










Set up your analytical teams for success by arming them with open source libraries running on an open source platform. This will future-proof against lock-in by any single AI tool or cloud vendor. But doing so means keeping up with up fast-moving developments, so your enterprise can quickly adopt promising technology as it emerges.
Part 1 looked at the rapid growth of deep neural networks, and three ways for enterprises to join the AI revolution. Part 2 provides a map and list of the most popular deep learning tools.
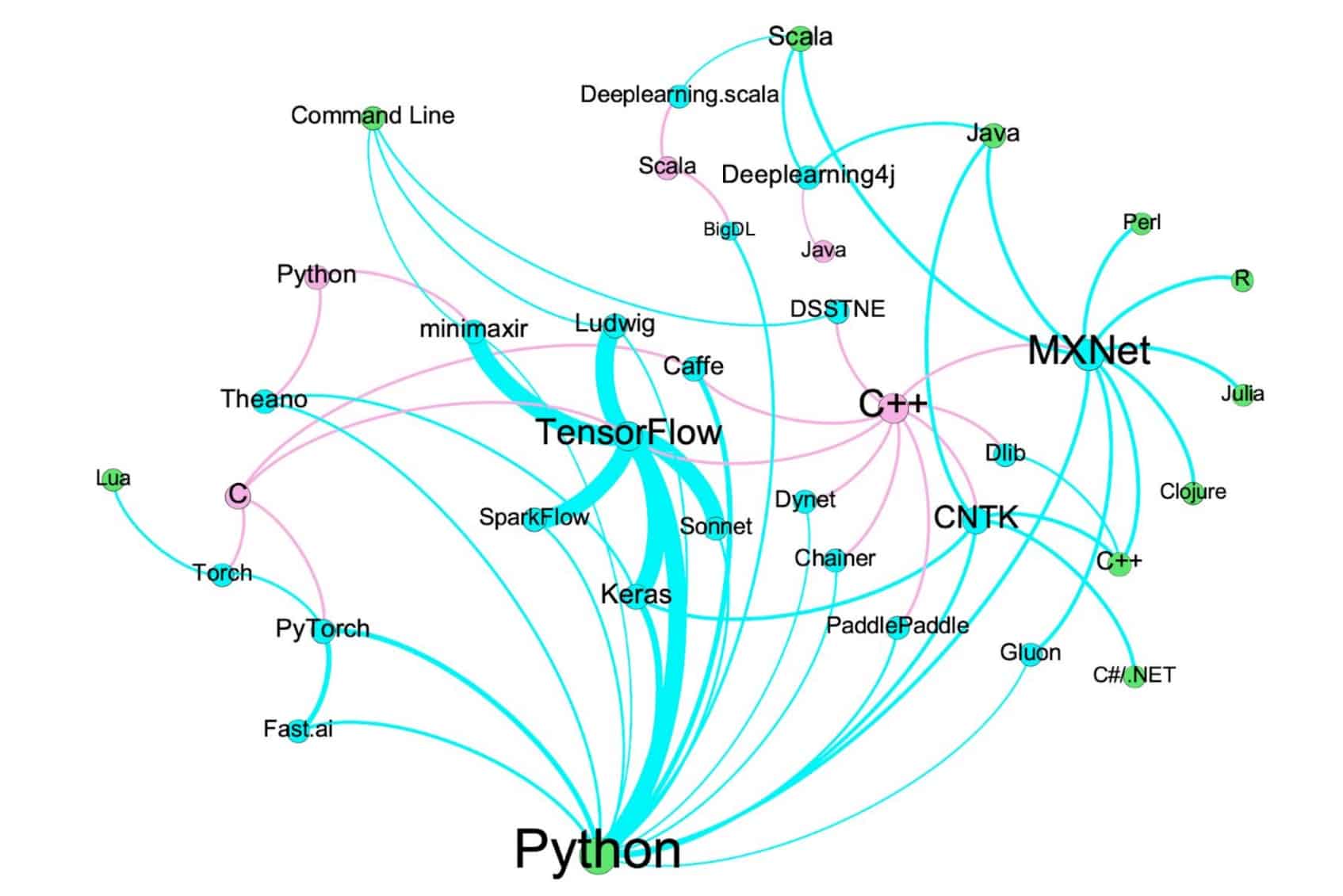
Here’s a simple summary of open source tools for deep learning. The network has three types of nodes. Deep learning tools are colored blue. The code bases used to develop those tools are colored pink. The APIs that data scientists leverage when using those tools are in green.
code base → deep learning tool → API
The edges are colored based on their source node. All pink edges have the same default width. Blue edge widths correspond to GitHub stars (a measure of popularity) for the deep learning tool form which the blue edge originates. The size of every node and the font size of its label correspond to node degree (the number of connections to that node).
A Network of Open Source Deep Learning Tools

This network graph was created using Gephi. You can access all the raw materials here.
You can see that C++ lends itself nicely to creating powerful deep learning tools. It’s also clear that once a tool becomes popular, it spawns others. PyTorch and Tensor Flow and both good examples. The latter is the most popular and has produced the most offspring tools. The graph also reveals the extensive work that went into API integration with MXNet and CNTK.
But when it comes to APIs, all roads lead to Python – the clear API of choice for deep learning tool developers. Given these trends, and announcements around TensorFlow 2.0 that bring it parity with PyTorch, expect more tools spinning off from TensorFlow with Python APIs. These tools will do what Ludwig, minimaxir, and Fast.ai (an offspring of PyTorch) have done: Take deep learning best practices and encapsulate them in new APIs to allow data scientists to accelerate model research.
