











With business initiatives such as DevOps promoting practices like continuous delivery, teams need fast answers to the question, “Does the release candidate have an acceptable level of business risk?” Yet, it seems that few organizations have reliable insight into this critical question.
In a survey conducted in the summer of 2017, more than 3,000 respondents were asked the question, “Do Tests Accurately Reflect Business Risk?” As the chart below indicates, 52 percent of senior managers and 45 percent of managers stated that tests do not accurately reflect business risk.
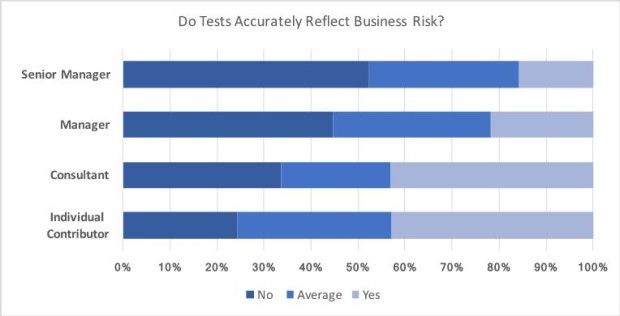
Note that more than 60 percent of individual contributors felt that their tests accurately reflect business risk, and yet only 16 percent of senior managers felt the same way. Upon further investigation, it appears that managers lose visibility into risk when practitioners focus testing on bottom-up testing of user requirements rather than a top-down (or end-to-end) assessment of risk.
This is driven by a number of factors — including agile’s focus on user stories and getting them all validated within the limited time available for testing. Ironically, while agile seems to be diminishing many teams’ insight into risk, its goal of fast and frequent releases make automated risk assessments all the more critical for the business.
[ Related: Choosing a Software Approach for Large-Scale IoT Deployments ]
This article explores a strategy for aligning testing activities with business risk — with the goal of enabling trustworthy go/no-go decisions at the new speed of modern business.
Why invest in risk-based software testing?
Shifting your testing strategy to risk-based testing does require some work. However, a relatively small investment upfront yields significant returns:
- You can understand what kind of test coverage you have versus your weighted risk. In short, it should give you the assurance of knowing whether any component of the application poses a high risk, and if that component is currently being under-tested or not tested at all.
- Once a test failure is detected, you will be able to prioritize it – so you can focus your resources on remediating the most impactful risks.
Here’s an admittedly simplistic example. What if your testing algorithm were to determine that your Twitter feed is broken? Is that important? It could be. But what if your Twitter log-in mechanism failed? That’s likely a higher risk. But would you know that from your test results without risk-based testing?
Creating the framework for risk-based software testing
It’s never going to be feasible to find and fix every issue with the application before each release. To balance speed with quality, you need to be able quickly determine whether you have a small glitch that can be fixed later or a true showstopper. This requires two things.
First, you need to ensure that tests that are truly aligned with risk. Tests that validate granular components of the application are great tools for letting developers know if their modifications break something. However, they’re not effective at assessing the user experience across realistic end-to-end transactions. Even an aggregation of smaller tests won’t provide the insight required to stop high-risk candidates from going out into the wild.
[ Related: IoT Applications as Varied as the Industries Deploying Them ]
Second, you need a taxonomy that defines the level of risk associated with each component of the application. Before you get started, you’ll want to ensure that you have a testing platform that lets you weight the components of the application under test within the context of business impact. Ideally, it should provide you a level of “coverage visibility,” and it should be purpose-built to rank, and therefore prioritize, defects.
Once you’re ready to start defining the required risk taxonomy, your first step is to assess the relative risk of one software component over another. Keep in mind that if we are measuring risk and business impact, we cannot simply isolate our testing activity to a single application. We must shift the focus to and end-to-end transaction that crosses multiple applications, APIs and backend infrastructure.
How can you figure out the relative risk of software components in relation to the business? Start by considering two questions:
- How often is a component called? Some components may be used in daily business, while others may be used only infrequently, such as once per quarter. Some may be used by multiple users, some by a few users. Give priority to the components that are used most often and heavily.
- What is its potential damage? Determine the relative importance of the component in relationship to business-critical transactions. If the component were to stop working, would it crash the whole program and halt critical business functions? Or would it simply be an inconvenience that could be worked around?
Here is a real-life application from financial services – securities trading – and how risk can be assessed:
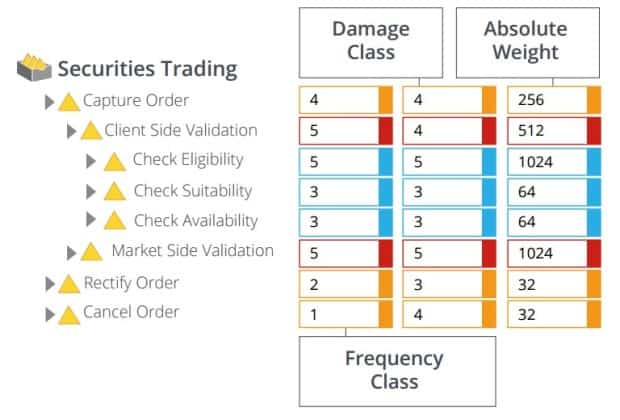
Figure 1. Risk Measurement in a Securities Trading Application
Frequency Class refers to the frequency with which an activity is commonly executed. Damage Class refers to the potential damage, or risk, of an error in the execution of an activity. Absolute Weight is an assessment of weighted risk.
How machine learning assists with risk-based testing
Many test methodologies today can observe transactions and display a set of transactions, but they lack the means to aggregate them into a histogram of transaction paths. However, newer methodologies can scan and observe what an application is going to test, collect an inventory of all fields and their objects, and “understand” what the application is trying to accomplish. That happens through machine learning.
It should be noted that machine learning engines vary in their capabilities. If the machine learning engine in use cannot recognize objects and create declarative values that can be associated with those objects, machine learning will fail because it distorts the data that it’s trying to observe.
Here’s a real-life example of objects and how they complicate testing. The initial release of SAP Fiori had over 200 unique objects associated with it. Within those objects, if you were to calculate permutations, you would find more than a million types of subcomponents associated with just those 200. Then, if you were to take another set of combinations – in this case, the combinations of interactions between the elements across all 200 – the results of this combinatorial equation would result in exponentially higher numbers.
This is not a job for manual testing. That monumental task requires automated, risk-based testing with integral machine learning.
Risk is a component of every application in existence, no matter how small the risk may be. In the enterprise, the risks of software failures are very real, ever-present, and frightfully costly. When risk can be mitigated by risk-based testing in pre-production, nightmare scenarios of production software failures can be reduced, if not eliminated.







