











The paradigms, tools, and platforms we use or are familiar with influence our innovation approach and how we build solutions. We often use familiar “bottom-up” technology approaches. But this inclination towards the easier and familiar approach is at its core a digital transformation debt that keeps accumulating. It does not often challenge long-held convictions that could be at best sub-optimal and at worst detrimental to the enterprise.
There are many CIOs and IT managers who have chosen specific architecture patterns and technologies because that is what they have done in the past, and that is what they are familiar with. It is not necessarily what the enterprise in-motion needs or could achieve for innovation. Stretching, being challenged, and possibly disrupted with a different approach is not comfortable!
In this two-part article, we will contrast two leading paradigms for innovation using digital technologies and platforms: Process and Data-Driven. Part I provides the background, and Part II will delve into three important innovation use cases for business value.
See also: Business Benefits from Industrial IoT, at Long Last?
Process and Data are not the only paradigms for application development in the digital era. There are many others, some of which are complementary to either approach. However, they are the two most important and enterprises in-motion embarking upon a digital transformation journey cannot afford to ignore them.
Setting the Stage
The Enterprise-In-Motion needs to innovate continuously. But how? Innovation methodologies, workshops, and techniques such as Design Thinking are good and helpful. But at some point, innovation must be implemented and digitized to yield value. Technology stacks and options are complex. There are too many digital technologies trends du jour cluttering enterprise software systems. Consider how the “Top Ten” technology trends are changing over the years. Point solutions, systems of records, as well as software platforms that were a “must-have” a couple of years ago, are becoming legacy at an accelerated rate.
Now, to keep up with disruptive challenges from competitive incumbents or emerging disruptors, digital enterprises need to accelerate innovation. In other words, they need to be in-motion and autonomic. But here is the challenge. What are the leading paradigms or approaches for innovation, and what are their tradeoffs? How should the innovators build enterprise applications? What are the paradigms, techniques, or approaches in enterprise application innovations? Simply, how should applications be developed? What are the must-have components or layers in a robust next-generation digital transformation architecture?
These are make-or-break questions for the enterprise. The answers are not that easy. Enterprise reference architectures and stacks are becoming increasingly cluttered and complex. Think of the spectrum of digital technology, language, platform, and point solution choices! There are too many options, and their tradeoffs are not that clear. Every organization is doing it differently, and this simply does not add up!
What’s needed is a pragmatic approach that focuses on two complementary and core approaches for enterprise application development: Process and Data. You can’t get more basic than that! There are, of course, others and numerous hybrids. But highlighting, contrasting, and complementing these two is key. As we shall see, especially in the use cases of Part II, a healthy and robust approach can be instrumental for innovation with business value.
Back to Basics: Program + Data
There are now tens of programming languages. Every year there are new programming languages that are attempting to gain a beachhead in the already cluttered programming space. The following lists the top 10 programming languages in 2019. It includes rather old and dated languages such as C and even Java. It also includes the world’s most popular database language: SQL! The syntax and semantics – reflecting the underlying computational models – could be quite different. But there is a fundamental commonality behind all programming. The execution of the program manipulates data! Variables in the program represent data. The interaction with external systems could be done through sending & receiving data, processing events, or invoking programming interfaces (called “API”s).
This duality of execution programming logic while manipulating data has been around since the inception of computers!
The focus of this article is on the dynamics between two complementing paradigms: Data and Process.
Using the programming language analogy, the “Data” corresponds to the variables manipulated in the program, and the “Process” corresponds to the procedures and functions of the program.
Now the terms “Data” and “Process” are overloaded. Each has its own characteristics, models, and capabilities. Data, for instance, can be transient or persistent. It can be simple (such as a number) or complex (such as an address). Similarly, processes can be simple workflows often depicted through flowcharts or swim lanes; or dynamic and complex via adaptive value streams or value chains. Each of these has emerged into formidable enterprise software domains with various products (Database Management Systems and Business Process Management Systems), methodologies, technologies, and solutions that are often essential for the digital transformation of the Enterprise-In-Motion.
So Why DBMS & BPMS?
As computation evolved, several explicit separations emerged. It used to be that an application manipulating data, rules, and flows – including data, rules, and flows that persisted across multiple program executions. These were combined in its programming code with all the application logic. The separation transition started with the separation of the management of the persistent data of enterprise applications. This led to the emergence of Database Management Systems.
