











The potential of IoT has never been greater. With investments in IoT-enabled devices expected to double by 2021 and opportunities surging in the data and analytics segments, the main task is to overcome the challenges and tame the costs surrounding IoT data projects.
Organizations can optimize IoT data, quickly and cost-effectively deriving its business value by developing expertise in ETL (extract, transfer, load) technologies, such as stream processing and data lakes.
See also: 4 Principles to Enabling a Pristine Data Lake
At many organizations, though, this may lead to IT bottlenecks, long project delays, and data science being deferred. Result: IoT projects – in which predictive analytics data is meant to play a critical role in improving operational efficiency and spurring innovation – still haven’t crossed the proof-of-concept threshold and definitely cannot demonstrate ROI.
Understand the ETL Challenges that IoT Faces
The following diagram will help you understand the problem better:
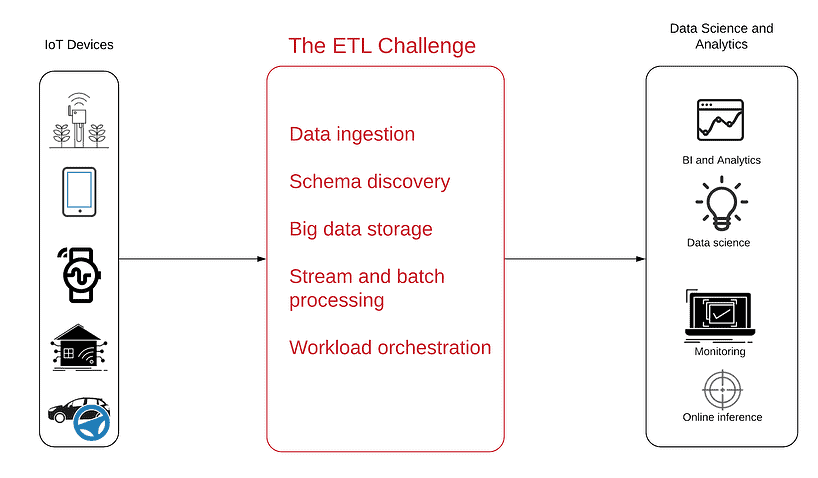
The data source is on the left – innumerable sensor-filled devices, from simple antennas to complicated autonomous vehicles that generate IoT data and send them as an uninterrupted stream of semi-structured data over the web.
On the right are the goals the consumption of said data should achieve, with the resulting analytic products at the project’s conclusion, including:
- Business intelligence to gain visibility into product usage trends and patterns
- Operational monitoring to see outages and inactive devices in real-time
- Anomaly detection to get proactive alerts on peaks or precipitous drops in the data
- Embedded analytics to enable customers to see and understand their own usage data
- Data science to enjoy the benefits of advanced analytics and machine learning in predictive maintenance, route optimization, or AI development
To achieve these goals, you need to first transform data from its raw streaming mode into analytics-ready tables that can be queried with SQL and other analytics tools.
The ETL process is often the most difficult-to-understand segment of any analytics project because IoT data contains a unique set of qualities that are not always in sync with the usual relational databases, ETL, and BI tools. For example:
- IoT data is streaming data, continuously generated in small files that accumulate to become massive, sprawling datasets. These are very distinct from traditional tabular data and require more complex ETL to perform joins, aggregations, and data enrichment.
- IoT data has to be stored now, analyzed later. Unlike typical data sets, the sheer volume of data created by IoT devices means that it has to have a place to sit before it can be analyzed – a cloud or on-premise data lake.
- IoT data presents unordered events due to multiple devices that may move in and out of Internet connectivity areas. This means logs may reach servers at various times and not always in the “correct” order.
- IoT data often requires low-latency access. Operationally, you may have to identify anomalies or specific devices in real or near-real time, so you can’t afford the latencies caused by batch processing.
Should You Use Open-Source Frameworks to Create a Data Lake?
To build an enterprise data platform for data analytics, many organizations use this common approach: create a data lake using open-source stream processing frameworks as building blocks plus time-series databases like Apache Spark/Hadoop, Apache Flink, InfluxDB, and others.
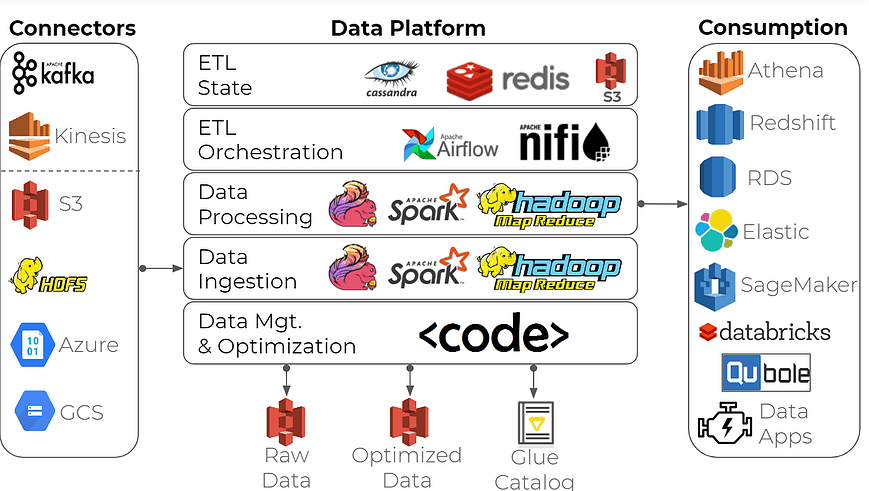
Can this toolset do the job? Sure, but doing it correctly can be overwhelming for all but the most data-experienced companies. Building such a data platform demands the specialized skills of big data engineers and strong attention to the data infrastructure – not usually a strong suit in manufacturing and consumer electronics, industries that work closely with IoT data. Expect late deliveries, steep costs, and a ton of squandered engineering hours.
If your organization wants high performance plus a full range of functionalities and use cases – operational reporting, ad-hoc analytics, and data preparation for machine learning – then adopt a suitable solution. An example would be to use a data lake ETL platform purpose-built to convert streams into analytics-ready datasets.
The solution is not as rigid and complex as Spark/Hadoop data platforms. It is built with a self-service user interface and SQL, not the intense coding in Java/Scala. For analysts, data scientists, product managers, and data providers in DevOps and data engineering, it can be a truly user-friendly tool that:
- Provides self-service for data consumers without needing to rely on IT and data engineering
- Optimizes ETL flows and big data storage to reduce infrastructure costs
- Allows organizations, thanks to fully managed service, to focus on features rather than infrastructure
- Removes the need to maintain multiple systems for real-time data, ad hoc analytics and reporting
- Ensures that the data never leaves the customer’s AWS account for total security
You can benefit from IoT data – it just takes the right tools to make it useful.







