










Satya Nadella, the CEO of Microsoft, once said, “Every company is now a software company.” Take the online food ordering business, for example. Digital ordering and delivery have grown 300% faster than dine-in traffic since 2014. During Covid, online ordering grew 3,868% between February and April in large suburbs in the United States.

As a system architect, I feel that trend every day. More businesses and users are on the internet now, and all of this activity eventually becomes requests or workloads on a server, an application, and a system. Scalability becomes a challenge. When your server does not have enough resources to handle the increasing load on your application, what do you usually do? Buy more RAM, add CPU cores, and add disks? These solutions are known as vertical scale or scale-up.
But you can only add so many resources. What if you have maxed out your current resources, but they still cannot handle the workload? One option is to add more machines and scale-out your system further.
But I want to tell you about a better option: a hybrid approach. You can use streaming, pipelining, and parallelization to design your application to maximize the utilization of your resources on a single node. Then, you can add additional hardware resources to scale your system out/up.
See also: Using Change Data Capture to Scale Streaming Projects
Increasing throughput without additional hardware resources
How to measure system performance
To describe the performance of a system, we need to take both the input and output into consideration.
Performance = Workload / Resource Consumption
We have two major scenarios: one focuses on operations per second (OPS) and the other on throughput. These two are the most important ways to measure system performance. The OPS type can be equivalent to the throughput type with certain constraints or optimization. Let’s talk about the throughput type, which is more fundamental in this article.
For example, the main goal of your system might be higher QPS, but throughput can be equivalent to QPS. This is true for a lot of Online Transactional Processing (OLTP) systems and API-based services, where the average data load for each transaction is about the same. For Online Analytical Processing (OLAP) or other systems that are designed to handle huge data loads, higher throughput will be the focus. We also see the trend of more and more systems that need a mixed load, like a Hybrid Transactional and Analytical Processing (HTAP) database that will support both high QPS requests and high throughput. Using throughput to measure the workload can also be applied to those systems.
Fully consuming system resources with better scheduling
Have you ever played the cooking-themed video game “Overcooked”? The goal is to serve your customers. You take their order, cook the food, and serve it. During cooking, you may need to chop ingredients, combine them, and cook them in a pot. Let’s look at this process more closely and see how things can quickly back up.
Let’s say chopping takes two seconds, and cooking takes four seconds. If we take one order at a time, each order will take six seconds. If three customers come in at the same time, the first customer will wait for six seconds, the second customer for 12 seconds, and the third 18 seconds. The longer your customers wait, the more likely they will lose patience and leave. If you don’t have enough paying customers, you’ll go out of business.
So, how to speed things up and win the game? We want to process multiple orders at the same time: while Order 1 is on the cooktop, we’re chopping the ingredients for Order 2. When we put Order 2 on the cooktop, we start chopping Order 3. With this new scheduling strategy, Customer 1 still waits for six seconds, but Customers 2 and 3 each wait four seconds less: 8 and 14 seconds, respectively.

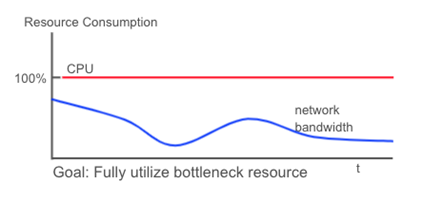
Since the cooktop stage takes the longest time, it determines how long it takes to complete each order. This is our “bottleneck resource.” We can see from the above chart that for Order 2 and Order 3, after chopping, both orders have to wait for two seconds before they can move on to the cooking stage. We’ll be able to process the maximum number of orders if we keep the cooktop in constant use—no downtime.
The scheduling for the computer is similar. The codes to be executed are orders which represent the throughput, and system resources are like the chopping board and cooktops. In a perfect world, all the resources are fully utilized during the running time, as shown in the Ideal App chart below.

We can achieve that if we upgrade the cooktop, and it will only take two seconds, the same as the chopping time. In this case, there is no idle time for the chopping service.

