











The explosion in the number of devices and use cases for the edge is forcing businesses to rethink their data management strategies. Traditional approaches of bringing everything back to a central location, storing it, and then analyzing it at a later time are not practical. And most importantly, they deny businesses the ability to act on the data in real time or near real time – missing countless valuable opportunities.
RTInsights recently sat down with Bill Schmarzo, the Dean of Big Data, to talk about the challenges of managing streaming data and how businesses can monetize data by having the right data management strategy and platforms in place.
Here is a summary of our conversation.
RTInsights: Why does data management matter? And why is it more important today than it has been in the past?
Schmarzo: I believe that data management is the most important business discipline that we have today. And it’s not just a technology practice but a business discipline. The reason why I say that is because we have this unbelievable potential for AI. There is an opportunity to create products, processes, policies, and procedures using AI that can continuously learn and adapt. It’s a powerful, game-changing capability. For example, we all know about the potential of autonomous vehicles – but everyday examples are everywhere. I was just talking to an agricultural company about how they’re using precision spraying to treat just the crops that need to have herbicides put on them. The cost savings, operational efficiencies, and environment impact are astounding.
The problem with this AI vision is the data. If you don’t have good-quality data, then your AI models are not going to produce good-quality outcomes. For those of us who have been in this industry a long time, we know this is garbage in, garbage out, or GIGO.
![Experience Real-Time Business Insights with Streaming Data at the Edge [Learn More]](https://no-cache.hubspot.com/cta/default/8019034/992e5b85-1977-4a09-9de4-7c51e910ed32.png)
But it’s really only been in the last few years that the high priesthood of AI practitioners have realized that no matter how elegant and crafty your AI algorithms are, you can’t overcome inaccurate data. You can’t overcome incomplete data. You can’t overcome biased data.
To get the full potential out of AI to drive business innovation, you need a solid data management strategy as the foundation for your AI strategy. You need to have complete data, high-quality data, and accurate data with low latency and low granularity. These are all things that make data an economic asset.
Related: New Dell Data Virtualization Solution Enables Multi-Cloud Data Queries and Analytics
That’s why I think data management is a discussion not just for the Chief Information Officer and the Chief Data Officer. I think it’s a conversation that needs to include the CEO and the senior business executives. Data Management is a business initiative, not just a technology project. The goal of Data Management is to improve the quality, completeness, accuracy, enrichment, and governance of our data to derive and drive all these different benefits we can get from AI.
RTInsights: What are some of the main data management challenges when dealing with streaming data from or at the edge?
Schmarzo: Everything that we’ve learned from the past about data analytics is no longer relevant. That is, we’ve come from yesterday’s world of historical analytics based upon aggregated, structured data that we process and analyze in batch mode.
We get weekly reports. And we get dashboards on historical data. But now we’re dealing with data that’s coming in real time. Some of it can be structured, but most of it is unstructured. It’s sensor data, vibration data, video surveillance data, log files, photos, and more. So, we have to fundamentally change or morph our data analytics approach.
Managing data at the edge is actually quite easy. What’s hard is how you monetize it. How do you get value from it? How do you take the data that’s streaming into the organization and analyze it, inference on it, and act on it as it’s coming in? How do you use this data to help your customer or stakeholder?
Think about a retailer who’s trying to do in-store queue management, trying to identify situations where customers are abandoning their carts because the lines are too long, where you’re trying to watch for theft, for shrinkage. It isn’t the management of the data that’s as big a challenge. It is the ability to take that data and make better operational decisions at the point of customer interaction or operational execution. That’s the challenge.
And so, we need a different mental frame as well as a different data and analytics architecture that is conducive to the fact that this data that’s coming in, in real time, has value as it’s coming in. Historically, in batch worlds, we didn’t care about real-time data. The data came in. And if we got it updated into our data warehouse, data lake, data whatever you want to call, the next day or two days later, and we were okay with it.
But now that doesn’t do me any good. For example, if I’m trying to do location-based marketing, knowing a customer walked by my Starbucks two days ago does not do me any good. I want to know if they’re there right now.
And so, there are all kinds of technology aspects that need to be addressed. There is architecture and the ability to process and analyze data. But it’s also the use of that data and its storage and governance that’s challenging organizations. Many have never had to deal with low-latency decisions, data that is either real time or near real time, or decisions that are being made within seconds or minutes, or hours of the data actually coming into the system.
RTInsights: Why are traditional data management techniques and solutions not well-suited for the edge?
Schmarzo: We come from a traditional world where we’re dealing with structured data in batch, and now we’re being asked to deal with unstructured data in real time.