Below is the full list tools shown in the graph, sorted by GitHub stars.
A List of Popular Open Source Deep Learning Tools
| API Name/GitHubLink | Description | GitHub Stars |
| TensorFlow | TensorFlow is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications. TensorFlow includes an implementation of the Keras API (in the tf.keras module) with TensorFlow-specific enhancements. | 125,536 |
| Keras | Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result with the least possible delay is key to doing good research. | 40,158 |
| Caffe | Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR)/The Berkeley Vision and Learning Center (BVLC) and community contributors. Caffe sets itself apart from other deep learning frameworks through its modularity and the fact that it is designed for scale. It has been described as an “un-framework” due to its flexibility and modularity. | 27,804 |
| PyTorch | Tensors and Dynamic neural networks in Python with strong GPU acceleration. Next to the GPU acceleration and the efficient usages of memory, the main driver behind the popularity of PyTorch is the use of dynamic computational graphs. | 26,913 |
| MXNet | Lightweight, Portable, Flexible Distributed/Mobile Deep Learning with Dynamic, Mutation-aware Dataflow Dep Scheduler; for Python, R, Julia, Scala, Go, Javascript and more. | 16,688 |
| CNTK | The Microsoft Cognitive Toolkit (CNTK) is a unified deep learning toolkit that describes neural networks as a series of computational steps via a directed graph. | 16,009 |
| Fast.ai | The fastai library simplifies training fast and accurate neural nets using modern best practices. The library is based on research into deep learning best practices undertaken at fast.ai, and includes “out of the box” support for vision, text, tabular, and collab (collaborative filtering) models. | 13,121 |
| Deeplearning4j | Eclipse Deeplearning4j, which is distinguished from other frameworks in its API languages, intent and integrations. DL4J is a JVM-based, industry-focused, commercially supported, distributed deep-learning framework that solves problems involving massive amounts of data in a reasonable amount of time. It integrates with Kafka, Hadoop and Spark using an arbitrary number of GPUs or CPUs, and it has a number you can call if anything breaks. | 10,626 |
| Theano | Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. It can use GPUs and perform efficient symbolic differentiation. | 8,739 |
| PaddlePaddle | PaddlePaddle (PArallel Distributed Deep Learning) is an easy-to-use, efficient, flexible and scalable deep learning platform, which is originally developed by Baidu scientists and engineers for the purpose of applying deep learning to many products at Baidu. | 8,440 |
| Torch | Torch is a scientific computing framework with wide support for machine learning algorithms that puts GPUs first. It is easy to use and efficient, thanks to an easy and fast scripting language, LuaJIT, and an underlying C/CUDA implementation. | 8,260 |
| Sonnet | Sonnet is a library built on top of TensorFlow for building complex neural networks. | 7,477 |
| Dlib | Dlib is a modern C++ toolkit containing machine learning algorithms and tools for creating complex software in C++ to solve real world problems. | 7,012 |
| Chainer | Chainer is a Python-based deep learning framework aiming at flexibility. It provides automatic differentiation APIs based on the define-by-run approach (a.k.a. dynamic computational graphs) as well as object-oriented high-level APIs to build and train neural networks. | 4,706 |
| Ludwig | Ludwig is a toolbox built on top of TensorFlow that allows to train and test deep learning models without the need to write code. All you need to provide is a CSV file containing your data, a list of columns to use as inputs, and a list of columns to use as outputs, Ludwig will do the rest. | 4,353 |
| DSSTNE | DSSTNE (pronounced “Destiny”) is an open source software library for training and deploying recommendation models with sparse inputs, fully connected hidden layers, and sparse outputs. | 4.316 |
| BigDL | BigDL is a distributed deep learning library for Apache Spark; with BigDL, users can write their deep learning applications as standard Spark programs, which can directly run on top of existing Spark or Hadoop clusters. | 2209 |
| Dynet | DyNet is a neural network library developed by Carnegie Mellon University and many others. It is written in C++ (with bindings in Python) and is designed to be efficient when run on either CPU or GPU, and to work well with networks that have dynamic structures that change for every training instance. | 2748 |
| Gluon | The Gluon API specification is an effort to improve speed, flexibility, and accessibility of deep learning technology for all developers, regardless of their deep learning framework of choice. | 2288 |
| minimaxir | minimaxir offers a zero code/model definition interface to getting an optimized model and data transformation pipeline in multiple popular ML/DL frameworks, with minimal Python dependencies (pandas + scikit-learn + your framework of choice). | 1309 |
| Deeplearning.scala | DeepLearning.scala is a simple library for creating complex neural networks from object-oriented and functional programming constructs. | 677 |
| SparkFlow | This is an implementation of Tensorflow on Spark. The goal of this library is to provide a simple, understandable interface in using Tensorflow on Spark. With SparkFlow, you can easily integrate your deep learning model with a ML Spark Pipeline. | 220 |
The AI revolution is here to stay. Organizations can ride the wave – or be crushed in the surf.
Start by upskilling your analytical team and augment it with a deep learning expert. Leaders must know which use cases in their industry are being transformed by deep learning. It’s also important to incorporate ethical, biased-free modeling practices and investing in model explainability. Finally, adopting an open source, open platform approach to data science will help you navigate the next exciting decade of your AI journey.
See Also: 3 Ways CIOs Can Shepherd Machine Learning and AI Adoption in the Enterprise







