











Online shoppers demand fast response times. According to a 2017 Akamai study every 100-millisecond delay in website load time can hurt conversion rates by 7%. Response times can be even more critical during peak holiday shopping seasons.
At PriceRunner, we process price updates from 18,000 different merchants for 4.4 million unique visitors per month. In addition to finding the best deals today, we also run machine learning algorithms to predict future prices to enable shoppers to determine the best time to buy.
We have to store and analyze huge amounts of data from various sources, with millisecond performance and anticipate future price changes in microseconds to provide a quick and seamless customer experience. This becomes even more critical during peak traffic periods like Black Friday, when bursts of traffic are typically twenty times more than the normal load. Today, everyone expects an instant response, and even a few second delay on a price comparison site can result in a customer giving up and abandoning a session.
In-Memory speed, predictability
Our previous system had some technical challenges when trying to scale up to ingest and process large volumes of data. To prevent any future performance problems we rebuilt our entire system based on GigaSpaces in-memory computing platform so we could rely on main memory for computer data storage. Utilizing in-memory computing, data is stored in RAM across a cluster of computers on a speed layer rather than being stored in a centralized database. Accessing data in memory eliminates seek time when querying the data, which provides faster and more predictable performance than disk storage.
This architecture also provides the elasticity that we need. When the system needs to scale to meet increased data loads, the in-memory computing platform dynamically expands the application onto additional physical resources automatically and on-demand. Resiliency is guaranteed with in-memory backup within each container, and by mirroring data to a traditional database outside the runtime.
All of our data for products, offers, categories, brands, merchants, user data etc. is stored in the in-memory computing platform. Utilizing streams and queues we receive from Kafka we have a real-time system for product and price comparison that provides us with the scalability and performance we need.
PriceRunner data pipeline
With all these features and tools enabled and running optimally, we’re able to read millions of data updates from different sources. Each day we collect 200 million offers from more than 18 thousand merchants. This is an ongoing process running 24×7 which is required to ensure we can provide the most current prices for all the products users want to buy.
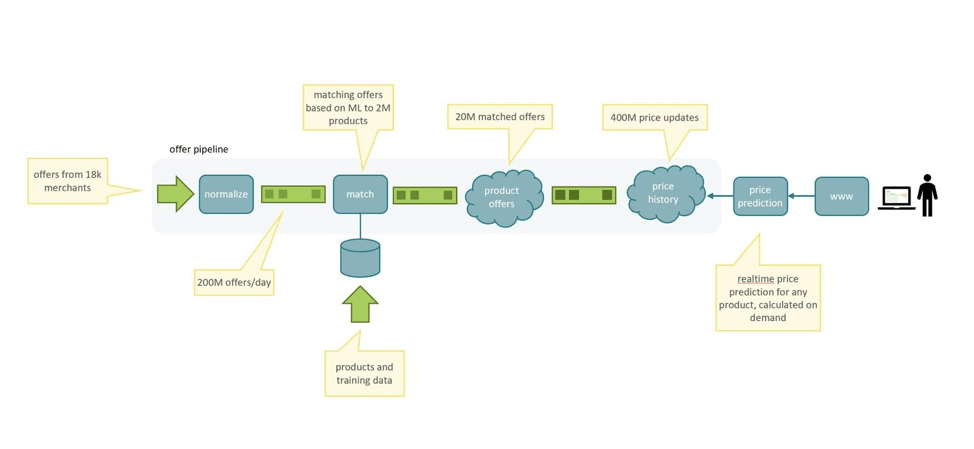
Each offer contains several different data values such as product name, brand name, price, currency, stock status, shipping cost, etc. This data is retrieved from various sources in many different formats so the first thing we do in our offer pipeline is to normalize this data so it is has a common structure. The normalized offers are put in the offer queue (managed by Kafka). The normalized offer is then processed by our matching engine based on machine learning. The matching process tries to match the offers with more than two million products.