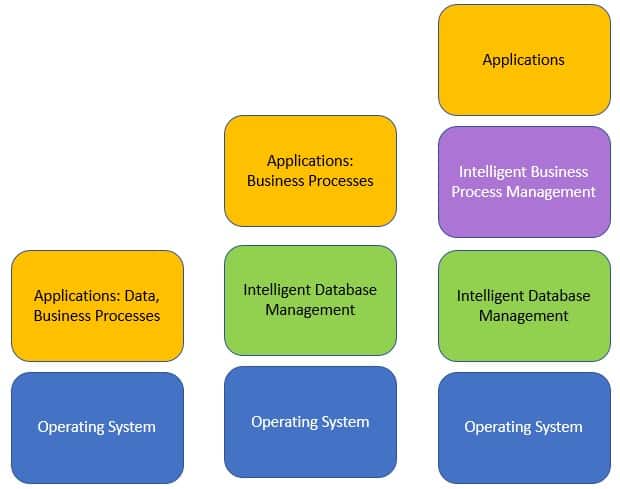
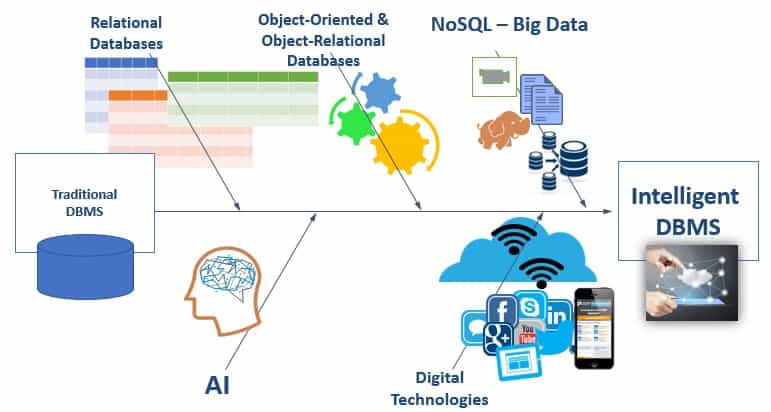
In the initial phases of the separation trend, the business logic – especially the processes (aka workflows) and business rules – were still part of the application. DBMSs that separated the management of the data from the application started to appear in the 1970s with navigational hierarchical and network models. In the 1980s, we saw a significant evolution to relational databases that became quite popular, especially with the emergence of SQL as the de-facto query language for databases! The evolution of databases from relational included Object-Oriented Databases that combined Object-Oriented and Database capabilities for persistent storage of objects, as well as Object-Relational Databases that attempted to combine the characteristics of both relational and object-oriented databases.
More recently – especially for handling large unstructured multi-media data in new digital applications – we saw the emergence of NoSQL (which more appropriately stands for Not-Only-SQL) to handle the demands of Big Data – such as large volume, variety, velocity with heavy demands on scalability, performance and fault-tolerance for modern data-intensive Web and Service applications. Data-centric application development commences by creating Entity Relationship models of data with entity type and the relationships between the entity types.
The DBA, together with the data analysts, creates the data models. However, emanating from digitization trends, the introduction of NoSQL databases especially for Big Data management, there are significant changes in designing, managing and maintaining physical repositories of databases: object-oriented, graphical, document-oriented, etc. Each has its sweet spot and purpose.
The focus of this new generation of databases is to deal with the explosion of heterogeneous data and the storage and management of this data for innovative Internet applications (especially IoT). Still, by and large, most transactional data for mission-critical systems of record (which require transactional integrity) remains relational. Interestingly, in the early 1990s, we also saw the emergence of intelligent DBMSs. SQL – the de-facto and most popular database language – has continuously been evolving. It has incorporated many declarative AI capabilities. Similarly, NoSQL databases are incorporating analytics capabilities – including for unstructured multi-media data within the DBMS.
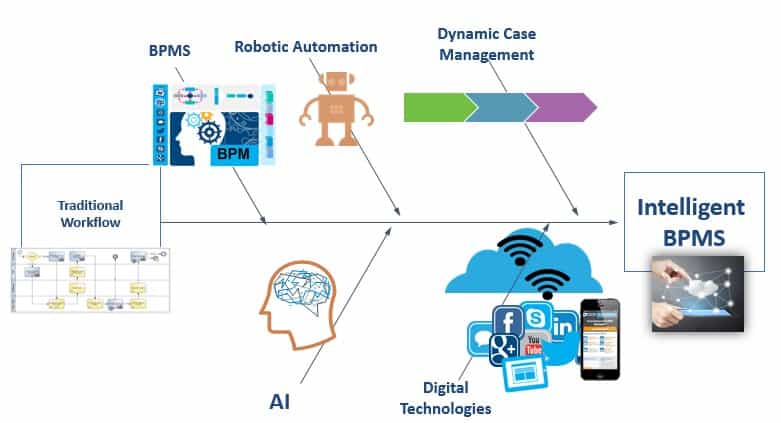
The evolution of improvement in process efficiency and productivity within organizations goes back to Taylorism and Scientific Management. In the 1990s, business process re-engineering took a top-down approach for process improvement and reorganization. Due to the radical amount of change attempted, most re-engineering initiatives failed. Process improvement methodologies, such as Lean and Six Sigma, attempt to eliminate waste in work processing, while increasing the efficiency as well as the effectiveness and quality of products or services. Theory of Constraints and Net Promoter Scores (NPS) provide other robust frameworks for process improvement. The key point is that, whether improving NPS or critical-to-quality measurements for a Lean Six Sigma project, the intelligent Business Process Management approach allows organizations to keep these measurements as well as control the customer experience and operational efficiency in real-time.
