











Cognitive computing, which seeks to simulate human thought and reasoning in real-time, could be considered the ultimate goal of information technology, and IBM’s Watson supercomputer has demonstrated that this goal can indeed be achieved with existing technology. But the question remains: When will cognitive computing become practical and affordable for most organizations?
The Graphics Processing Unit, with its ability to perform massively parallel deep analyses in real time, constitutes the breakthrough advance needed to usher in the Cognitive Era of computing.
The power of parallel processing
The foundation for affordable cognitive computing already exists based on steady advances in CPU, memory, storage and networking technologies. Major changes in price/performance of data analytics occurred with the advent of solid state storage and more affordable random access memory (RAM). For very large data sets, performance can be accelerated using RAM or flash cache, and/or solid state drives (SSDs). And the ability to configure servers with terabytes of RAM now makes in-memory databases increasingly common.
These changes have shifted the performance bottleneck from input/output to processing. To address the need for faster processing at scale, CPUs now contain as many as 32 cores. But even the use of multi-core CPUs deployed in large clusters of servers makes cognitive computing and other sophisticated analytical applications unaffordable for all but a few organizations.
The most cost-effective way to address this performance bottleneck today is the Graphics Processing Unit. GPUs are capable of processing data up to 100 times faster than configurations containing CPUs alone. The reason for such a dramatic improvement is their massively parallel processing capabilities, with some GPUs containing nearly 5,000 cores—over 100 times more than the 16-32 cores found in today’s most powerful CPUs. The GPU’s small, efficient cores are also better suited to performing similar, repeated instructions in parallel, making it ideal for accelerating the processing-intensive workloads that characterize cognitive computing.
As the name implies, the GPU was initially designed to process graphics. The first-generation GPU was installed on a separate card with its own memory (video RAM) as the interface to the PC’s monitor. The configuration was especially popular with gamers who wanted superior real-time graphics. Over time, both the processing power and the programmability of the GPU advanced, making it suitable for additional applications.
GPU architectures designed for high-performance computing applications were initially categorized as General-Purpose GPUs. But the rather awkward GPGPU moniker soon fell out of favor once the industry came to realize that both graphics and data analysis applications share the same fundamental requirement for fast floating point processing.
Future generations of these fully programmable GPUs increased performance in two ways: more cores and faster I/O with the host server’s CPU and memory. For example, NVIDIA®’s K80 GPU contains 4,992 cores. The typical GPU accelerator card today utilizes the PCI Express bus with a bi-directional bandwidth of 32 Gigabytes per second (GB/s) for a 16 lane PCIe interconnect. While this throughput is adequate for many applications, others stand to benefit from NVIDIA’s NVLink technology that provides five times the bandwidth (160 GB/s) between the CPU and GPU, and among GPUs.
Within the latest generation of GPU cards, the memory bandwidth is significantly higher at rates up to 732 GB/s. Compare this bandwidth to the 68 GB/s in a Xeon E5 CPU—just over twice that of a PCIe x16 bus. The combination of such fast I/O serving several thousand cores enables a GPU card equipped with 16 GB of memory to achieve single-precision performance of over 9 TeraFLOPS (floating point operations per second).
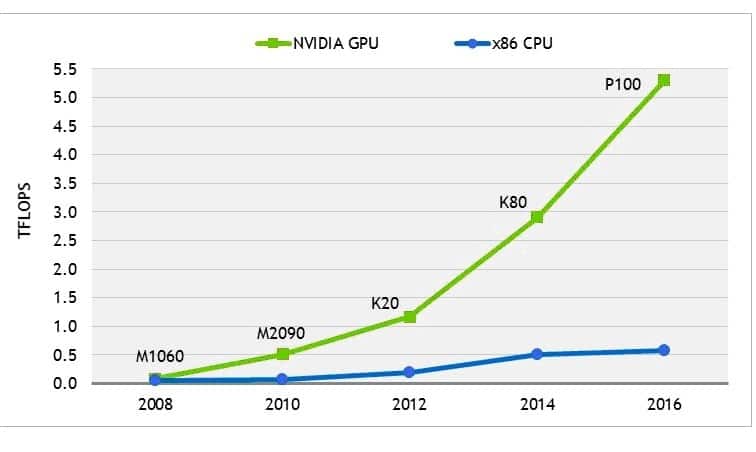 The latest generation of GPUs from NVIDIA contain upwards of 5,000 cores and deliver double-precision processing performance of 5 TeraFLOPS. Note also the relatively minor performance improvement over time for multi-core x86 CPUs, and how it is now flattening. (Source: NVIDIA)
The latest generation of GPUs from NVIDIA contain upwards of 5,000 cores and deliver double-precision processing performance of 5 TeraFLOPS. Note also the relatively minor performance improvement over time for multi-core x86 CPUs, and how it is now flattening. (Source: NVIDIA)
Scaling performance more affordably
The relatively small amount of memory on a GPU card compared to the hundreds of GB or few TB now supported in servers has led some to believe that GPU acceleration is limited to “small data” applications. But that belief ignores two practices common in cognitive computing and other big data applications.
The first is that it is rarely necessary to process an entire data set at once to achieve the desired results. For machine learning, for example, the training data can be streamed from memory or storage as needed. Live streams of data coming from the Internet of Things (IoT) or other applications, such as Kafka or Spark, can also be ingested in a similar, continuous manner.