There are all kinds of architecture challenges. Where do you store the data? Where do you put processing? Where do I train my models versus where do I do model inferencing? There are processes that we’re just traditionally not very good at.
And in fact, the skill sets that work really well for traditional historical data management actually put you at a liability. In some cases, you have to unlearn things. Sometimes we have to basically throw away things that we’ve done in the past and embrace a whole different framework.
I like to tell my students in class if they want to change the game, change the frame. And that’s what we’re asking our clients to do is to change the frame and how they think about data and deriving value from that data as its flowing into the operations.
I got this great quote from a customer once. We were talking about all this volume of data growing at the edge. And their business executive team was gnashing their teeth. They were wondering, well, how are we going to manage all this data at the edge?
Then one person in the room, one of the executives, said, “Wait, it’s not how are we going to manage all this data at the edge. The real question is how are we going to monetize all this data at the edge?” I knew who my sponsor was immediately because now I had somebody who was thinking about this data from a value creation perspective, not just from a storage or management perspective.
Capturing all this data at the edge is one thing. It’s a cost to capture it. It opens up all kinds of potential liabilities if I don’t manage them properly. But if I’m not going to actually derive value from that data, if I’m not going to actually try to monetize that data as it’s coming in, then why bother to capture it and manage it – and pay to store it?
RTInsights: What features are needed in a solution or solutions for managing such data?
Schmarzo: The data architecture is incredibly important because you are capturing lots of data at the edge. And you’re not going to necessarily ship all that back to a centralized location.
You may decide that there are only certain data elements that you want to capture. For example, you might only capture data elements that change. If I have a sensor that’s capturing temperature and is taking a reading ten times every second, and the temperature is 98, 98, 98, 98, am I going to store all that data? In some cases, I only care about when the data changes or when it changes beyond a certain threshold.
So, the architecture has to have more intelligence in the data capture process to make sure that I’m capturing data that is most relevant. Otherwise, I could quickly overwhelm the system by capturing everything. And the architecture must stretch from edge to core to multi-cloud. It’s got to be able to find and access the data wherever it may be located across that entire landscape.
Another factor is the ability to analyze the data in real-time, to do inferencing on the data as it comes in, and then ship back what data is most important to the centralized location so I can continuously train my machine learning models. I’m probably training my models in an on-prem or cloud environment where I have massive amounts of data and processing power to refine and update the ML models as needed.
But I’m not actually training the model at the edge. I’m actually doing inferencing. I’m actually only executing the models at the edge, looking for anomalies, looking for concerning situations or engagement opportunities. I’m making recommendations on what actions to take. So, the data architecture becomes much more complex.
You also need to clearly define the use case and the KPIs and metrics against which you will measure that use case’s progress and success. If you don’t thoroughly understand the use case, you could spend a lot of time, money, and resources building out your data architecture capabilities for the wrong problem. You could spend a lot of time capturing data that’s not important.
Finally, your instrumentation strategy shouldn’t start until you understand your use case and what data you’re going to need. And then, I can figure out what sensors I’m going to need, how often we’re going to need to capture the readings, and how I need to send the relevant data back to the central repository. So, the use case becomes everything.
RTInsights: Where does the Dell Streaming Data Platform come in?
Schmarzo: The Streaming Data Platform has the ability to capture data in real time, both structured and unstructured, from almost any kind of device. It ingests the data, stores it, does inferencing on it, analyzes it, and then acts on it. It’s got everything you need bundled together to manage, analyze, and act on the data at the edge.
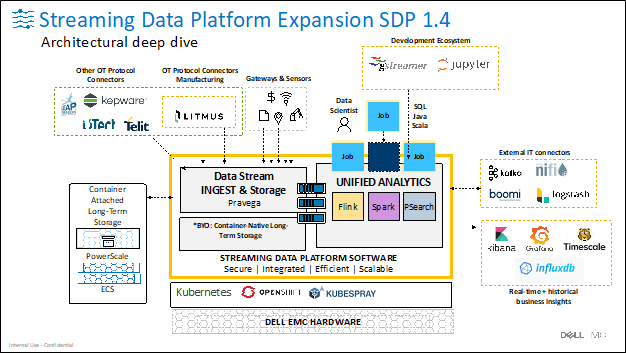
Think about a manufacturing facility that has an army of PLCs [programmable logic controllers] that have been developed by different manufacturers who all have different data formats and use different communication protocols.
You’ve got to be able to ingest all that data across all those different protocols. And then once you’ve got it in there, you have to be able to analyze the data on it as it’s coming in. That requires technologies like Pravega, Kafka, Spark, and Flink. And then you’ve got to be able to present the results back to the user or the operational system in real time or near real time so that it can be acted upon.
