











In the first part of this article, I explained why protocols play an important role in IoT architecture and described four of the most widely used alternatives: CoAP, DDS, LwM2M, and MQTT. In part 2, I will cover emerging protocols that address some of the weaknesses found within these four alternatives and can enable a more seamless IoT experience.
Context
MQTT was created in 1999; the development of DDS started in 2001. Technology was, naturally, very different back then. The emergence of Cloud computing, in particular, had profound implications on transport and encryption requirements. In addition, as those early IoT protocols gained traction, interoperability issues started to sprout.
The 2010s saw the emergence of alternatives such as CoAP and LwM2M. Both are feature-rich yet lack the robust quality of service (QoS) and publish/subscribe approach shared by MQTT and DDS. Eclipse Sparkplug and Eclipse zenoh are contemporary protocols that deliver improvements to MQTT and DDS, respectively.
Sparkplug
One of the great things about MQTT is that you can publish any payload to any topic. One of the bad things about MQTT is that you can publish any payload to any topic. When they wrote the initial specification for MQTT, Andy Stanford Clark and Arlen Nipper intentionally avoided prescribing anything about payload encoding and format. MQTT packets can contain plain text or binary payloads, and it is up to the applications to decode, parse, and interpret them. Moreover, besides a few syntactic limitations, MQTT topic structures are completely arbitrary. Naturally, the goal of those decisions was to favor flexibility.
The price to pay for this level of flexibility is a lack of interoperability. Out-of-the-box, MQTT clients have no idea of the encoding, payload format, and topic structures that the other clients expect. Most implementation projects must dedicate time and resources to massage payloads and integrate disparate topic namespaces. This is error-prone and time-consuming.
The Sparkplug specification aims to solve the lack of interoperability in industrial automation in general, and specifically in MQTT-based infrastructure. It defines a topic namespace, payloads, and stateful session management.
To learn more about the Sparkplug specification, please visit its official website at https://sparkplug.eclipse.org. The Eclipse Tahu project provides a compliant open-source implementation of the protocol.
Architecture
Sparkplug’s architecture includes three main concepts: host application, edge node, and device. The host application is an application that consumes data from Sparkplug edge nodes. SCADA/IIoT hosts, MES, historians, and analytics applications are all examples of Sparkplug host applications. A Sparkplug edge node is an MQTT client application that manages an MQTT Session and provides the physical and logical gateway functions required to participate in the Sparkplug namespace while leveraging Sparkplug-compliant payloads. The edge node is responsible for local protocol interfaces to existing devices (PLCs, RTUs, Flow Computers, Sensors), local discrete I/O, and logical internal process variables (PVs). Finally, a device is physically or logically connected to a Sparkplug edge node.
Figure 1 illustrates how those three concepts fit together.
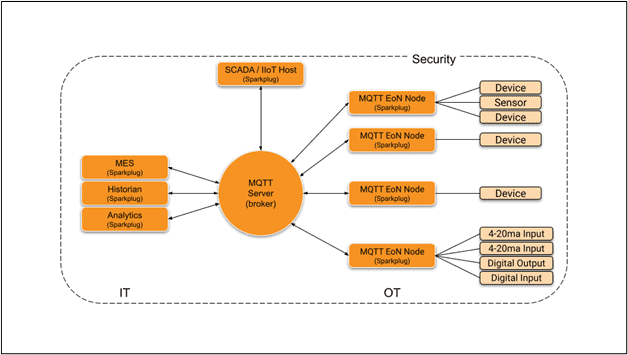
Figure 1: Sparkplug Architecture (Credit: Eclipse Foundation)
As you can see, the MQTT broker is at the core of the whole system. Naturally, this does not preclude using multiple brokers or deploying a clustered broker instance. Sparkplug supports any broker implementing a defined subset of MQTT features.[1] and is not tied to any particular broker.
Sparkplug edge nodes, host applications, and devices exchange messages through the Sparkplug topic namespace using Sparkplug-defined payloads.
Topic namespace
Sparkplug defines a topic namespace optimized for Industrial IoT (IIoT). This namespace is extensible, allows automatic discovery, and enables bidirectional communications between MQTT clients.
Figure 2 below illustrates how the namespace is structured.
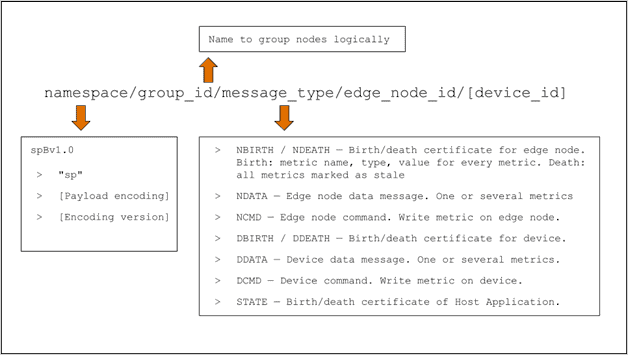
Figure 2: Sparkplug Namespace Structure (Credit: Eclipse Foundation)
The namespace is versioned to reflect the payload encoding used and its version. This means applications using different versions of Sparkplug can coexist in the same environment without interference. The current payload encoding is “B,” and its version is 1.0. Consequently, the namespace starts with the “spBv1.0” string.
