











Three new reports from Gartner bring into sharp focus the increasing urgency for enterprises of building value-generating operational applications infused with AI and ML – or risk falling forever behind.
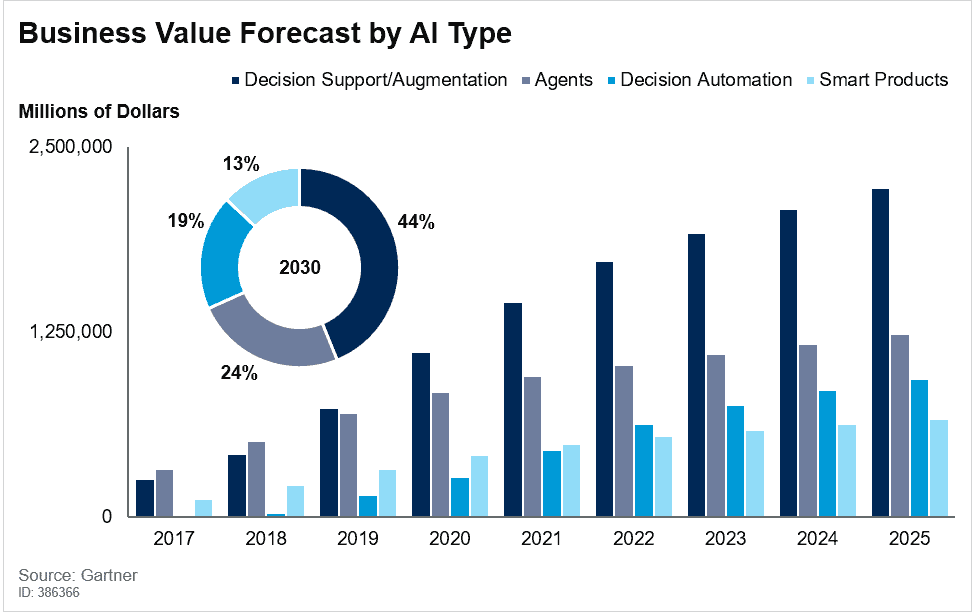
Urgency Builder #1: In its latest AI business value forecast, Gartner says that AI augmentation will create $2.9 trillion of business value in 2021. That’s in just one year.
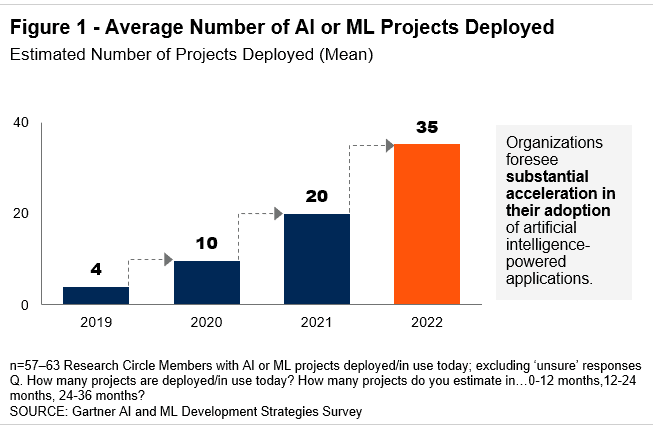
Urgency Builder #2: Gartner’s AI and ML Development Strategy study finds that leading organizations expect to massively increase their AI/ML projects – from a mean of four this year to 35 by 2022.
Urgency Builder #3: In its “Predicts 2019: Data & Analytics Strategy” report, Gartner says, “Effective data management is more critical than ever. While some companies have taken control of their data and turned it into a weapon for securing market dominance, many others are struggling with an issue that is putting the brakes on intelligence coordination: silos.”
See also: How to Speed AI Deployment to Achieve CI Benefits Faster
Gartner’s “leading organizations” are the ones out front in the race to grab shares of that $2.9 trillion in business value that will flow from AI, ML, and IoE initiatives around decision support, real-time decision automation, and AI-augmented intelligence, among others.
What’s Holding Companies Back?
Siloed data isn’t the only thing undermining efforts to build IoE applications and deploy ML and AI projects. Inflexible, legacy systems unfit to handle time series data associated with IoT, and real-time operations can also confound.
Where does your organization rank in the race to realize value? How are you helping smooth the road to deploying AI or ML projects and IoE applications? If you’re like many companies, your efforts are facing several key challenges, starting with siloed data.