The second practice is the ability to scale GPU-accelerated configurations both up and out. Multiple GPU cards can be placed in a single server, and multiple servers can be configured in clusters. Such scaling results in more cores and more memory all working simultaneously and massively in parallel to process data at unprecedented speed. The only real limit to potential processing power of GPU acceleration is, therefore, the budget.
But whatever the available budget, a GPU-accelerated configuration will always be able to deliver more FLOPS per dollar. CPUs are expensive—far more expensive than GPUs. So whether in a single server or a cluster, the GPU delivers a clear and potentially substantial price/performance advantage.
One study, for example, showed that a GPU-accelerated Spark cluster can achieve up to a 20-fold increase in performance while reducing power consumption by up to 95 percent. And although no comparison was performed, another example of impressive price/performance can be found in a two-node cluster that was able to query a database of 15 billion Tweets and render a visualization in less than a second. Each server was equipped with two 12-core Xeon E5 processors running at 2.6 GHz and two NVIDIA K80 cards for a total of four CPUs and four GPUs.
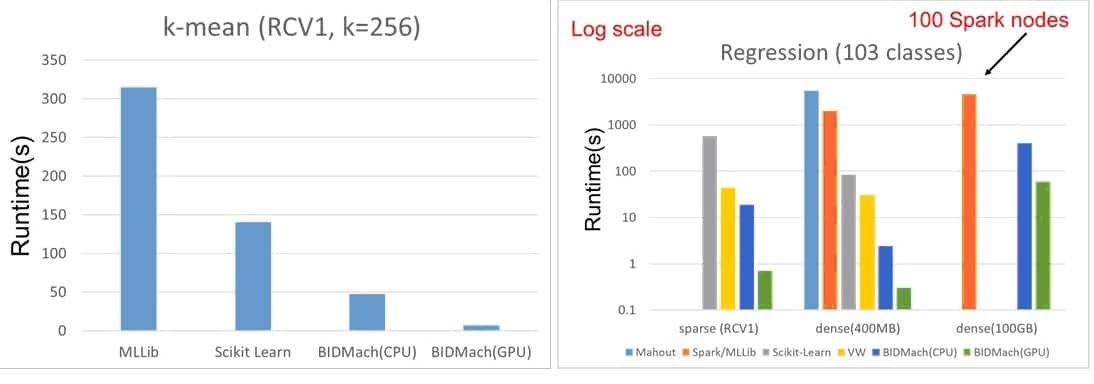
GPU-accelerated BIDMach offers a substantial performance improvement for k-mean and logistic regressions over other alternatives. For multi-model regressions, BIDMach on a single GPU-accelerated server can outperform Spark on a 100-node CPU-only cluster by a factor of 50 or more. (Source: NVIDIA)
The role of GPUs in cognitive computing
If cognitive computing is not real-time, it’s not really cognitive computing. After all, without the ability to chime in on Jeopardy! before its opponents did (sometimes even before the answer was read fully), Watson could not have even scored a single point, let alone win. And the most cost-effective way to make cognitive computing real-time today is to use GPU acceleration.
Cognitive computing involves a variety of analytical processes, including artificial intelligence, business intelligence, machine learning, expert systems, natural language processing and pattern recognition. Every one of these processes can be accelerated using GPUs. In fact, its thousands of small, efficient cores make GPUs particularly well-suited to parallel processing of the repeated similar instructions found in virtually all of these compute-intensive workloads.
Cognitive computing servers and clusters can be scaled up and/or out as needed to deliver whatever real-time performance might be required—from sub-second to a few minutes. Performance can be further improved by using algorithms and libraries optimized for GPUs. Most existing libraries achieve better performance when executed in a GPU, and can deliver far better performance when optimized to take advantage of the GPU’s massive parallel processing. In one test, for example, a single server equipped with a single GPU running a GPU-optimized version of BIDMach from the University of California at Berkeley was able to out-perform a CPU-only cluster containing one hundred nodes.
Given their performance and price/performance advantages, entire applications, such as databases, are also now being optimized to take advantage of the GPU’s parallel processing. Such databases are able to ingest and analyze high-volume, high-velocity streaming data on clusters one-tenth the size of CPU-only clusters.
Getting started
By breaking through the cost and other barriers that remain to achieving performance on the scale of a Watson supercomputer, GPU acceleration will help usher in the Cognitive Era of computing by making it affordable for many, if not most, organizations. And the availability of GPUs in the cloud make it even more affordable and easier than ever to get started.
As of this writing, Amazon and Nimbix have begun deploying GPUs, Microsoft’s offering is in preview, and Google will soon equip its Cloud Platform with GPUs for its Google Compute Engine and Google Cloud Machine Learning services.
Such pervasive availability of GPU acceleration in the public cloud is welcomed news for those organizations that are finding it difficult to implement GPUs in their own data centers. But adding GPU acceleration to a private cloud is now as simple as installing a GPU PCIe card, and optionally NVLink, in a server.
As with anything new, begin with a pilot to gain familiarity with the technology and assess its potential. Run your own benchmark for an existing on-line transaction processing or analytics processing application to experience first-hand the pure processing power of the GPU. You should then be able to appreciate how previously unimaginable real-time cognitive computing applications are about to become real-world.






