











Consumer-facing websites, applications, and business systems often require instant data processing and analysis. Lose a minute on a data bottleneck and you lose a customer — and revenue. To solve such problems, companies have turned to in-memory database technologies, which are orders of magnitude faster than disk storage. Falling costs for RAM only make the in-memory attraction stronger.
An in-memory, relational database can have inherent limitations, however. Consider data on a node (server) with 256 MB of RAM. A relational in-memory database is designed to scale up (to add more resources to an existing node). But an in-memory data grid is designed to scale out — to add more nodes. For web and mobile apps dealing with concurrent processes, complex queries, or more transactions — for instance from a spike in network traffic — the scale-up architecture can reach a breaking point, according to Forrester’s third-quarter report on IMDGs.
For scenarios that demand “performance, scalability, and reliability” and can manage “multiple tens of terabytes” across tens or hundreds of servers, “scaleout architectures are better supported by IMDGs than by other forms of in-memory computing technology,” Gartner states in a report.
The firm lists use cases for data grids in transaction processing, e-commerce, online gaming, and mobile banking, but “adoption for analytics is growing fast” in areas such as fraud detection, operations monitoring, and recommendation engines.
Forrester further explains that in-memory data grids can be used for caching quickly changing data to overcome bottlenecks; acting as a primary data store for applications; as a NoSQL database at in-memory speed; or as a real-time data “fabric” to access information in multiple legacy systems (master data management).
Use case: Fast IoT data and backup
Software AG has described how Terracotta BigMemory, their data grid platform, helped process diagnostic data from systems that support CERN’s Large Hadron Collider.

An in-memory data grid is used to support monitoring equipment for the Large Hadron Collider.
The LHC accelerates subatomic particles near the speed of light in a massive tunnel below Geneva in a quest to advance quantum physics. To monitor the LHC and other equipment, CERN created the C2MON (control and monitoring platform) which manages data from some 94,000 sensors. The project required data analysis in less than a second and fail-safe operation of C2MON.
The company stated that Terracotta made data available to multiple servers in C2MON and also supported an automatic failover between mirrored servers to prevent data loss and application disruption.
According to Forrester, a data grid replicates data to one or nodes, making the data available even if a node goes down. Data grids can also be configured to support wide-area network replication to copy data across data centers, so if a data center goes down, an application can seamlessly access data from another data center.
Risk analysis in a second
A chief benefit of data grids is that they enable “operational intelligence,” according to ScaleOut Software. State changes in data can be quickly analyzed with low latency, and alerts generated.
In a case study, ScaleOut describes a New York hedge fund that maintained thousands of long and short positions in equities. Although the company used an IMDG, it had to flush data to a relational database, which took 15 minutes. “Since investment markets can experience significant fluctuations in fifteen minutes, traders often need to eyeball market fluctuations. Unfortunately, this has proven to be difficult to scale across a large set of strategies,” ScaleOut stated.
To solve the problem, a ScaleOut server stores the hedging strategies in an IMDG. The application uses parallel method invocation (PMI), which “eliminates the need for applications to explicitly code parallel computations and move data between servers at runtime,” ScaleOut states. Using 20 servers, analysis time was reduced to one second.
Here’s what the architecture looks like:
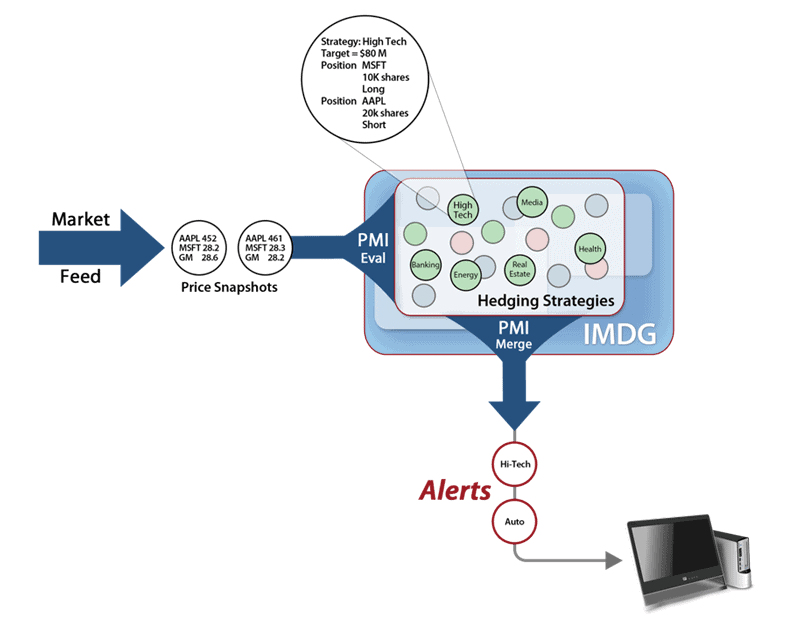
Image credit: ScaleOut Software
Software AG described a use case for its Terracotta platform in which a credit card company determined it couldn’t meet its one-second service-level agreement for identifying blacklisted credit cards approximately 0.3 percent of the time. That adds up when dealing with thousands of transactions every second, and it reportedly cost the company $10 million a year.