The second element of the Sparkplug namespace is the group id. It is an arbitrary identifier (determined by the implementers) to group related edge nodes, host applications, and devices.
The third element of the namespace is the message type. In Sparkplug, devices and edge nodes report when they connect and disconnect through birth and death certificates (NBIRTH/NDEATH and DBIRTH/DDEATH, respectively). Birth certificates contain information about the metrics that the node or device will report about. Edge nodes and devices can also send data or receive commands to execute through specific message types (NDATA/NCMD and DDATA/DCMD).
The last element of the namespace is the edge node id. This is a unique identifier for the node. The namespace will also contain the device’s id if the node has devices attached.
Payload
Sparkplug defines a binary payload encoding suitable for legacy register-based process variables, like Modbus register values. The payload is focused on process variable change events, called metrics. The payload format supports complex data types, datasets, metrics, metric metadata, and metric aliases. It is versioned and referenced in the topic structure so that clients can easily infer the encoding used for the payload of a specific message.
From a technical perspective, the encoding is defined in the Google Protocol Buffers data interchange format. Protocol buffers are a language-neutral, platform-neutral, extensible mechanism for serializing structured data. They support most mainstream programming languages.
Figure 3 provides an example of an edge node certificate expressed in JSON. In this case, the node announces it will report about a single metric named temp-value. The initial value for the metric is -24, which is in the range for possible values in Canada for that time of the year. Both the message itself and the metric value have a timestamp, which enables the application to evaluate whether the data is stale or not.

Figure 3: Sparkplug edge node birth certificate expressed in JSON
Data messages (NDATA for edge nodes and DDATA for devices) are smaller than birth certificates, which reduces bandwidth usage. Figure 4 shows an edge node data message for the same metric.

Figure 4: Edge node data message expressed in JSON
Data messages can contain one or several metrics; edge nodes and devices will typically only report metric values that have changed since the last sent message. The edge node or device determines the threshold for sending a data update.
State Management
Sparkplug takes full advantage of the statefulness of MQTT to reduce latency. This is critical because Sparkplug leverages a report-by-exception approach. In other words, no periodic updates are provided to subscribers. Data updates are sent whenever they occur. The way Sparkplug is structured guarantees that if a device is online, the last value reported for a metric remains current. Naturally, it is also possible to send regular updates for record-keeping to satisfy regulatory requirements, for example.
Eclipse zenoh
At its core, zenoh is a next-generation publish/subscribe protocol supporting peer-to-peer and routed topologies. It was built from the ground up for Edge Computing and has been influenced by DDS. The most important thing to remember about Eclipse zenoh is that its functional scope is broader than most other IoT protocols. Zenoh also supports data at rest and computations.
In addition to subscriptions, zenoh developers have two ways to retrieve and compute data. One is distributed queries, through which various nodes in the zenoh infrastructure will provide fragments of the result set. The other is distributed compute values that involve triggering one or several computation functions to provide a result. Naturally, data retrieval implies data storage. Zenoh supports this through a specialized plugin. The protocol enables you to define storage units anywhere in the infrastructure. Those storage units dwell in databases (relational or not), system memory, or the filesystem of a node.
Key zenoh Abstractions
The key/value paradigm is at the core of zenoh. Zenoh keys are comparable to Linux filesystem paths and MQTT topics. They are hierarchical strings where the forward-slash character separates the levels (“/”). The following are a few examples of zenoh keys:
/museums/Diefenbunker/floors/1/rooms/101/sensors/temperature
/museums/Diefenbunker/floors/2/rooms/202/sensors/humidity
The preceding keys lead to specific resources, also called named data items in zenoh parlance. You can build expressions involving a set of keys. Such expressions can, of course, contain wildcards. The single asterisk (“*”) is used as a single-level wildcard, while the double asterisk (“**”) is a multilevel one. For example, the following key expression could be used to subscribe to all the sensors in room 101:
/museums/Diefenbunker/floors/1/rooms/101/sensors/*
This other expression could return data for all the temperature sensors, independently of their location:
/museums/Diefenbunker/**/temperature
You will use key expressions in the following situations:
- Subscribing to data
- Creating a storage instance
- Registering a distributed computation (eval)
The results of distributed queries can contain values fetched from storage instances or produced by a computation (eval) if the key path used at their creation matches the selector used.
