











Open source message queue platforms RabbitMQ and Apache Kafka both ensure that applications and services producing messages can reach their intended consumer. These powerful platforms help organizations build new streaming applications, bolster app reliability, integrate microservices, and more. But while RabbitMQ and Kafka have similarities in their functionality, there are some important differences that dictate which is most advantageous for your use case. Let’s take a look.
Understanding asynchronous messaging patterns
Before jumping into RabbitMQ or Kafka, it’s important to first understand the types of asynchronous messaging patterns. Each platform passes messages from producer to consumer apps asynchronously—and those apps don’t need to both be active in real-time because messages are stored if the consumer is unavailable.
The two primary asynchronous messaging patterns are:
Message Queues
Here, producing apps send messages to a queue. When ready, consuming apps connect to the queue and retrieve and remove messages. Importantly, a single message is consumed by a single consumer (even if multiple consumers exist).
Publish/Subscribe
In this messaging pattern, producers publish messages that multiple consumers can consume. A producer publishes to a channel that all consumers interested in its messages can subscribe to. The typical use case involves using a message to prompt actions from multiple apps. Consuming apps receive messages in the order the messaging system receives them (unlike with message queue patterns).
See also: 7 Surprises Running Kafka in Production (and How to Prepare for Them)
RabbitMQ
First released in 2007, RabbitMQ is a distributed message broker available as open source. RabbitMQ’s flexibility supports multiple messaging protocols (AMQP, MQTT, STOMP, etc.), enables complex routing, and deploys as a highly scalable and available distributed solution. The platform also features a strong community with some major enterprise users. Clients, plug-ins, guides, and support are readily available.
RabbitMQ’s architecture is built around producers, consumers, exchanges, and queues. A producer sends messages to an exchange. The exchange routes those messages to queues (or further exchanges). Consumers read messages from queues (often to a set message limit). In RabbitMQ, queues are sequential data structures. Messages from producers add on to the end of a queue, while consumers receive data from the head of the queue, maintaining a “first in, first out” flow.
RabbitMQ supports complex routing use cases by offering the flexibility of four types of message exchanges (how messages are routed), including:
- Direct exchanges. Messages carry routing keys (a string of period-delineated words relevant to the message) used for routing to the correct queue.
- Fanout exchanges. Broadcasts messages to all available queues.
- Topic exchanges. Routes messages to one or more queues based on partial or complete routing key matches.
- Header exchanges. Message headers (able to hold more attributes than routing keys) control message routing.
Apache Kafka
Originally developed by LinkedIn, Apache Kafka is a distributed event-streaming platform available as a powerful open source solution. It is most commonly utilized to create streaming apps and real-time data pipelines. Also backed by a strong community, used by more than 80% of the Fortune 100, and regularly in the top five of activity among Apache projects, Kafka is the de facto message streaming and queuing solution for supporting persistent high-scale event-driven apps. Kafka’s advantages include tremendous horizontal scalability, the flexibility to interface with a breadth of systems via intuitive APIs, high availability, and performance able to deliver millions of messages per second.
Kafka’s architecture consists of producers, consumers, clusters, brokers, topics, and partitions. Kafka producers pass records to clusters. Clusters store records to send to consumers. Server nodes within a cluster act as brokers that store data until a consumer reads it.
Kafka uses topics rather than queues. Much like a folder in a filesystem (Kafka’s own analogy), topics are streams of data containing records. Producers send messages to a specific topic. Topics are divided into partitions, unalterable record sequences to which producers add new messages. Records within a partition each have an “offset,” a sequential ID describing its place in the sequence. Consumers (or consumer groups) receive messages by subscribing to one or more topics and receiving any new messages or events.
Users can flexibly control precise Kafka message delivery behavior; for example, by placing partitions on multiple brokers to enable multiple parallel consumers to read from a topic (also allowing the topic to contain more data than one machine can facilitate). Similarly, users can direct producers to create logical message streams that help guarantee message delivery to consumers in the correct order.
