business domains with many customers or workers, or large fleets of vehicles, machines, or other devices. These applications often use the digital twin design pattern. They provide situation awareness, help detect or predict threats or opportunities, and may trigger alerts or appropriate sense-and-respond interventions. Examples of relevant business domains include communication networks (e.g., monitoring cell phone network reliability and performance); customer contact centers; supply chain management (where are the goods and when will they arrive?, warehouse management); field-service management; transportation network management (trucks, planes, ships, trains); mining and other asset tracking; smart cities (real-time police operations, traffic management); utilities (electricity generation, transmission, distribution; water utilities; wastewater); and many others.
- Transactional applications are found in many vertical and horizontal domains, such as real-time customer relationship management (e.g., e-commerce, customer service, point-of-sale, marketing); travel (e.g., seat reservations, ticket purchases, refunds); order management (e.g., purchases, returns, billing); banking (e.g., deposits, withdrawals, payments, credit card purchases); capital markets (e.g., quotes, bids, buy, sell, arbitrage, compliance); insurance (e.g., interactive policy management, application-to-issue processes, policy management, claim processing); education (e.g., student applications, registration, payments) and other areas.
Examples of real URP applications include those that:
- Analyze banking transactions as they are submitted to prevent fraud before it happens.
- Manage mining operations to detect equipment failures and human mistakes to maximize production and minimize downtime.
- Manage railroad operations to save the cost of diesel fuel and alert customers of when goods will arrive.
- Detect bottlenecks and broken equipment in mobile phone networks to improve customer service levels.
- Monitor the customer onboarding process in electric utilities so that customer requests are not lost or delayed.
- Correlate customer clickstream data with contact center call data and mobile location data to generate best next action cross-sell or upsell offers (real-time customer 360).
Strengths:
- All URPs scale well and have low latency. Some are capable of extremely high scalability and sub-second latency (e.g., tracking tens of millions of entities, with millions of events per second) thanks to the close integration of processing logic and data management.
- For high volume/low latency real-time stream analytics, URPs are generally superior to the alternative, which is a “Do It Yourself” assembly of multiple piecemeal technologies such as an ESP platform combined with a high-performance streaming DBMS, web servers, and containers or application servers. Few organizations have the expertise to build good DIY solutions that can deliver both very high volume and predictable very low latency. DIY solutions often use multiple independently configured and managed clusters and many places where memory space, network, and other technical boundaries are crossed. DIY projects have significantly longer time-to-solution and incur more technical debt than URPs.
Limitations:
- URP platforms have unusual programming models and can be hard to program, especially at first.
- URP platforms are overkill for low-volume, high-latency applications where traditional application architectures perform well.
- URP solutions don’t have the previous two drawbacks because they provide partial or complete applications off-the-shelf. However, solutions are only available for a limited set of vertical and horizontal applications, so there may not be one that fits your problem.