As platforms that digitize and automate business processes, Business Process Management Systems have evolved from human-centric and document-centric workflow systems to more comprehensive digital transformation platforms. Workflow products, at least in the earlier stages of their evolution, were document, forms, and content-centric. In fact, some of the earliest implementations of workflows focused on converting and processing paper-based documents through digitized media. Thus, scanners, specialized monitors for entering data from scanned documents, as well as backend optical repositories were integral parts of the workflow.
The main difference between the workflow systems up to the mid-1990s and the emergence of BPM systems of today is the involvement of system participants. BPM has its roots in human participant-focused workflow systems. The coordination in this category is human-to-human. While some BPM technologies and methods are still purely workflow-focused, BPM is much more than that.
Other significant categories of software that have influenced the evolution of BPM include Enterprise Application Integration (EAI) and Business-to-Business (B2B) integration. These were subsumed by Enterprise Service Buses and Service-Oriented Architectures. Inclusion of system participants meant that in the same process flow some of the steps were performed by backend applications such as enterprise resource planning (ERP) systems, human resources applications, or more generically Database Management Systems (DBMSs).
One of the earliest definitions of BPM included enterprise application integration as well as human-centric workflow and trading partner business-to-business (B2B) integration.
As BPMS became more intelligent and advanced, Business Rules and AI analytics capabilities became unified within the BPMS, and thus, we saw the evolution of intelligent BPM. Intelligent Business Process Management (iBPM) is a digital transformation discipline with the associated automation platform that aligns business objectives to execution. There are several trends that have influenced the evolution of iBPM – making it the core engine of transformation for digital enterprises. Two of these trends are the process participants and process intelligence.
Robotic Automation started to become incorporated in robust Digital Process Automation (another way to designate iBPM) platforms. Next-generation iBPMSs support the entire spectrum of work automation: structured, cognitive, and AI-assisted. Also significant is the emergence of Dynamic Case Management to handle ad-hoc work and provide a more powerful model (compared to flowcharts and swim lanes) to work orchestration.
Unequally Yoked – Not Two Sides of the Same Coin!
Given the separation trend that was summarized above and the evolution of intelligent database management and business process management, one would assume enterprises will readily strategize on DBMS and BPMS platforms as core capabilities to support Process + Data in their enterprise architectures: as a necessary and core component of their solution stacks. They will need and use the two complementary paradigms and systems.
That is simply not the case. Many organizations have enterprise architectures or reference models that have an underlying DBMS layer, but the BPMS layer is missing. No “respectful” enterprise architecture can exist without one or more relational DBMSs and increasingly several NoSQL databases for unstructured data management in emerging applications.
Understandable. But often BPMSs are either completely ignored, postponed or diminished. IT organizations are not pursuing the procurement of BPMS with the same vigor as they are for emerging Database Management systems – especially the more recent and exciting NoSQL databases for Big Data!
Why is that? There are several reasons. Here are some of the common explanations or situations that I have seen over the years:
- We have processes or workflows in our ERP systems
- At some point we will consider a business process system – it is too early for us
- We have Low Code/No Code tool – we do not think we need a BPMS
- BPMS do not do anything: they do not come with any business logic: we must develop it. Not sure what they do!
- We need to have our databases – they differentiate us. We are not sure about the processes. We can code them.
- Data is the new crude oil. AI extracts or mines the valuable “oil” from the data lakes. Not sure about the Process!
There are others. Each of these “reasons” – if we can call it that – is false! Processes are assumed to exist in the “Application” layers. This has several implications. IT organizations have a budget for DBMSs. But not for BPMSs. As indicated, one of the criticisms of BPMSs that is occasionally voiced is the fact that a BPMS as a tool or platform does not do anything. It allows you to model processes or value streams. But you must use the tool to come up with the solution. It does not come with running and ready software out of the box – unlike ERP systems, for instance, for financial services or HR or IT processes or even CRM. True. But the same is true of DBMSs!
The Database Management system also is just a tool to manage databases. It does not come with intellectual properties for a specific application domain. You must develop those. You must model, design, and implement your databases with a DBMS. Similarly, you must design, model, and implement your processes with a BPMS. Interestingly, due to the inherent need to manage databases for enterprises and the popularity of databases as the new crude oil that contains treasures that could be mined through AI, this objection is not raised for DBMSs. It is raised for BPMSs. This is sub-optimal, does not support the tenants of the enterprise in-motion and in some cases could be detrimental to the organization.
Part II of this article will delve deeper into this digital transformation challenge and illustrate through three pragmatic use cases how a top-down approach could be ideal for the enterprise in-motion: optimizing the Process + Data synergy!