The company had kept a list of 7 million blacklisted card numbers and individuals in a disk-bound Oracle database, which was slow to access. Furthermore, a feature known as Java garbage collection, which deletes unused objects in heap memory, caused “extended, unpredictable pauses.”
Related: Real-time data use cases for financial services
Digital sales, e-commerce
According to GridGain, their in-memory data grid supported in-memory caching, distributed computing, and streaming for a network of influencers and retail sales channels managed by Experticity.
Experticity, based in Salt Lake City, helps 650 lifestyle and consumer brands make sales by targeting influencers through product seeding and digital certification. An influencer might run a website on hiking gear, for instance, or be a retail sales associate. Experticity aims to turn these influencers into brand advocates. A profile gives visibility into interests, experience, interactions, and purchases of the influencers, and it helps Experticity’s partners with content targeting and promotion efforts.
When an influencer triggers an event, “such as downloading a piece of content, taking a training course, buying discounted merchandise, or rating their product preferences, this data is sent directly to the GridGain In-Memory Data Fabric, where algorithms are run directly on the nodes of the grid,” the company stated.
To illustrate how a data grid can work with other database system in an e-commerce application, ScaleOut Software uses the example of a recommendation engine. A customer’s history might be stored on disk, say in a customer-relationship management system. When a customer starts browsing, that history can be read into the in-memory data grid.
An analytics engine then crunches session data and customer history data to make real-time offers, as ScaleOut shows:
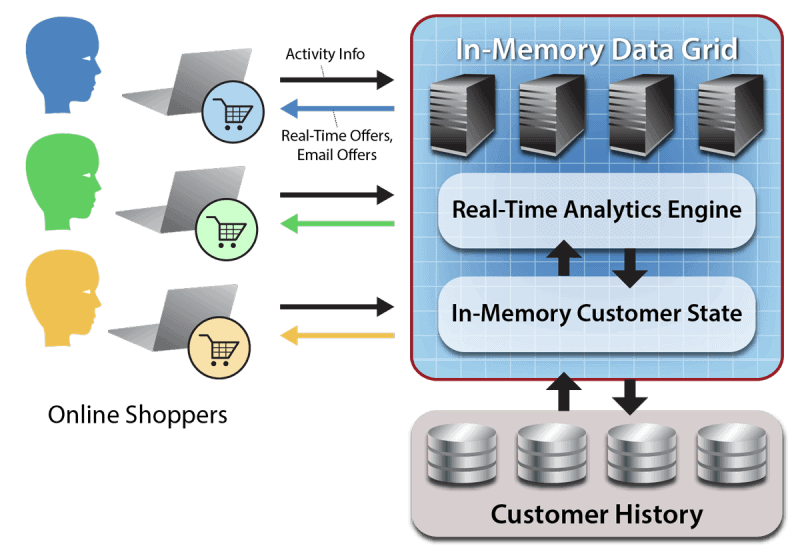
Image credit: ScaleOut Software
Related: real-time data use cases in e-commerce
Future of in-memory: a crowded field
The distinction between an in-memory database and data grid is fairly technical. Data grids tend to use key-value stores as embedded objects on a Java Virtual Machine, while in-memory databases are optimized for columnar storage. What’s faster supposedly depends on the use case. Oracle, for instance, which offers an in-memory database as well as its Coherence data grid, states that, for online analytics, “storing columns in-memory, in columnar format, speeds full-table scans orders of magnitude.”
Transaction processing is a different story. Oracle notes that online transactions have different access patterns than online analytical processing (OLAP). GridGain concurs, stating that transaction processing is much quicker on a data grid but for “OLAP workloads the picture is less obvious.”
In 2013, Gartner defined an IMDG as middleware that implements a scalable, NoSQL data store. Data grids acted–and still do–as turbochargers in a Big Data technology stack. But vendors are now adding persistence storage with an SQL subset, as well as integration with Hadoop MapReduce and Apache Spark. These integrations will blur the distinctions between in-memory data grids, databases, and event-stream processing platforms, Gartner says.
Related: What’s behind the attraction to Apache Spark
The firm further predicts that IoT requirements and scenarios involving HTAP—hybrid transaction/analytical processing—will likely emerge as drivers of future IMDG adoption. Some in-memory database vendors, however, are also strong in HTAP, according to Gartner, including IBM (the DB2 for z/OS product); MemSQL; Microsoft; SAP; and VoltDB (over half its customers use its platform for HTAP).
In addition to ScaleOut and GridGain, other dedicated IMDG vendors include Alachisoft, Hazelcast, and GigaSpaces Technologies. Larger companies such as Fujitsu, Hitachi, IBM, and Oracle also have IMDG products, as do companies such as TIBCO, Red Hat, Tmax Soft, and Pivotal.
Want more? Check out our most-read content:
White Paper: How to ‘Future-Proof’ a Streaming Analytics Platform
Research from Gartner: Real-Time Analytics with the Internet of Things
E-Book: How to Move to a Fast Data Architecture
The Value of Bringing Analytics to the Edge
Three Types of IoT Analytics: Approaches and Use Cases
Fast Data: Why Business and IT Are Now Inseparable
Liked this article? Share it with your colleagues!