However, it’s rare to achieve this kind of efficiency. A more realistic goal would be that, while the application is running the bottleneck resource (the CPU) is 100% used. If the other resources are not used 100%, that’s OK.
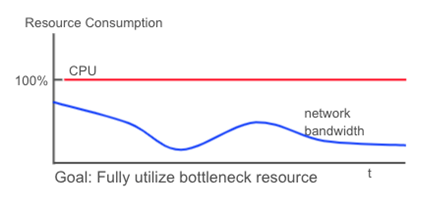
In contrast, poorly designed applications do not use the bottleneck resource at 100% all the time. In fact, they may never use the bottleneck resource at 100%.
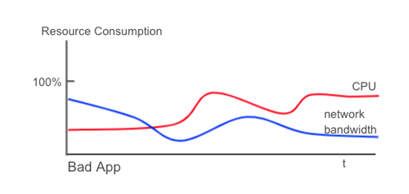
To summarize, we evaluate the performance of a system by the throughput it can achieve with fixed system resources. A good application design enables higher throughput with fixed system resources by fully using the bottleneck resource. Next, we will take a look at how streaming, pipelining, and parallelization can help to achieve the resource utilization goal.
Using streaming, pipelining, and parallelization to achieve maximum resource utilization
Breaking down a large task with streaming
The word “streaming” can mean different things in different contexts. For example, “event streaming” means a set of events coming one after another like a stream. In the context of this article, streaming means breaking a big task into smaller chunks and processing them in sequence. For example, to download a file from the web browser, we can break the file into smaller data blocks, download one data block, write it to our local disk system, and repeat the process until the whole file is downloaded.
Streaming has several benefits. Before streaming, one large task could use all resources during a period and block other smaller tasks from using resources. It is like waiting in line at the DMV. Even though I just needed to renew my driver’s license with my pre-filled form, which took less than 5 minutes, I had to wait 20 minutes while the customer ahead of me finished his application.
Streaming can reduce peak resource utilization—whether you’re downloading a file or waiting in line at the DMV. What’s more, streaming reduces task failure cost. For example, if your download fails in the middle, it doesn’t have to start over. It just picks up from where it failed and continues with the remaining data blocks.
Therefore, breaking down one big task into smaller chunks enables scheduling and opens the door for multiple ways of optimizing resource utilization. It is fundamental for our next step: pipelining.
Folding the processing time with pipelining; idle = waste
Assume that an application is running without a streaming design, and it takes two steps. Step 1 is encoding. It consumes CPU resources and takes 100s. Step 2 is writing to disk. It consumes I/O bandwidth and takes 70s. Overall, it takes 100s + 70s = 170s to run this application.
With streaming, we break this one task into ten atomic slices. Each slice follows the same two steps but takes only 1/10 of the time. So it will take (10s + 7s) * 10 = 170s. But this approach reduces memory usage since we are not saving a huge chunk of data in it all at the same time and has the benefit we stated in the previous section: reduced failure cost. (We ignore the transaction breakdown overhead here; we will discuss this in the implementation section.)

