











The idea of intelligent, reasoning computers has captured people’s imagination for decades and has sparked both fascination and concern. Could computer systems really possess advanced cognitive abilities similar to humans, and if so, how far would – or can – they go? Would they be able to exhibit intelligence, reasoning, learning, and problem-solving capabilities, enabling them to interact with people in a meaningful way? After all, isn’t the abstract power and ability to assign context and meaning through connections to disparate thoughts what makes us fundamentally human?
These questions inevitably lead to discussions about consciousness, what constitutes human intelligence, the Turing Test, and whether being able to automate tasks competently is a sign of intelligence or not. These are weighty concepts and all too often lead to the human vs. machine argument. Today, organizations prefer to focus their attention on semantic technology as a way to significantly increase the capabilities of computers and enable them to extract facts from vast amounts of information, derive new knowledge from explicitly stated facts, and detect patterns that individuals would otherwise have difficulty detecting.
Uncovering Meaning and Relationships
Semantic technology uses the branch of linguistics and logic concerned with formalizing meaning to enable computers to handle information the same way as humans. For instance, graph databases are designed to consider the relationships between data elements (e.g., entities or concepts) to be just as important as the data elements themselves. Specifically, graph databases organize information in a graph structure, where nodes represent things and edges represent the relationships between them.
Beyond basic graph data representation, knowledge graphs (KGs) use conceptual models with formal semantics, known as ontologies, as data schema in order to allow deeper interpretation of transactional data or documents. These models include many types of knowledge, such as:
- Entity relationship models, like the one behind the schemata of the relational databases, unified modeling language, and object-oriented programming.
- Named entities such as people, organizations, and locations.
- Reference data, used to classify or categorize other data, including units of measure and codes, as well as controlled vocabularies of terms and taxonomies of topics.
- Technical knowledge, e.g., the configurations of all devices in a building, used to better interpret the sensor data and economize heating/cooling energy.
- Product information of the sort managed in product lifecycle management and product information management systems.
- Scientific knowledge, e.g., chemical compounds and drug names.
This way of modeling knowledge captures the semantics of the data and makes it not only machine-readable but also machine-understandable. It allows graph databases to store, manage, and find information based on its meaning rather than strings of words. It also enables them to handle massive amounts of data, regardless of type, and be extremely flexible, so the ontology models are easy to evolve and extend when new types of data are added, or new kinds of queries need to be supported. Leveraging semantic technology and semantic graph databases to work with their content, organizations are able to reuse information, save costs, and gain new revenues.
See also: Artificial General Intelligence (AGI): AI’s Next Phase
Deriving New Knowledge from Context
According to Forrester, KGs are a valuable instrument for maximizing the value of data, enabling businesses to extract knowledge from vast quantities of data. They provide deeper insights for organizations to solve data-related challenges, enhance customer experience, complement AI capabilities, and detect fraud. If you haven’t heard of KGs, chances are you have already interacted with them, as this is what powers Google, Facebook, Amazon, and many other applications we all use regularly.
KGs provide semantically consistent unified views across data derived from different sources. This is key because valuable insights are gained when data from one system is used to complement or put in context data from another system. However, combining information across systems bears a high risk of misinterpretation of the data, which can, in turn, bring inconsistency and incorrect conclusions. To eliminate the chance of misinterpretation, ontologies establish an agreed-upon meaning between the producers of the data and those consuming it.
Being able to access all this data in a single place is powerful enough, but graph databases take knowledge extraction and sharing to the next level. Based on the existing data and a formal set of inference rules, graph databases can perform logical deductions and infer new facts. As a result, a KG can essentially create more data than the sum of its original datasets.
Deriving new information from existing facts adds extra explanatory power to knowledge discovery and enhances data-driven business analytics. This is what differentiates a generic graph structure from a KG model. It also helps identify inconsistencies, which is especially valuable when adding new data. Without KG’s data discovery and inference capabilities, enterprises lack the semantic findability of information. Instead, they have to go through the painful process of locating insights relevant to their business needs and translating it into a machine-readable format. They would also need to store it, which demands substantial storage capacity, and continually update and maintain the knowledge base to ensure all assets could be leveraged.
Discovering Unknown Relationships, Patterns, and Insights
When humans come across facts, they apply them to their existing knowledge and understanding of the world. This enables them to find relationships between these facts and what they already know and to see patterns. In other words, previous knowledge puts new facts into context and allows individuals to create shortcuts when new information is introduced.