If you’re doing predictive maintenance, you’re flagging a particular device that’s starting to wobble. Or, if you’re monitoring employee safety and you notice an employee walking into an area where they’re not qualified to be, you can alert folks so that that insight can be acted upon quickly. The Streaming Data Platform provides the ability to ingest data from any sort of device, analyze that data, and then act on any insights from the data in time for that action to make a difference.
And the one thing that Streaming Data Platform does that I have never seen before is it treats streaming data as a native data element.
So, you’ve got unstructured data, and you’ve got structured data – but SDP treats all data, regardless of type, as a continuous stream of data. It ingests all data as a byte stream, essentially a log of ingested data over time. This timeline of data allows applications or developers who are interacting with that data to jump to any point on that timeline (just like watching a show you recorded last week on a DVR), and then the data plays back to that application as if it’s happening now, but with the timestamps of the original events. What this means is that applications and developers can interact with historical and real-time data in the exact same way. With this, people can compare real-time data alongside data from the past – which can create use cases with much deeper insights.
For example, in a healthcare application, you might have babies in a NIC unit (neonatal intensive care unit) where they are monitored at all times. You want to be able to detect changes for any one baby but also see patterns across multiple children over time (last hour, last week) of children born, say during early Covid days, to see if there were any changes in how they were progressing early in their development.
RTInsights: What benefits do organizations get when they use the Dell SDP?
Schmarzo: Let’s talk about use cases. I think that’s where it gets interesting.
We have customers who are using the SDP to do predictive maintenance, analyzing across tens of thousands of different components, and looking for any anomalies in performance so that we can flag and act upon those anomalies before our product, and therefore, the bottom line is heavily affected.
Not only does that impact predictive maintenance, but it also impacts load balancing. If we have a part that’s starting to struggle, we can shift the load over to another part while we get somebody in there to replace that.
There are retail customers who are using it for things like queue management to manage what’s going on – opening registers when computers sense too many people in each line and to see where customers are spending their time. When you look at customers like that, you could also help them in other ways. Are customers getting hung up on the layout of the store? Is the in-store merchandising set up properly? Are customers struggling to find what they are looking for? Do we have out-of-stock situations? The use cases are only limited by your creativity!
We see a lot of use cases from security and safety perspectives – people being in spots they’re not supposed to be in and flagging and acting upon that sooner. It might be a nefarious character doing something suspicious or just an employee who has not been formally trained on the use of a certain piece of equipment.
In telco, we see use cases around load balancing, predictive maintenance, and reducing unplanned operational downtimes. If you’ve got a telco tower and it goes down, well, not only do you have a maintenance issue, but you’ve got load balancing and lack-of-revenue issues as well.
Unplanned operational downtime is a big use case. We’re also starting to see this more and more across areas such as manufacturing, retail, and telco. SDP is helping organizations that are moving more and more of their data management and data processing to the edge. We see SDP helping organizations move beyond just managing that data but actually trying to monetize that data at the edge.
RTInsights: What is the best way to get started?
Schmarzo: I’m a really big believer that if you don’t understand the use case, if you don’t understand the objectives you’re trying to achieve, if you don’t know the KPIs and metrics against what you’re going to measure the effectiveness of that use case, if you don’t know the desired outcomes, if you’ve not brought together and aligned the different stakeholders who are involved in that use case, then you are likely to build a data architecture and a data management strategy and AI / ML models that don’t deliver what you want.
So, how do we make certain that customers are spending their money in the most intelligent, most frugal way? Well, they have to go through a process to identify, validate, value, and prioritize the different use cases at the edge and then build a use-case roadmap to build out their edge data management, data science, and data monetization capabilities.
I like to steal from Stephen Covey, author of ‘The 7 Habits of Highly Effective People’, “Begin with an end in mind.” That is exactly what we’re saying. Understand what you’re trying to do. And that’s going to drive your architecture, data management capabilities, instrumentation strategy, UI strategy, and how you’re going to deliver the insights to your constituents, so it’s actionable. It drives everything. Again, broken record, start with the use cases.
And let me throw one thing in here too. And while that may sound easy, here’s a challenge organizations have about use cases. First off, organizations don’t fail because of a lack of use cases. They fail because they have too many.
So, you need a thoughtful process to go through and drive organizational alignment and consensus on the use-case roadmap because these kinds of projects don’t fail because the technology doesn’t work. They fail because of passive-aggressive behaviors in the organization, where you haven’t collaborated and heard the needs of everybody in the organization, and you haven’t factored that into the solution. So, you deliver a solution for 90% of your customer base, but it’s that 10% that’s going to get you.







