











I recently stumbled over a great slide deck presented by Netflix engineers about “Design Patterns for Real World Machine Learning Systems.” The presentation warns of a dangerous “anti-pattern” when applying analytic models to production systems.
The anti-pattern, aka the “Phantom Menace,” basically involves using different platforms, tools and technologies to develop and deploy an analytic model. That is, developers use different code, data, and platforms for training an analytic then deploying it. Unfortunately, many enterprises actually do this in their projects, and it can be disastrous: Machine-learning analytics are deployed in use cases such as predictive maintenance, cross selling, customer churn, fraud detection or sentiment analysis, to name just a few examples.
The anti-pattern and analytic models

Why use different technologies to train and deploy an analytic? What happens is that a team of business analysts and data scientists develop and train an analytic model with a technology they like and understand. The analytic models work well and validate predictions with high success rates. Wonderful!
Yet the development team struggles. They cannot deploy the created analytic model to production systems, nor apply it to new events in real time. Usually, the technology used for the model is not appropriate for deployment in the existing environment or it simply does not perform well.
What happens next? Developers have to redevelop the analytic model with another technology to bring it into production. What a mess!
What’s more, think about the typical closed analytics loop which includes re-training, re-validation and improvement of existing models. All that work has to be done twice. This is the opposite of an agile and innovate analytics process that most enterprises urgently require today.
Realizing a closed analytics loop
The following picture of Netflix’s slide deck shows the “typical” machine learning pipeline where you do not apply this anti-pattern:
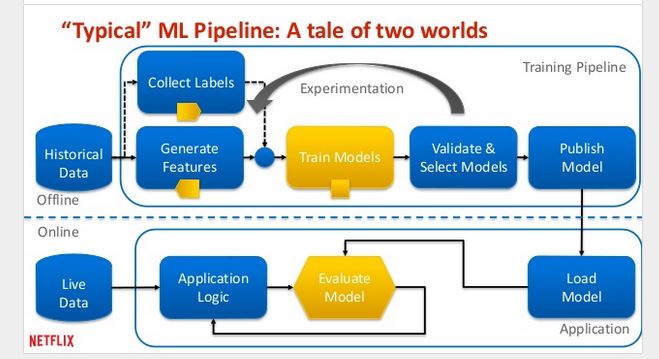
You use the same analytic model without redevelopment in the training pipeline (offline) and real-time application (online). That sounds easy in theory, but it’s not so easy in practice due to the number of analytic and machine learning tools available.
Platforms, tools and technologies for advanced analytics and machine learning:
- Programming languages such as R or Python
- Open source frameworks such as Apache Spark ML, H2O.ai or Google’s TensorFlow
- Commercial tools such as SAS or MATLAB
- Others… We will see many new technologies emerging in the next years. Be ready to adapt new ones into your process and tool stack.
There is no silver bullet in machine learning, unfortunately. All these alternatives have a right to exist, and each has pros and cons. Besides, different groups of users have their favorites (due to different historical, technical, organizational or political reasons). So, how to implement an analytics project? How to be avoid the “phantom menace” anti-pattern?
Key success factors in a real-world analytics project
1. Business analysts, data scientists and developers have to work together!
The business use case must be developed before business analytics and data scientists build an analytic model! They have to work together with the developers from the beginning. Think about how to bring it to production afterward for new proactive actions in real time. Think about how you need to scale it. Think about how many events you have to process (e.g. internet of things or predictive sensor analytics might require a much higher number than some occasional evaluation of a weather forecast). Think about how to change, improve, and re-deploy the model afterwards. Think about how to allow a closed loop – maybe even an automated one.
2. Integrate different analytic models and technologies into one visual analytics tool
Another key for success is to be able to integrate all these different platforms, tools and technologies into a single visual analytics tool to find new insights and to create or improve analytic models. Business analysts do not care about which algorithm or technology is running under the hood. They just care about the outcome. They have to be able to leverage the analytic model under the hood without knowing any details. He can just select and apply different attributes to re-evaluate the analytic model under the hood. And she can even switch and leverage different analytic models to find out which one works best for the specific business case (like finding the highest possible cost reductions in a manufacturing process by applying an analytic model).
3. Deploy and apply an analytic model to real-time processing without re-developing the model
An analytic model has to be deployed and applied to a production system without re-development. This way, a business can easily improve the model, adapt to changes and stay agile. Changing business processes and models forces a company to innovate.
Businesses today have to be more agile than their competition, which is not just “legacy competition” but also new emerging startups with millions of venture capital in the bank. Therefore, a company should be able to deploy different analytic models (with different technologies) in a similar way – for instance, replacing a connector for R with a connector for Spark ML or H2O.ai, but keeping all the other parts of the streaming analytics process the same as before.
Tooling needs to allow a company to:
- Integrate different technologies such as R, Apache Spark ML or SAS into a tool set.
- Visual analytics for data discovery to find insights, including inline data preparation for agile analysis of combined data structures.
- Streaming analytics to apply the analytic models to proactive real time processing.
Fortunately, the same analytic model (e.g. clustering, random forest) can be deployed without redevelopment for different use cases such as customer churn and predictive analytics. Different tooling for visual analytics, smart data discovery, advanced analytics and machine learning can be deployed.






