











When training a machine learning or AI model, typically the main goal is to make the most accurate prediction possible. Data scientists and machine learning engineers will transform their data in myriad ways and tweak algorithms in any way possible to bring that accuracy score as close to 100 percent as possible, which can unintentionally lead to a model that is difficult to interpret or creates ethical quandaries.
Considering the increasing awareness and consequences of faulty AI, explainable AI is going to be “one of the seminal issues that’s going to be facing data science over the next ten years,” Josh Poduska, Chief Data Scientist at Domino Data Lab noted during his talk at the recent virtual Open Data Science Conference (ODSC) East.
What is Explainable AI?
Explainable AI, or xAI, is the concept of understanding what is happening “under the hood” of AI models and not just taking the most accurate model and blindly trusting its results.
It is important because machine learning models, and in particular neural networks, have a reputation for being “black boxes,” where we do not really know how the algorithm came up with its prediction. All we know is how well it performed.
Models that are not easily explainable or interpretable can lead to some of the following problems:
- Models that are not understood by the end user could be used inappropriately or, in fact, could be wrong altogether.
- Ethical issues that arise in models that have some bias towards or against certain groups of people.
- Customers may require models that are interpretable, otherwise they may not end up using them at all.
Furthermore, there are recent regulations, and potentially new ones in the future, that may require models, at least in certain contexts, to be explainable. As Poduska explains, GDPR gives customers the right to understand why a model gave a certain outcome. For example, if a banking customer’s loan application was rejected, that customer has a right to know what contributed to this model result.
See also: Act Now to Prevent Regulatory Derailment of the AI Boom
So, how do we address these issues and create AI models that are more easily interpretable? The first issue is to understand how one wants to apply the model. Poduska explains that there is a balance between “global” versus “local” explainability.
Global interpretability refers to understanding generally the resulting predictions from different examples that you feed your model. In other words, if an online store is trying to predict who will buy a certain item, a model may find that people within a certain age range who have bought a similar item in the past will purchase that item.
In the case of local interpretability, one is trying to understand how the model came up with its result for one particular input example. In other words, how much does age versus purchase history affect the prediction of one person’s future buying habits?
Techniques for Understanding AI Reasoning
One standard option that has been around for a while is the concept of feature importance, which is often examined in training decision tree models, such as a random forest. However, there are issues with this method.
A more sophisticated option is called SHAP (SHapley Additive exPlanations). The basic idea behind this option is to hold one input feature of the model constant and randomize the other features, in order to estimate how that feature contributes to the prediction. The downside here is that this method can be very computationally expensive, especially for models with a large number of input features.
For understanding a model on a local level, LIME (Local Interpretable Model-agnostic Explanations) builds a simpler, linear model around each prediction of the original model in order to understand an individual prediction. This method is much faster, computationally, than SHAP, but is focused on local interpretability.
Going even further than the above solutions, some designers of machine learning algorithms are starting to reconstruct the underlying mathematics of these algorithms in order to give better interpretability and high accuracy simultaneously. One such algorithm is AddTree.
When training an AddTree model, one of the hyperparameters of the model is how interpretable the model should be. Depending on how this hyperparameter is set, the AddTree algorithm will train a decision tree model that is either weighted toward better explainability or toward higher accuracy.
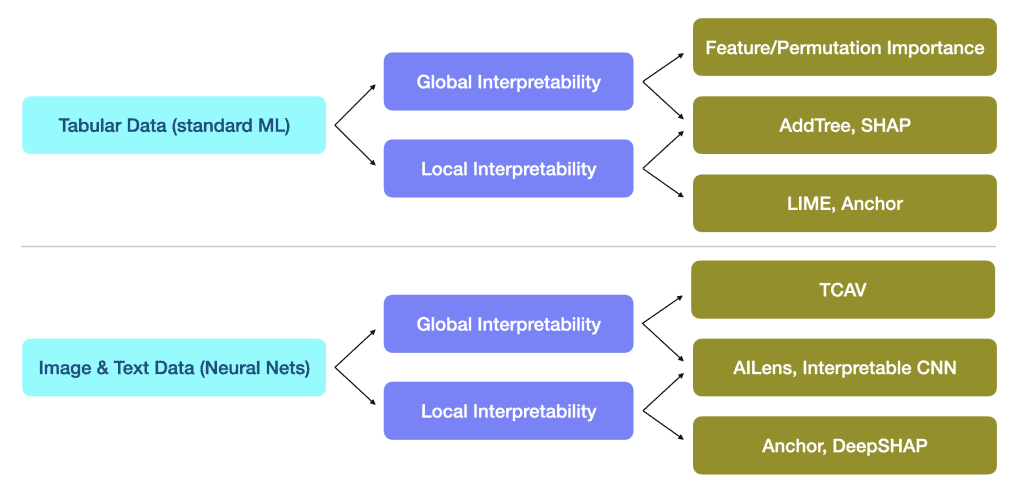
For deep neural networks, two options are TCAV and Interpretable CNNs. TCAV (Testing with Concept Activation Vectors) is focused on global interpretability, in particular showing how important different everyday concepts are for making different predictions. For example, how important is color in predicting whether an image is a cat or not?
Interpretable CNNs is a modification of Convolutional Neural Networks where the algorithm automatically forces each filter to represent a distinct part of an object in an image. For example, when training on images of a cat, a standard CNN may have a layer that includes different parts of a cat, whereas the Interpretable CNN has a layer that identifies just a cat’s head.
If your goal is to be able to better understand and explain an existing model, techniques like SHAP and LIME are good options. However, as the demands for more explainable AI continue to increase, even more models will be built in the coming years that have interpretability baked into the algorithm itself, Poduska predicts.
Poduska has a preview of some of these techniques. These new algorithms will make it easier for all machine learning practitioners to produce explainable models that will hopefully make businesses, customers, and governments more comfortable with the ever-increasing reach of AI.






