











Generative AI (GenAI) has propelled large language models (LLMs) into the mainstream. However, persistent hallucinations, where AI tools give false information as fact, pose safety challenges for companies. AI hallucinations have become such a phenomenon that both the Cambridge Dictionary and Dictionary.com named ‘Hallucinate’ their 2023 “Word of the Year.” The choice makes sense. Despite their popularity, LLMs, such as ChatGPT, exhibit a staggering 41% hallucination rate. The problem is these tools can’t “think” so much as they can leverage patterns in their training data to predict what word comes next. This renders them more of a Mad Libs oracle than an intelligent AI overseer endowed with superhuman truth.
“I don’t think that there’s any model today that doesn’t suffer from some hallucination,” said Anthropic co-founder and president Daniela Amodei to the Associated Press. Compound this with questions from policymakers and regulatory bodies on privacy and legal implications, and one can see why many companies struggle with how best to move forward with their GenAI plans, even as they race to capitalize on the opportunity.
There is good news, however. Enterprises determined to crack the problem have found a solution in their own data. A key to cracking the hallucination problem—or as my friend and leading data scientist Jeff Jonas likes to call it, the “AI psychosis problem”—is retrieval augmented generation (RAG): a technique that injects an organization’s latest specific data into the prompt, and functions as guard rails. The most commonly known form of RAG today uses vector embeddings. While these play their part, they fail to go far enough. They also do little to solve for explainability. Our customers have been discovering a more effective and complete solution: adding knowledge graphs to vector-based RAG. A Knowledge graph is an insight layer of interconnected factual data enriched with semantics so you can reason with the underlying data and use it confidently for complex decision-making.
To understand why knowledge graphs are such a great solution for RAG, consider how you understand an apple. An apple has color, flavor, variety, and other properties. You can build a map of an apple’s characteristics as below:
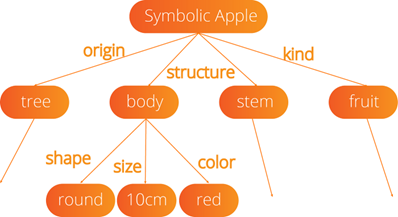
Image Source: Towards Data Science, Symbolic vs. Subsymbolic AI Paradigms for AI Explainability
This is the apple in graph form. This style of representation is powerful because it’s precise, auditable, and repeatable. It can also serve as a basis for reasoning and is understandable to normal humans, including CIOs, analysts, regulators, auditors, and everyone else.
Yet a language model (or a vector index) understands the same apple numerically in ways that are only decipherable by a machine and are not guaranteed to correspond with the explicit map of human understanding:
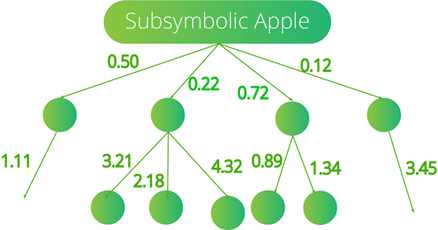
This map is an implicit representation of meaning derived from language statistics, such as word frequency and proximity. Feed a model enough text, and the statistical approximation gets closer to the human representation of concepts. When we trust an LLM with a response, we’re literally gambling that the result will be correct. The correctness of the answer depends entirely on the statistical accuracy of the model: a model that cannot be introspected.
See also: How Knowledge Graphs Make LLMs Accurate, Transparent, and Explainable
Unfortunately for the businesses seeking to depend on them, the more complex a decision and the more specific a business domain, the more likely an LLM is to skew from its tracks. Knowledge graphs play a crucial role in grounding results, bridging and confining machine action to human understanding.
Here are three key considerations for ensuring a path for trust in your AI outcomes.
Use Knowledge Graphs for more accurate Generative AI outcomes
Adding knowledge graphs alongside language models and vector embeddings can provide significantly improved accuracy and is a natural next step for higher-stakes applications where the cost of a hallucination is high. Using knowledge graphs as guard rails provides a secondary benefit insofar as they are understandable by humans and can also help with explainability.
One Fortune 200 energy multinational built an Enterprise Knowledge Hub using ChatGPT and a Neo4j-powered knowledge graph on Microsoft Azure, integrating data from 250+ subdivisions for better predictive analytics, ML, and process automation. This GenAI cognitive services application has now been implemented across various departments, achieving a $25M value in the initial three months of the proof of concept.
Start specific, stay grounded
Foundation models such as the ones from OpenAI, Anthropic, and Google are trained on massive amounts of text spanning every domain. They are built to “know” everything. But just as you wouldn’t ask your general practitioner to do hip surgery, smaller and more specific models trained on your data (that are pertinent to the task) provide a more targeted solution for handling specific needs. As a side benefit, this can often be cheaper, as inference costs tend to be lower with smaller models. Keeping the data in-house with smaller models also has security and privacy benefits.
Basecamp Research trains its language models with a groundbreaking knowledge graph that pairs the company’s proprietary protein and genome sequences with environmental and chemical data from nature from across five continents to reveal an intricate biological network. With the world’s largest knowledge graph of the Earth’s natural biodiversity, Basecamp fills a knowledge gap in Life Sciences, delivering more effective data products and biotechnological applications. A chemical manufacturer optimized an enzyme within one month at a fraction of the cost compared to their previous two-year, $16 billion effort, thanks to Basecamp’s approach.
Proprietary vs. Open Source Language Models
The answer to whether one should use proprietary or open source models, and small specialized models or large language models, may simply be yes. The richer your application and the higher the stakes, the more likely it is that you can benefit from bringing together multiple models, each for their specific purpose. Nothing beats the ability of large language to render answers in coherent human language. At the same time, you can probably get good (and cheaper) results to business-specific questions from small specialized in-house models.
Our experience with customers is that different models are better at different tasks and that the best way to optimize for each task is focused experimentation since no single model will solve for all needs. It goes without saying that one should use RAG in abundance alongside your models for all the reasons described above.
A final word about hallucinations and generative AI
Hallucinations may be a feature when writing a bedtime story, but they are a serious risk for any business activity. Enterprises innovating with GenAI need to be able to trust the results and explain them. The latest evolution in the rapidly-shifting GenAI landscape is to use LLMs and vectors along with knowledge graphs. It’s a combination that will become essential in bridging the world of humans and machines.