Think of the brain as a huge Knowledge Graph in our head. Each time something new is introduced, we don’t need to navigate all of our human computing power to know what to think about the new information. In the same way, large KGs rely on ontologies and other models of organizing and representing knowledge to provide context to data and allow computers to read between the lines.
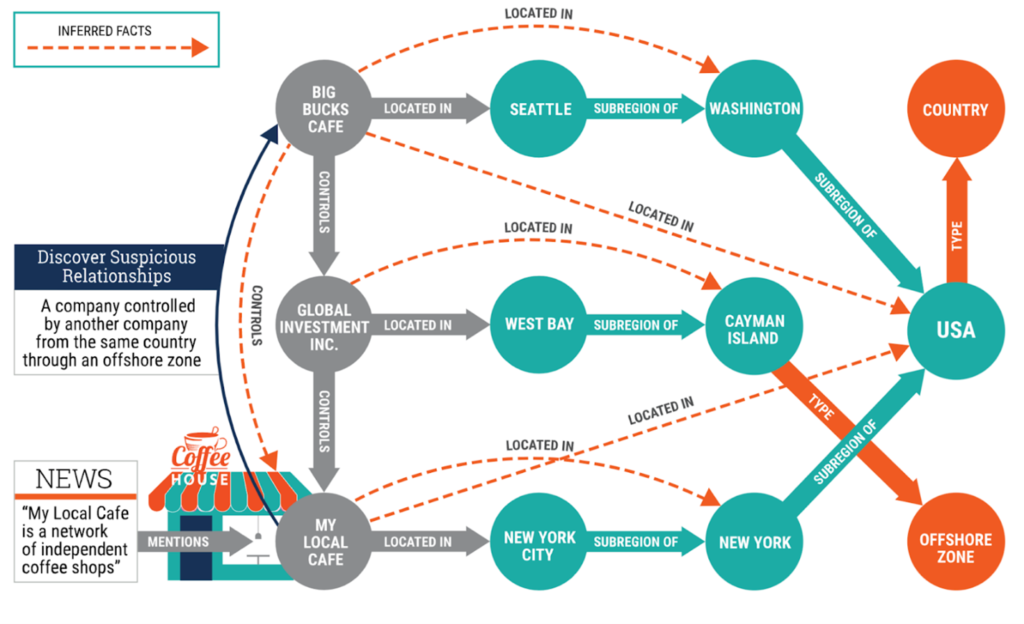
For example, imagine that an investigative journalist is looking into the claim that a company called My Local Café is “a network of independent coffee shops.” A KG can put data ingested from disparate sources, such as Dun & Bradstreet, GeoNames, etc., into the context of the GeoNames ontology, which is a formal description of knowledge within a domain. This makes it possible to add geospatial semantic information to the World Wide Web. Based on existing facts and relationships, the reporter could discover that My Local Café is actually controlled by Global Investment Inc., which is controlled by Big Bucks Café. As a result, they could safely infer that Big Bucks Café controls My Local Café as well and that My Local Cafe is not independently owned at all. What’s more, they could also discover a suspicious relationship between Big Bucks and My Local Café, as the company is controlled by another in-country company through an offshore zone.
The problem is that without semantic inference capabilities, discovering patterns in big networks of interconnected entities tends to be computationally expensive and slow for graph databases. The relationships that the engine was able to infer (painted with dashed arrows on the diagram) serve as a sort of shortcut that makes finding patterns across multi-hop relationships much faster and precisely what the human brain does when information is rationalized. Ontologies allow computers to do the same because they help them understand the meaning of the different types of relationships. For instance, the formal semantics of the relationship between companies A, B, and C is that it is a transitive one. This means that each time A controls B and B controls C, A also controls C and all the other companies down the chain.
Delivering on the Promise of Intelligent Computers
By representing complex relationships in a machine-readable way and by their automated reasoning capabilities, semantic KGs revolutionize enterprise data management and make the process smarter and more accessible. They enable computers to interpret data more accurately, understand the knowledge locked in it, uncover hidden dependencies, detect complicated patterns, identify trends, and provide predictions – much like humans do in the real world.
Over the years, the field of AI has made significant progress, developing computer systems that can perform tasks that typically require human intelligence, such as understanding natural language, making decisions, and even exhibiting creativity. And, while the development of truly intelligent computers remains an ongoing area of research and exploration, semantic technology, and semantic KGs in particular, continue to push the boundaries of what intelligent computers can achieve.