Matched offers are put in the product offer queue and then consumed and stored by our product offer service running GigaSpaces in-memory computing platform. If the price in the offer is updated, we put the offer in the price update queue.
See also: Real-Time Sentiment Analytics Becomes Fashionable for Retail
We have multiple functions which utilize updated pricing information. For example, we provide a price alert mechanism to our users so they can be notified through different communication channels if the lowest price has changed for a product.
Our users also receive a price history graph where they can visualize the lowest price for up to a year for any product and/or select specific merchants’ price history for any product. To feed the price history service we store all prices updates from all merchants and products. Currently, we have more than 400 million price updates.
The client gets the time series and renders the graph on the client side for each request. This time series is also applied to our price prediction service so that when a user displays the price history for a product we also render the predicted price trend for that product.
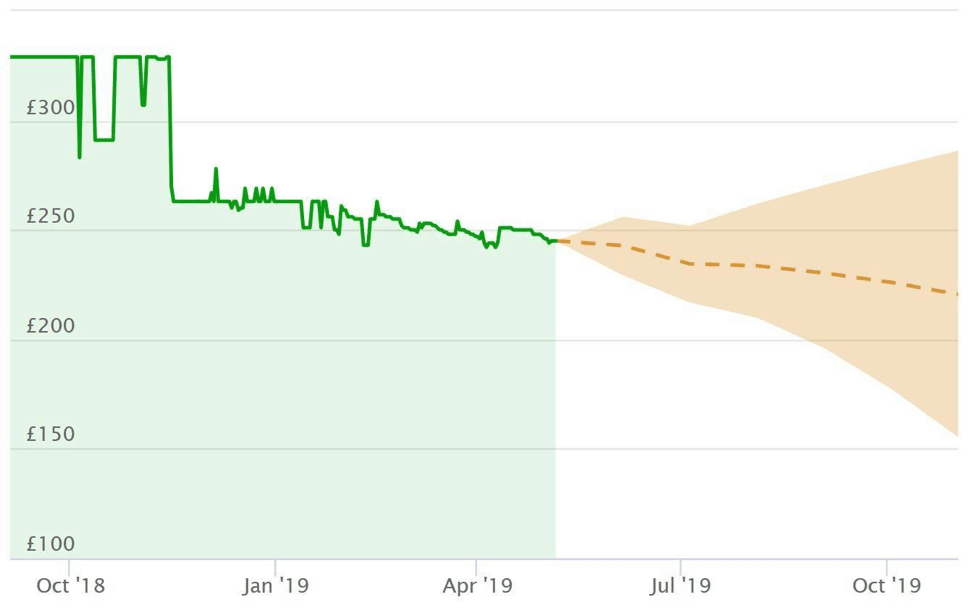
We are using Facebook’s open-source library Prophet for prediction. This prediction is CPU intensive and time-consuming even though we have all data in-memory and can scale out the computation. So for some cases, we pre-calculate the prediction with a consumer of the price update queue. For example, we pre-calculate the prediction for popular products and also groups of products where we want to build up a trend based on more than one product, like the price trend for Apple or Samsung mobile phones.
Working with all of this in-memory means that despite an increasing number of data sources or data volume, performance and analytics stay consistently fast. Our data pipeline runs on schedule despite the strain of traffic bursts. Last Black Friday, we had 100 percent uptime with no interruption of service. When visitor traffic was 20 times higher in parallel with 100 million price updates, response time for the 95th percentile of the product page endpoint rose from 5 milliseconds to just 8 milliseconds. We expected that there would be some increase due to the increase in volume, but met our goal since this delay is well below the danger zone according to stats recently released by Google that begins tracking bounce rates after page loads exceeding one second.
Timing IS everything
In our business, the timing of insights means absolutely everything. So far, we have succeeded in providing real-time comparisons and predictions. As our data volumes continue to multiply, we are fully committed to finding innovative ways to expand the quantity and accuracy of our recommendations while still maintaining the same high level of performance.