As in MQTT, zenoh values are transmitted as a stream of bytes. Zenoh values also contain a field to specify the encoding used as a MIME type. Any encoding may be used, but zenoh offers serialization and deserialization support for a specific set of encodings. The encodings benefiting from this additional support include:
- application/octet-stream: Value is a stream of bytes.
- text/plain; charset=utf-8: Value is a UTF-8 string.
- application/json: Value is a JSON string.
- application/properties: Value is a string representing a list of key/value pairs separated by a semicolon (e.g., “id=002;squad=13…”)
- application/integer: Value is an integer.
- application/float: Value is a float.
All zenoh values possess a timestamp set by the first router receiving it. Zenoh timestamps are guaranteed to be unique, given the method used to generate them. Consequently, you can use the timestamps to order values at any location in the system without the need to leverage a consensus algorithm.
Deployment Units
When deploying zenoh infrastructure, you can leverage various topologies according to your requirements. The features of zenoh node types enable this flexibility.
There are three node types in zenoh. Those types are as follows:
- Client: A node connected to one and only one peer or router. Zenoh clients are often constrained devices running zenoh-pico, a lightweight version of the protocol. Zenoh-pico cannot participate in mesh topologies.
- Peer: A node supporting peer-to-peer communication. Zenoh peers can route data on behalf of other peers.
- Router: A node able to route zenoh traffic between clients and peers. Routers are crucial in multisite deployments since they can bridge networks together, even over the public Internet. Zenoh routers also deliver features through plugins, such as distributed storage instances.
Figure 5 illustrates how the three node types fit into the infrastructure.
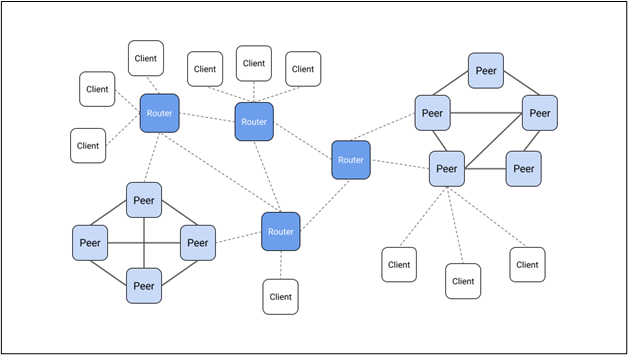
Figure 5: zenoh node types and topology (Credit: Eclipse Foundation)
Device Discovery and Connectivity
Like DDS, zenoh implements node auto-discovery. To keep the protocol efficient, the zenoh team minimized discovery traffic. Overall, the generalization of resource interests in zenoh streamlines the discovery process and makes it possible for the protocol to support Internet-scale applications. Zenoh performs resource generalization automatically, but you can use an API to provide hints to the infrastructure as needed.
Zenoh client nodes can connect to peers or routers. Zenoh peers can connect to other peers, routers, or both. This allows you to arrange nodes to meet your nonfunctional requirements. For example, deploying a mesh of peers in a specific location can remove the threat of a single point of failure in the infrastructure. Similarly, deploying redundant routers over distinct network connections can make multisite communications more resilient while enabling better system scaling. Figure 7-3 illustrates various potential topologies leveraging each node type.
One important detail about zenoh client and peer nodes is that their type does not constrain the operations they support. They can publish, subscribe, or both, depending on your requirements.
A current trend among IoT protocols is to support a wider variety of network transports. MQTT can run on UDP with MQTT-SN, for example. Given this, it is unsurprising that zenoh supports several transports out of the box since it is a recent piece of technology.
What makes zenoh unique is that it can run directly over an OSI level 2 data link without an intermediate transport. Of course, zenoh can also support TCP and UDP on top of IP. TLS is available for encrypted communications if you choose TCP. Moreover, you can also use TLS if you use the QUIC protocol, which relies on UDP. Finally, zenoh can also leverage shared memory and UNIX sockets transports.
To learn more about zenoh, please visit the official website at https://zenoh.io.
How do I Choose?
With the wealth of established and emerging protocols, choosing the right one for your project can be challenging. In my next article, I will provide a few pointers on how to do that. Thank you for reading, and see you next time!
—
Frédéric Desbiens manages IoT and Edge Computing programs at the Eclipse Foundation, Europe’s largest open-source organization. His job is to help the community innovate by bringing devices and software together. He is a strong supporter of open source. In the past, he worked as a product manager, solutions architect, and developer for companies as diverse as Pivotal, Cisco, and Oracle. Frédéric holds an MBA in electronic commerce, a BASc in Computer Science, and a BEd, all from Université Laval (Québec City, Canada).
Frédéric is the author of “Building Enterprise IoT Solutions using Eclipse IoT Technologies: An Open-Source Approach to Edge Computing,” published in December 2022 by Apress (ISBN: 978-1484288818).
[1] Those features are QoS 0, QoS 1, will messages, and the retain flag. See section 10.1.3 of the specification for more details.