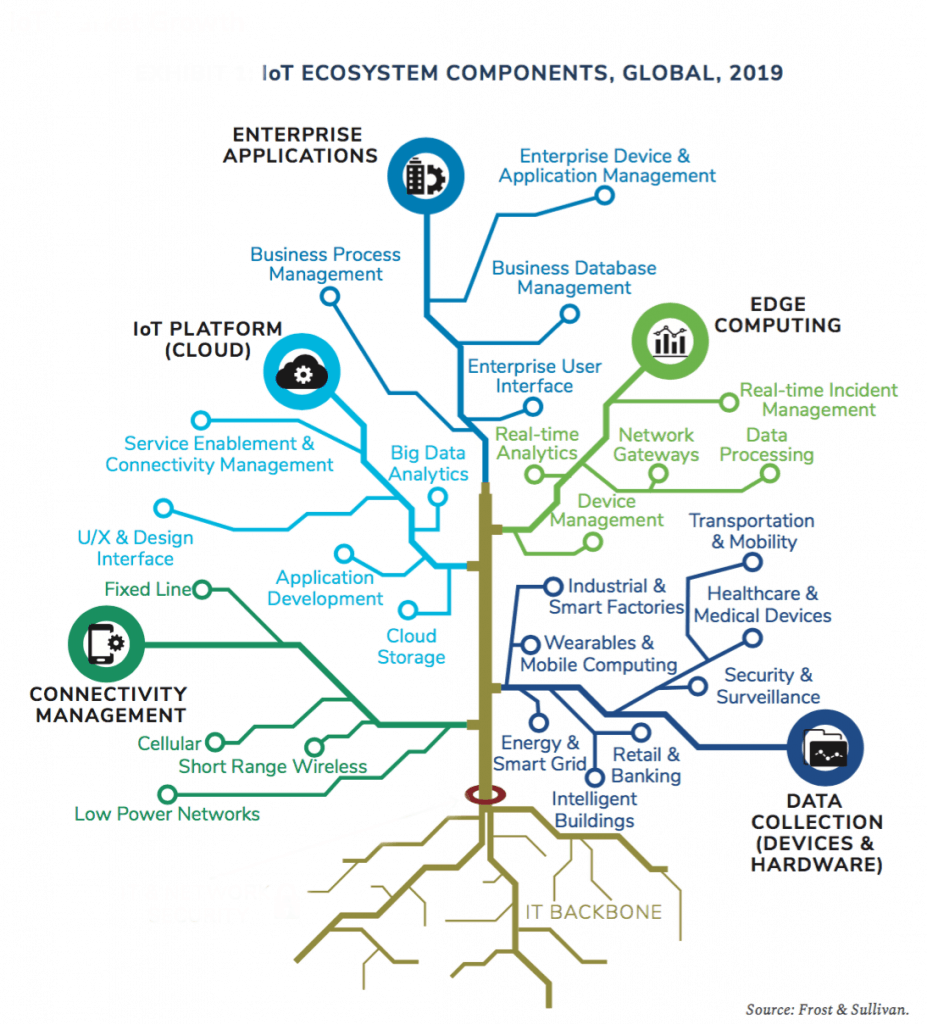
The inability to bring data together from disparate sources and render a holistic view is a main driver for why some companies are struggling to keep up, even before considering their Internet of Everything (IoE) application requirements.
For years they committed to data siloes forced on them by generations of industry-specific, narrow-function SaaS and enterprise cloud applications. But now they’re hitting the analytic limits of segregated data and discovering they can’t holistically analyze or act on their data as it exists or easily deploy it to newer generation applications.
Making Data the Center of Gravity
To succeed, all ML and AI efforts must be grounded in data. We view every process automation requirement through a data lens first. It’s the center of gravity for everything that we do, every process that we automate, and every real-time decision or action that we enable.
While we’re optimized first for sensor-generated time series data, it really doesn’t matter what type of data it is, what source it comes from, or in what volume or velocity – data is our root cause. Building the data automation foundation for data-agnostic applications enables silo-busting data unification progress in the fractured world of enterprise SaaS.
We think of it as an omnidata approach – something you’ll be hearing more about as data management requirements for sensor networks enable omnidata benefits elsewhere in the enterprise.
Prevailing marketplace approaches rarely follow this edict. Talk to a typical IoT company, for example, and they won’t have a good story around how they bring people into the equation. They’re all about things. Similarly, location data services and workforce management providers talk a good story around tracking people and workers but have little credibility for integrating things.
This is one reason IoE is far more present in our communications than IoT. Most enterprise operating problems involve people and things in equal measure. From a data perspective, there is no difference or bias.
The Old Data Management Order is Out
Data operationalization is creating vast new challenges to the old data management order. Whether they know it or not, enterprises are entering a “post database management system (DBMS)” world. They are finding it increasingly difficult – if not impossible – to shoehorn data-in-motion use cases into rigid, legacy DBMS infrastructure.
Data requirements for software applications have changed dramatically. Both users and machines are creating more data to drive business logic using techniques such as real-time data analytics and machine learning.
Traditionally, all of an application’s data was stored in centralized or office-centric, relational databases. But this doesn’t scale for the sensors-driven, time-series data explosion on which real-time operations and intelligence depend.
In order to build true data-driven solutions, the engineering and maintenance burdens have been irreversibly complicated. We’ve gone from a handful of subsystems to dozens of subsystems that require the expertise of more costly big data engineering teams.
Understanding Use Cases
Simply envisioning and understanding IoE, ML, and AI-related use cases is another major challenge holding companies back.
About 42% of respondents to Gartner’s AI/ML development survey named use case identification as their second biggest challenge (after a lack of skills). We see this, time and again.
Other key challenges include scalability, along with inflexible, legacy systems that can’t deal with time series data or large volumes of high-velocity data from disparate sources.
One Backbone to Rule All
Given this raft of challenges, more and more companies are experimenting with using a “single backbone” data automation foundation for building IoE applications. This requires an open, flexible platform for building real-time, scalable, data-automation, and AI solutions that can handle scalable data ingestion, normalization, and enrichment along with real-time business logic, data storage, and decision analytics.
A data backbone approach allows developers to focus on building unique business and user value into their solution, rather than trying to anticipate all the uses of data to fit within older, more rigid DBMS infrastructure.
Enterprises need systems that will allow them to ingest sensor data at varying volumes and velocities, with any type or combination of inputs and outputs. And they should have the ability to deploy such capabilities on-premises, in the cloud, on the Edge or a hybrid version.
This solves or avoids a multitude of problems, from siloed data and limited scalability to the challenges of building multiple applications without reinventing the data-foundation each time. And it will provide a faster path to value realization.