RabbitMQ vs. Apache Kafka: Messaging patterns, security, and operations management
As established above, RabbitMQ relies on message queues, while Kafka utilizes a publish/subscribe messaging pattern. RabbitMQ and Kafka are each able to push and pull messages. Each can also buffer messages until consumers are ready and deliver multiple messages at a time: RabbitMQ does so with “pre-fetching” and Kafka by processing messages in a certain “batch size.” While messages in RabbitMQ are ephemeral, Kafka allows consumers to reread messages stored in partitions, enabling use cases like event sourcing, and log aggregation.
RabbitMQ and Kafka each include built-in security and operations management tools and have rich ecosystems of third-party solutions. Both RabbitMQ and Kafka offer support for TLS encryption, SASL authentication, RBACs, and a security CLI. RabbitMQ also includes in-browser API tooling for user and queue monitoring and security management. Additional open source and commercial tooling is available to enable monitoring of specific metrics across the architectures of each solution.
Ideal use cases for RabbitMQ and Apache Kafka
RabbitMQ and Kafka are both suited to the same general use cases, such as connecting producer and consumer apps within microservices architectures, serving as a message buffer, acting as temporary message storage until consumer apps are ready, or smoothing out message spikes. Each platform handles messages at high scale.
Here are the use cases where RabbitMQ and Kafka demonstrate distinct advantages:
Use cases favoring RabbitMQ
These best use cases for RabbitMQ take advantage of the platform’s flexibility:
- Complex routing. When routing messages to multiple consuming apps (common with microservices), RabbitMQ’s consistent hash exchange is ideal for balancing load processing across distributed services. Other exchanges can enable A/B testing, routing different segments of events to certain services.
- Legacy applications. RabbitMQ can connect consumer apps and legacy apps using existing or self-developed plug-ins. One popular use case includes communicating with JMS apps by using a plug-in and JMS client library.
Use cases favoring Apache Kafka
Kafka shines when it comes to its stream processing and high throughput:
- High-throughput activity tracking. Applications involving high-volume, high-throughput activity tracking are well served by Kafka. Examples include tracking website activity, ingesting IoT sensor data, and tracking shipments.
- Stream processing. With Kafka, users can introduce application logic to handle streams of events. Users can leverage this feature to count all of a certain event type, find average values of certain metrics during an event, and more. As a specific use case example, an application that monitors temperature within a facility could track readings and sound the alarm if the average temp represents a danger.
- Event sourcing. Kafka can store app state changes as an event sequence. For example, if the account balance in a financial app is corrupted, a transaction history stored with Kafka can make it possible to restore that balance.
- Log aggregation. Much like event sourcing, Kafka can also collect and centralize log files to support an app as a single source of truth.
Benchmark Results
Kafka (being a distributed log-based pub-sub messaging system) is just about the most scalable possible solution for streaming data, being designed for sequential data access, replication of data, and event reprocessing (facilitated by the log abstraction, messages are never discarded), supporting highly concurrent consumers (for load sharing) and consumer groups (for broadcasting)—facilitated by partitions. The differences in architecture between Apache Kafka and other messaging technologies (e.g., RabbitMQ and Apache Pulsar) lead to some stark benchmark results. Kafka throughput was the best (600MB/s), followed by Pulsar (300MB/s), and then RabbitMQ (100MB/s, or 40MB/s Mirrored), running on identical hardware.
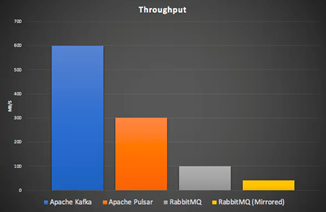
Kafka also delivers the best latencies at higher loads. At lower loads, RabbitMQ had the lowest latency, followed by Kafka, with Pulsar the highest. The OpenMessaging Benchmark Framework was used for this benchmark testing (which required a few fixes to work fairly across all three technologies).
Choose the right platform for your job
By understanding the particular strengths of RabbitMQ and Apache Kafka, you can ensure that you’re using the right message queue platform for your use case.