If we add pipelining to this picture, right after Slice 1 finishes using CPU, Slice 2 can start to use CPU without having to wait for Slice 1 to finish I/O consumption. Right after Slice 2 finishes using CPU, Slice 3 can start to use CPU. And the story continues. Now the overall processing time is 10s * 10 + 7s = 107s. With pipelining, we just reduced our task time by 63s—more than one-third of the original time!
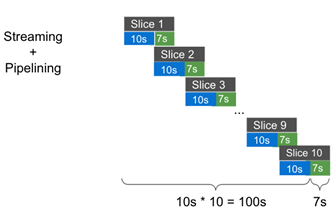
The benefit of using pipelining is obvious. With timefold, the overall processing time is significantly reduced. That means the application can process more and produce higher throughput within the same time period.
The expected processing time should be reduced to about the same amount as the most time-consuming step in the original process. In the above example, without streaming and pipelining, the encoding step takes 100s, and our new flow, which uses those techniques, takes 107s. They are about the same level.
Also, we are maximizing the utilization of the bottleneck resource—CPU. The CPU does not have to wait for the I/O step to be finished before it can start to process the next slice. Idle time is wasted time. So we are one step closer to our performance goal:
The two diagrams below show how our resource consumption has changed. We’ve gone from “CPU and I/O alternates” to “CPU and I/O consumption overlapping.”
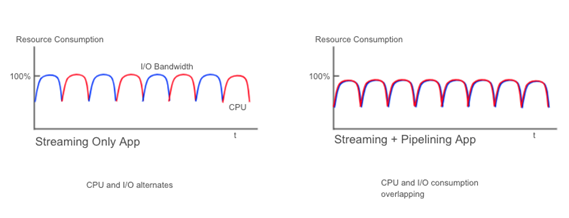
Pipelining applies to continuously running applications as well. Using timefold can flatten the consumption curve for a single resource. From here, we can apply the parallelization strategy, which will be introduced in the next section.
Maximizing resource consumption with parallelization
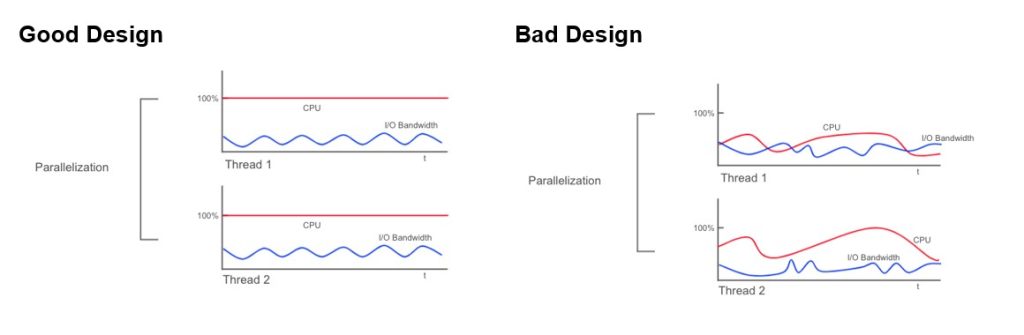
With streaming and pipelining, the tasks have been broken down into small enough actions, and the consumption curve for one resource is close to flat, although it does not reach 100%. We can apply parallelization to fully utilize the bottleneck resource and achieve high performance, for example, 100% CPU occupation.
Going back to our cooking example, streaming is like breaking down cooking one dish to cooking the meat, cooking the noodles, and cooking the mushrooms. Pipelining is like breaking down the cooking stage to chopping the meat and cooking the meat, and while the meat is cooking, chopping the mushrooms. And what is parallelization? You are right: it means we will have different players working together, and we can cook multiple orders at the same time. With a good scheduling strategy, different players can work together to have the bottleneck resource—the cooktop—running non-stop.
In daily life, our computers use parallelization all the time. For example, loading a web page uses parallelization. Right after you enter the address, your browser will load the HTML page. At the same time, your browser will also start multiple threads to load all the pictures on the HTML page.
Parallelization will be more effective if we apply it to threads that already have a flat resource consumption curve. It can be applied to a simple process that contains only one step and is smoothly consuming the resource by default or to complex processes that have gone through streaming and pipelining. (The next article in this series discusses how to implement different parallelization strategies.)
We have talked a lot about what we should do. But it is easy to ignore what we should NOT do. We shouldn’t apply parallelization to processes that do not smoothly consume resources or to processes where we can’t control which resources are being consumed. In those cases, we are giving the OS the power to decide resource allocation. And controlling the performance for that? Wish us good luck.
Now you understand the basics of streaming, pipelining, and parallelization. Join us for Part 2 of this series, where we will discuss how to implement these methods. We’ll also consider strategies on which combination of methods you can use to meet your specific needs.







